# 水平分库分表
介绍如何通过shardingjdbc实现水平分库,水平分表,数据库读写分离功能。
# 水平分库分表
要想实现数据库的水平分库,水平分表,读写分离功能,需要同时改造MySQL数据库以及Java项目,MySQL数据库需要实现主从复制(基于docker搭建mysql主从集群),读写分离(对mysql主从集群做读写分离)功能。而Java项目也需要改造,对于读写分离,需要代码层面判断是读操作还是写操作,对于不同的操作,使用不同的数据库。而对于水平分库分表,则需要人为判断数据需要在哪个库哪个表读写。
# ShardingJDBC介绍
ShardingJDBC是由当当网开源的一个轻量级的数据库分库分表,读写分离框架。利用该框架,我们可以很轻松的实现分布式系统的水平分库,水平分表,读写分离功能。
# SpringBoot+ShardingJDBC实现水平分库分表,读写分离
# 前期准备
我们以一个主从同步,读写分离架构的Mysql服务集群来演示ShardingJDBC的水平分库,水平分表,读写分离功能,因此需要预先搭建一个MySQL一主一从的服务集群,参见基于docker搭建mysql主从集群,对mysql主从集群做读写分离。
# 建库建表
在Mysql主节点上创建水平分库db_order1以及db_order2,在db_oder1以及db_order2中分别创建t_order_1以及t_order2。可以在从节点看到相同的库表同步到了从节点。

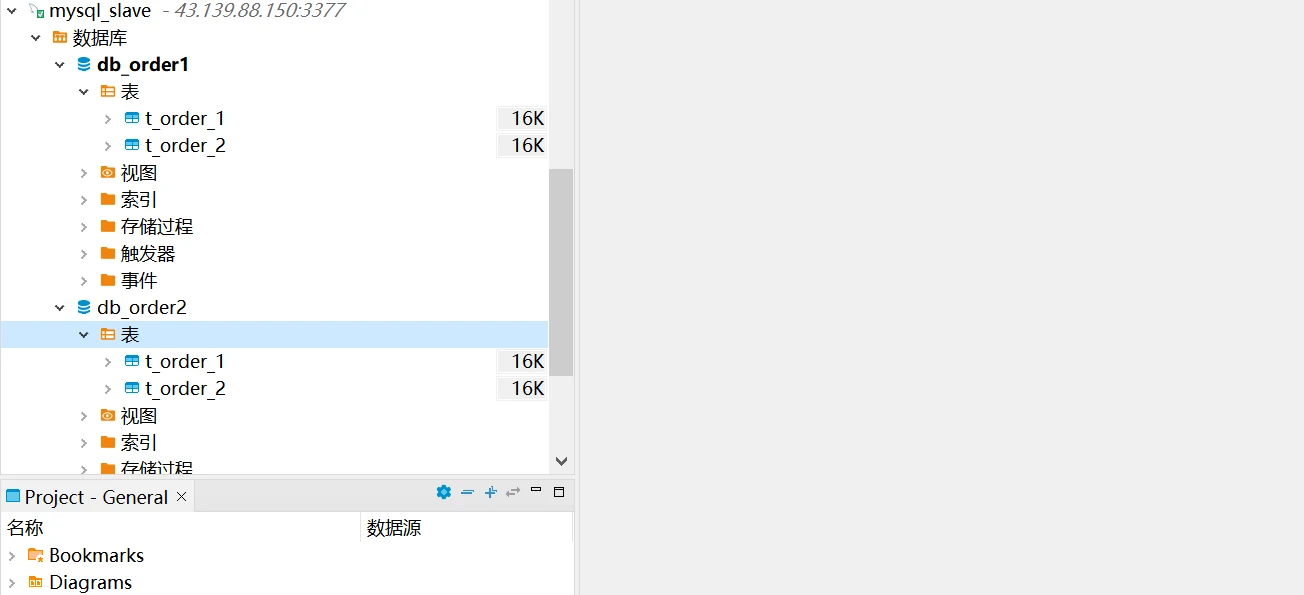
相关建库建表语句
CREATE DATABASE `db_order1`;
CREATE DATABASE `db_order2`;
-- db_order1.t_order_1 definition
CREATE TABLE `t_order_1` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10,2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- db_order1.t_order_2 definition
CREATE TABLE `t_order_2` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10,2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
# Java服务创建
需要创建springboot项目,引入shardingjdbc相关依赖,同时提供分库分表配置,在业务代码里实现分库分表操作(项目运行在jdk8+mysql5.7环境)。
# 依赖pom文件
在pom依赖文件里,我们需要引入springboot,mybatis,druid,mysql-connector,lombok依赖。
完整pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
</parent>
<groupId>com.howl</groupId>
<artifactId>sharding-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>sharding-jdbc</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.0.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.26</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.10</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>Central Repository</id>
<url>https://repo1.maven.org/maven2/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
# 配置文件修改
在配置文件里,我们需要配置shardingsphere数据源,读写分离策略,水平分库策略,水平分表策略,分布式主键生成策略。
application.yml
server:
port: 8082
spring:
application:
name: sharding-jdbc-simple-demo
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2,s1,s2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://43.139.88.150:3366/db_order1?useUnicode=true&useSSL=false
username: howl
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://43.139.88.150:3366/db_order2?useUnicode=true&useSSL=false
username: howl
password: 123456
s1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://43.139.88.150:3377/db_order1?useUnicode=true&useSSL=false
username: howl
password: 123456
s2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://43.139.88.150:3377/db_order2?useUnicode=true&useSSL=false
username: howl
password: 123456
sharding:
master-slave-rules:
ds1:
master-data-source-name: m1
slave-data-source-names: s1
ds2:
master-data-source-name: m2
slave-data-source-names: s2
tables:
t_order:
actualDataNodes: ds$->{1..2}.t_order_$->{1..2}
databaseStrategy:
inline:
shardingColumn: user_id
algorithm‐expression: m$->{user_id % 2 + 1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_$->{order_id % 2 + 1}
keyGenerator:
type: SNOWFLAKE
column: order_id
props:
sql:
show: true
mybatis:
configuration:
map-underscore-to-camel-case: true
logging:
level:
root: info
org.springframework.web: info
com.itheima.dbsharding: debug
druid.sql: debug
# 项目代码编写-Application入口
在应用入口,我们只需要使用@SpringBootApplication注解标记入口类即可。
应用入口
package com.dyh.shardingJdbc;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author howl-xu
* @version 1.0
* Create by 2024/3/22
*/
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
# 项目代码编写-Controller层代码编写
因为是demo项目,我们直接跳过service层,直接在controller层访问Mapper层。
controller层代码
package com.dyh.shardingJdbc.controller;
import com.dyh.shardingJdbc.entity.Order;
import com.dyh.shardingJdbc.entity.dto.InsertOrderDto;
import com.dyh.shardingJdbc.mapper.OrderMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.List;
import java.util.Map;
/**
* @author howl-xu
* @version 1.0
* Create by 2024/3/22
*/
@Slf4j
@RestController
@RequestMapping("/v1/sharding/")
public class OrderController {
@Resource
private OrderMapper orderMapper;
@PostMapping("/insert")
public void insertOrder(@RequestBody InsertOrderDto dto) {
orderMapper.insertOrder(dto.getPrice(),dto.getUserId(),dto.getStatus());
}
@PostMapping("/select")
public List<Order> selectOrder() {
List<Order> list = orderMapper.selectOrderbyIds();
return list;
}
}
# 项目代码编写-mapper及entity
mapper及entity的代码可以参考详情。
mapper及entity
package com.dyh.shardingJdbc.mapper;
import com.dyh.shardingJdbc.entity.Order;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Component;
import java.math.BigDecimal;
import java.util.List;
import java.util.Map;
/**
* 订单Mapper接口
*
* @author howl-xu
* @since 2024/3/22
**/
@Mapper
@Component
public interface OrderMapper {
/**
* 新增订单
*
* @param price 订单价格
* @param userId 用户id
* @param status 订单状态
* @return
*/
@Insert("insert into t_order(price,user_id,status) value(#{price},#{userId},#{status})")
int insertOrder(@Param("price") Double price, @Param("userId") Long userId,
@Param("status") String status);
/**
* 根据id列表查询多个订单
*
* @return
*/
@Select("select * from t_order")
List<Order> selectOrderbyIds();
}
package com.dyh.shardingJdbc.entity;
import java.math.BigDecimal;
import java.io.Serializable;
import lombok.Data;
import lombok.EqualsAndHashCode;
/**
* <p>
*
* </p>
*
* @author howl-xu
* @since 2024-03-22
*/
@Data
@EqualsAndHashCode(callSuper = false)
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
private Long orderId;
/**
* 订单价格
*/
private BigDecimal price;
/**
* 下单用户id
*/
private Long userId;
/**
* 订单状态
*/
private String status;
}
# 验证水平分库分表
测试demo的水平分库策略是根据用户的id做分库,如用户id为偶数,则分配到db_order1库中,如用户id为奇数,则分配到db_order2中。
测试demo的水平分表策略是根据order_id进行分表,订单id使用雪花算法生成,如订单id是偶数,则分配到t_order_1表,如是奇数,则分配到t_order_2表中。
我们使用一个用户id为偶数的用户做订单创建操作,如下:

查找数据库,这次雪花算法生成的id是一个奇数,数据写入到了db_order_1库的t_order_2表中。

# 验证读写分离
对创建的订单信息进行查询,如下:
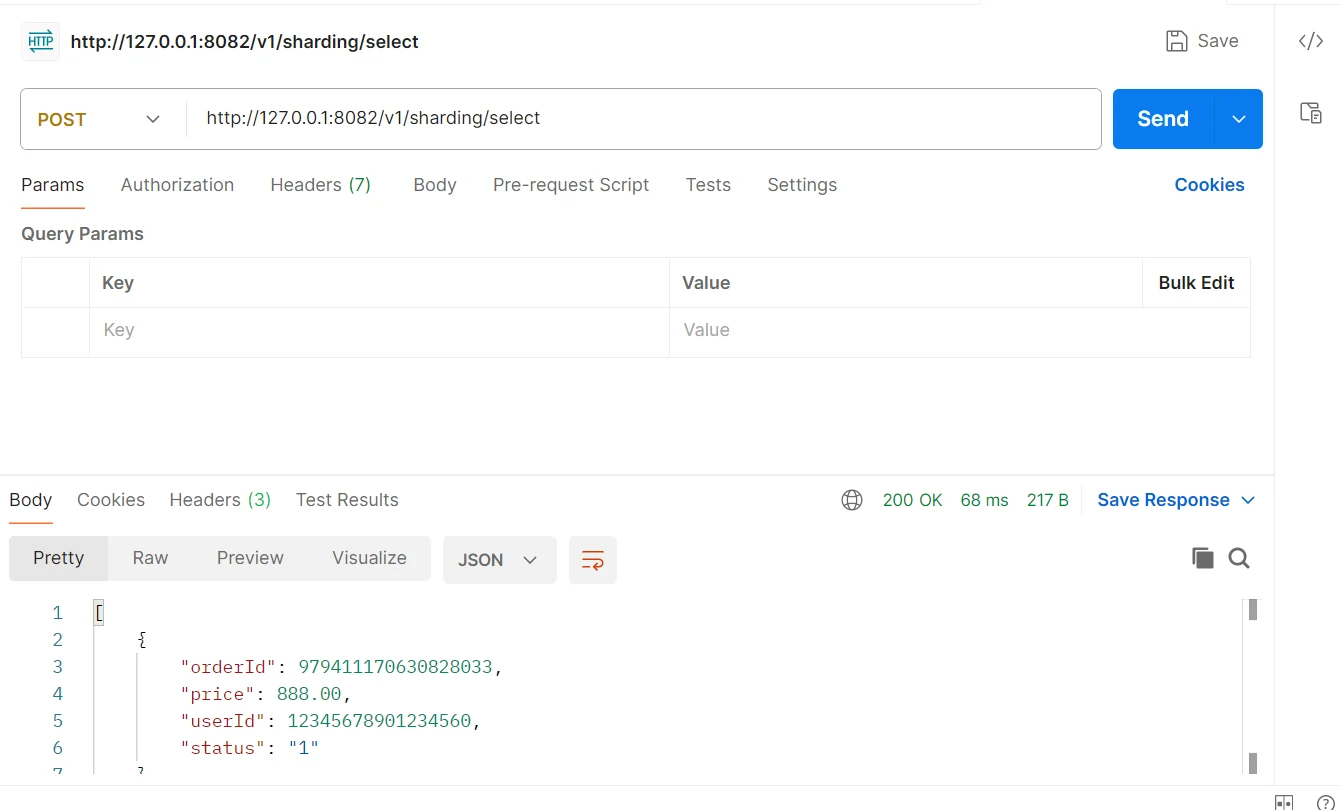
可以在项目的日志中看到,此时查询操作查询了s1,s2两个数据库的t_order_1以及t_order_2表。