# Kafka
Kafka是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道,流分析,数据采集和关键任务应用。
# Kafka基础架构
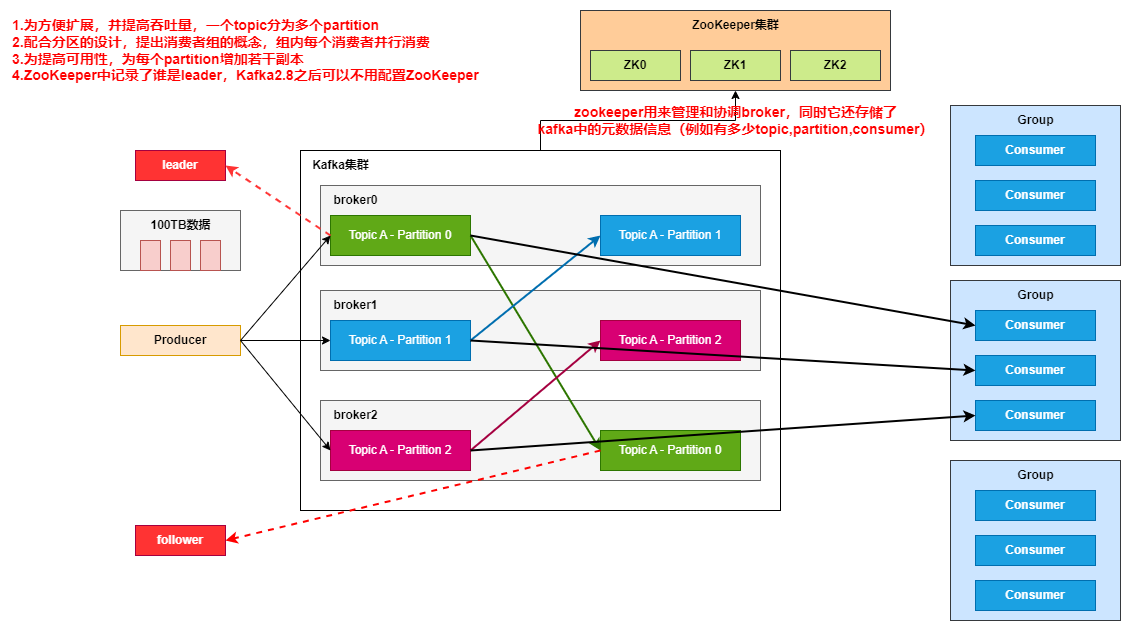
参考【尚硅谷】Kafka3.x教程(从入门到调优,深入全面) (opens new window)绘制
# Kafka中的相关概念
# broker
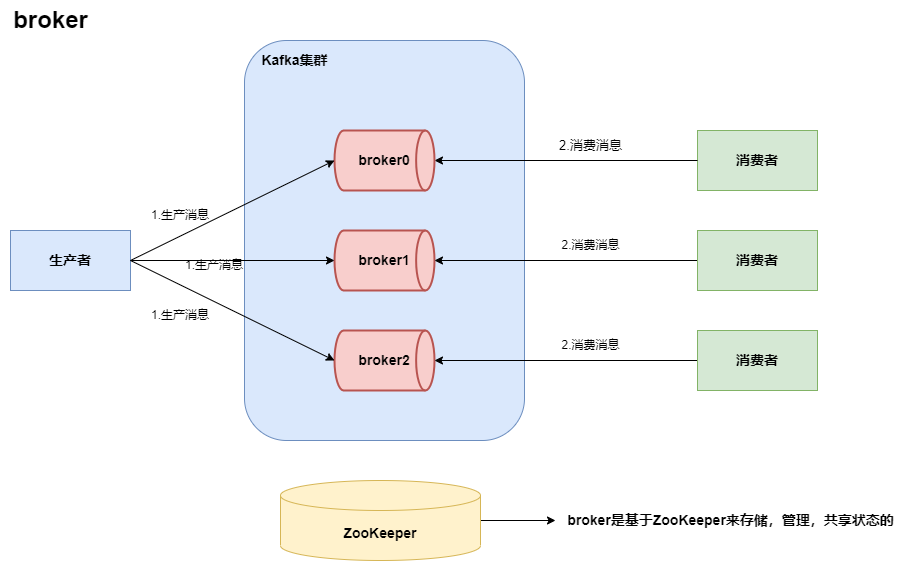
- 一个Kafka集群通常由多个broker组成,这样才能实现负载均衡以及容错。
- broker是无状态的,他们是由ZooKeeper来维护集群状态。
- 一个broker每秒可以处理数十万次读写,一个broker可以处理TB级别的消息而不影响性能。
# zookeeper
- zookeeper用来管理和协调broker,同时它还存储了kafka中的元数据信息(例如有多少topic,partition,consumer)。
- zookeeper服务主要用来通知生产者和消费者kafka集群中有新的broker加入,或者kafka集群中出现了故障的broker。
ps:kafka正在想办法将zookeeper剥离,后续会自己维护这些信息,而不是用zookeeper。
# 生产者
生产者负责将数据推送给broker的topic。
# 消费者
消费者负责从broker的topic里拉取数据,并对数据做业务逻辑的处理。
# topic-主题
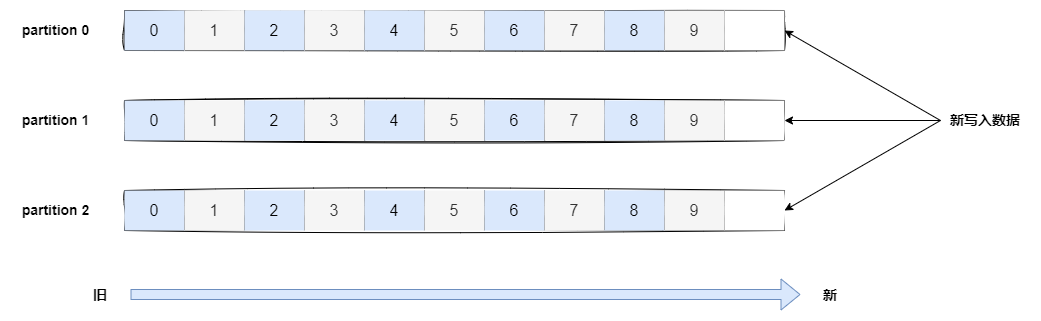
- Kafka中主题Topic是一个逻辑概念,用于生产者产生数据以及消费者消费数据。
- Kafka中主题必须要有唯一标识符,Kafka对主题的数量不做限制。
- 一旦生产者发送消息到主题中,这些消息就不允许再被修改了。
Kafka 中 Topic 被分成多个 Partition 分区。Topic 是一个逻辑概念,Partition 是最小的存储单元,掌握着一个 Topic 的部分数据。
# partition-分区
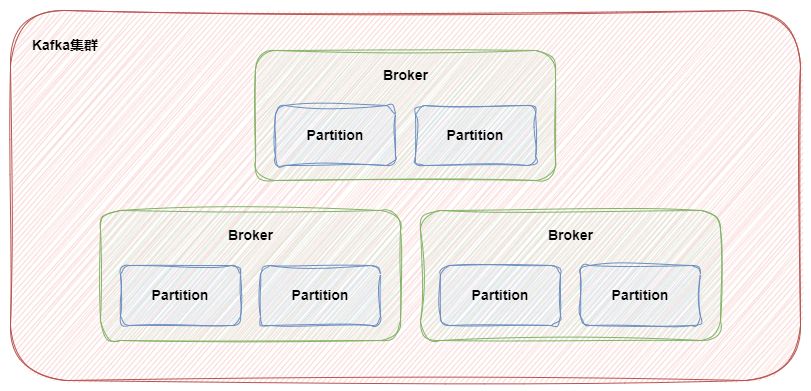
在kafka集群里,topic被划分为多个partition分区。
参考资料:细说 Kafka Partition 分区 (opens new window)
# 消费者组
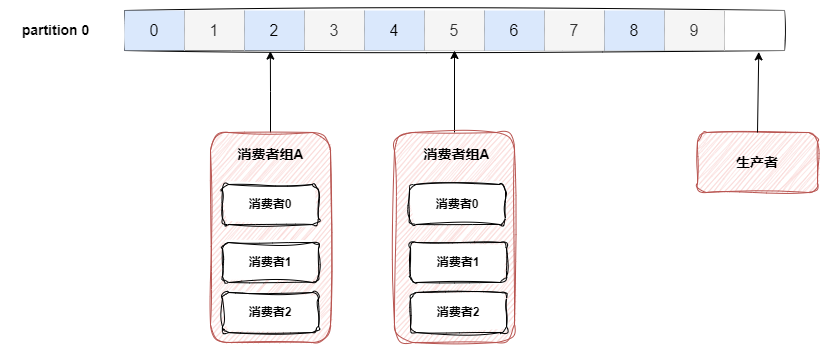
- 消费者组是Kafka提供的可扩展且具有容错性的消费者机制。
- 一个消费者组可以包含多个消费者。
- 一个消费者组有一个唯一的id(group id)。
- 组内的消费者一起消费主题的所有分区数据。
# replication-副本
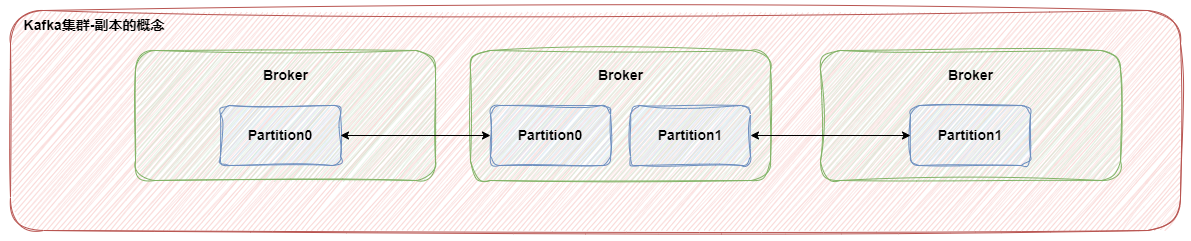
- 副本可以确保当服务器出现故障的时候,数据依然可用。
- 一般都会设置副本的个数大于1个。
# 偏移量offset
- offset记录着下一个将要发送给消费者的消息的序号。
- Kafka将offset信息存储再ZooKeeper中。
# Kafka生产者
# 生产者消息发送流程
在消息发送的过程中,涉及两个线程,分别是main线程和Sender线程,在main线程中创建了一个双端队列RecordAccumulator,main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息到Kafka Broker。

参考【尚硅谷】Kafka3.x教程(从入门到调优,深入全面) (opens new window)绘制
# 生产者分区
# Kafka分区的好处
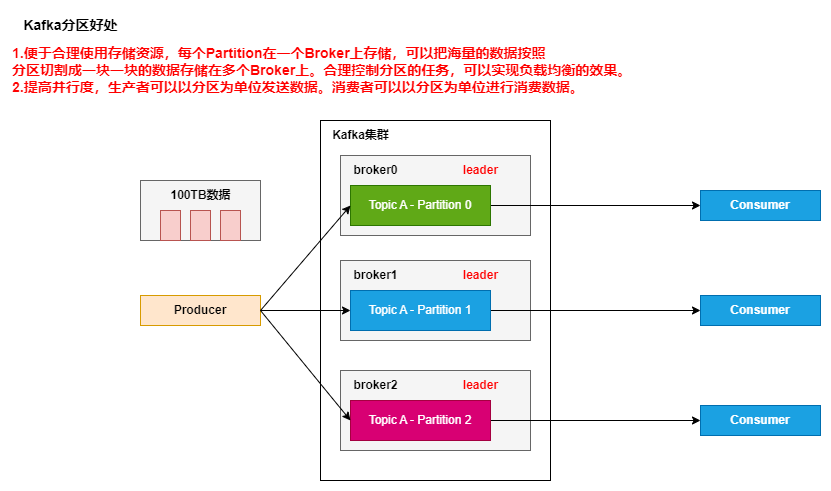
# Kafka分区策略
DefaultPartitioner 默认分区策略
如果消息中指定了分区,则使用它。
如果未指定分区但存在key,则根据序列化key使用murmur2哈希算法对分区数取模。
如果不存在分区或key,则会使用粘性分区策略。UniformStickyPartitioner 纯粹的粘性分区策略
会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,kafka再随机一个分区进行使用。RoundRobinPartitioner 轮替分区策略
如果消息中指定了分区,则使用它,如果未指定分区,则使用轮替的方式,将消息平均的分配到每个分区中。与key无关。
# 自定义分区
只要实现Partitioner接口并且重写partition()方法,我们也可以实现自己的自定义分区规则(推荐在Kfaka默认分区策略不满足业务场景的前提下使用)。
# Kafka Broker
# Broker工作原理
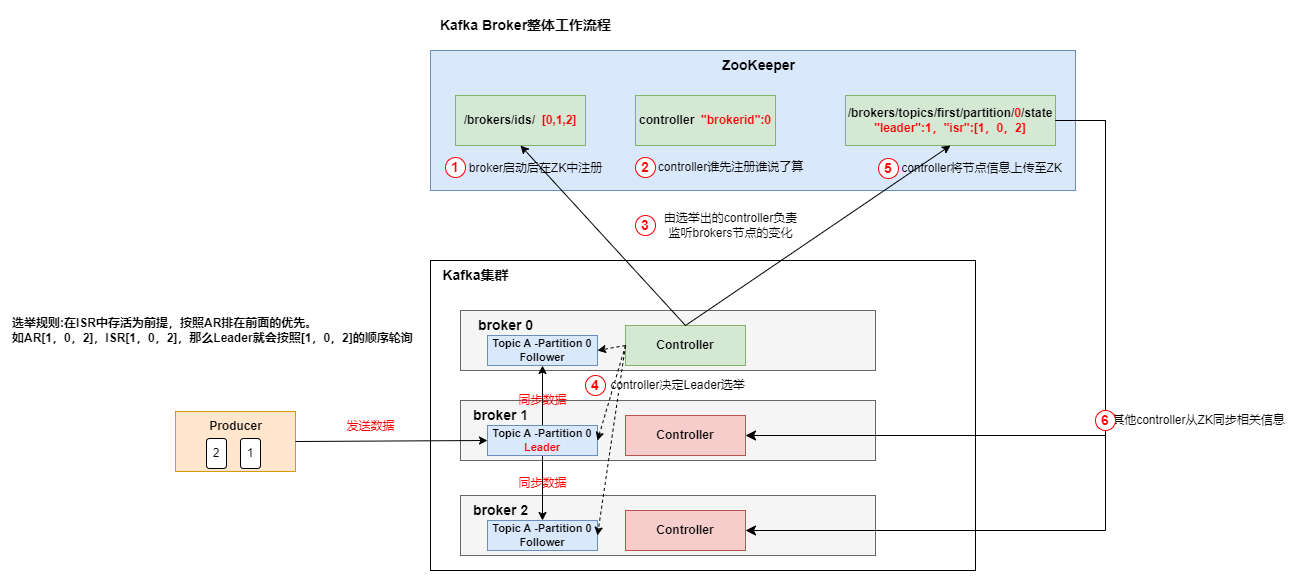
# Kafka文件存储
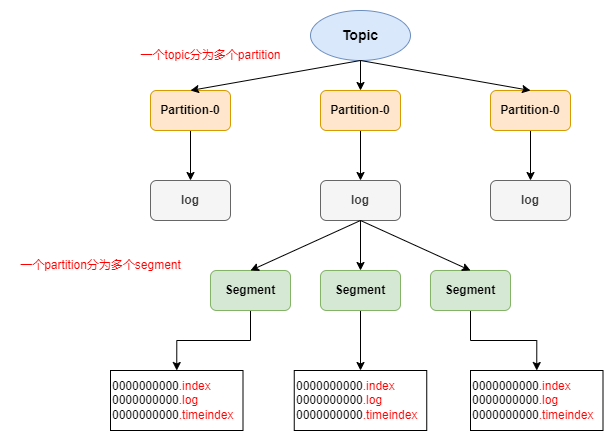
topic是逻辑上的概念,而partition是物理上的概念。每个partition对应一个log文件,该log文件中存储的是Producer产生的数据。Producer新产生的数据会一直追加到log文件的末端。为防止log文件过大导致数据定位效率下降,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment由".log文件,.index文件,.timeindex文件"等组成。
# Kafka消费方式
pull(拉)模式
消费者主动从broker中拉取数据,Kafka采取的是这种方式。缺点在于如果broker中没有数据,消费者可能会陷入循环中。push(推)模式
由broker推送数据到消费者方。这种方式如果多个消费方消费能力不一致的话没有办法使用。
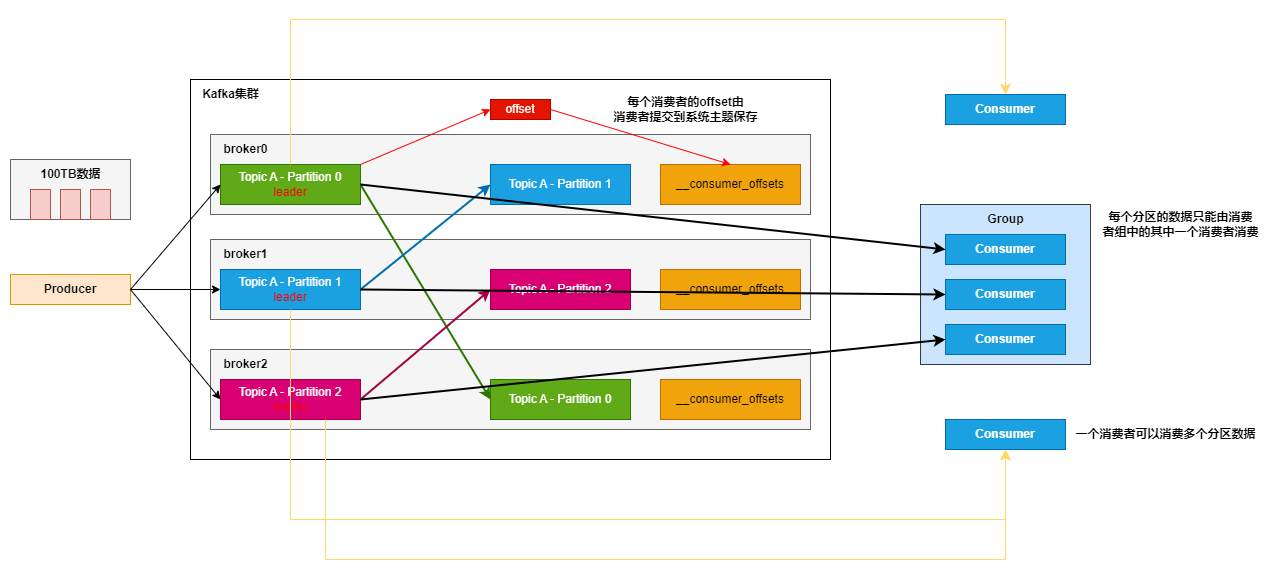
# Kafka消费者工作流程
# 单机环境部署及验证
# 单机环境搭建
1.访问kafka官网 (opens new window),点击download

2.点击下载kafka安装包,将安装包上传到服务器的/app目录下

3.使用tar指令解压缩安装包
4.使用如下指令启动zookeeper单节点服务
[root@VM-8-5-centos ~]# cd /app/kafka_2.13-3.8.0
[root@VM-8-5-centos kafka_2.13-3.8.0]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
[1] 1009163
[root@VM-8-5-centos kafka_2.13-3.8.0]# nohup: ignoring input and appending output to 'nohup.out'
5.验证zookeeper是否启动完成
[root@VM-8-5-centos kafka_2.13-3.8.0]# jps
# 这个服务对应zk
1009163 QuorumPeerMain
1009832 Jps
6.使用如下指令启动kafka单节点服务
[root@VM-8-5-centos kafka_2.13-3.8.0]# nohup bin/kafka-server-start.sh config/server.properties &
7.验证kafka是否启动完成
[root@VM-8-5-centos kafka_2.13-3.8.0]# jps
1032732 Jps
1009163 QuorumPeerMain
1032275 Kafka
# 创建topic
# 创建topic
[root@VM-8-5-centos kafka_2.13-3.8.0]# bin/kafka-topics.sh --create --topic tes t --bootstrap-server localhost:9092
Created topic test.
# 查看topic
[root@VM-8-5-centos kafka_2.13-3.8.0]# bin/kafka-topics.sh --describe --topic test --bootstrap-server localhost:9092
[2024-09-20 13:41:57,010] WARN [AdminClient clientId=adminclient-1] The DescribeTopicPartitions API is not supported, using Metadata API to describe topics. (org.apache.kafka.clients.admin.KafkaAdminClient)
Topic: test TopicId: Wp_21KQLQaeEHM8BL6CkdA PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0 Elr: N/A LastKnownElr: N/A
# 发送及接收消息
1.发送消息
[root@VM-8-5-centos kafka_2.13-3.8.0]# bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic test
>Hello World!
>My Friend!
>
2.接收消息
[root@VM-8-5-centos kafka_2.13-3.8.0]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
Hello World!
My Friend!
exitexit
# 集群环境部署
# ZooKeeper集群部署
1.zk集群的搭建一般是奇数节点服务器(最少3台),在每台zk的zoo.cfg配置文件中都添加如下配置:
# 数据目录
dataDir=/app/zk/data
# zk服务端口
clientPort=2181
# 集群节点配置,2888位内部数据传输端口,3888为选举端口
server.1=192.168.0.1:2888:3888
server.2=192.168.0.2:2888:3888
server.3=192.168.0.3:2888:3888
2.在zk的dataDir目录里创建一个名为myid的文件,文件内容为zk的集群编号,如下:
cd /app/zk/data
echo 1 > myid
3.启动zk服务
bin/zkServer.sh --config conf start
# ZooKeeper集群部署验证
1.使用 ZooKeeper 自带的客户端工具来检查集群状态(需要在所有节点执行,能看到1台服务器输出leader,其他输出follower即代表集群部署成功):
bin/zkServer.sh status
执行后输出信息如下:
# 当前节点是一个follower节点
ZooKeeper JMX enabled by default
Using config:/conf/zoo.cfg
Client port found: 2181. Client address: localhost. client SSL: false.
Mode: follower
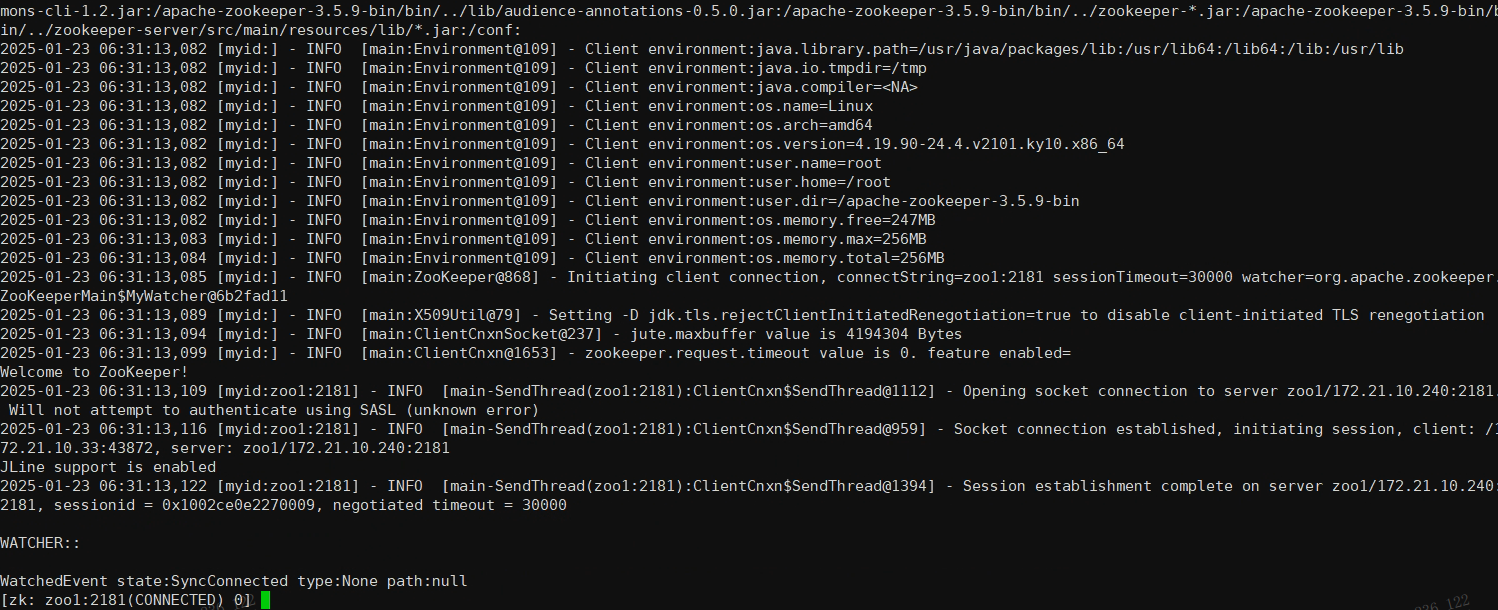
2.通过ZooKeeper的客户端工具可以连接到ZooKeeper集群:
bin/zkCli.sh -server zoo1:2181
连接成功后可以看到如下关键日志信息:
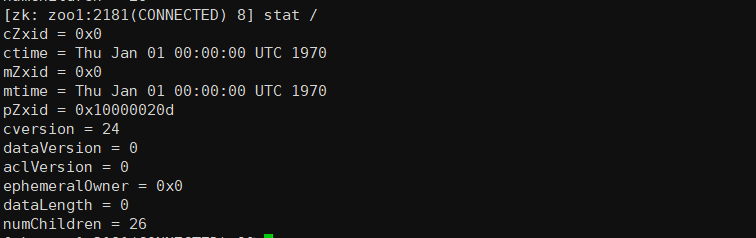
在命令行中输入stat指令可以查看节点信息:
stat /
可以看到当前节点有26个根节点
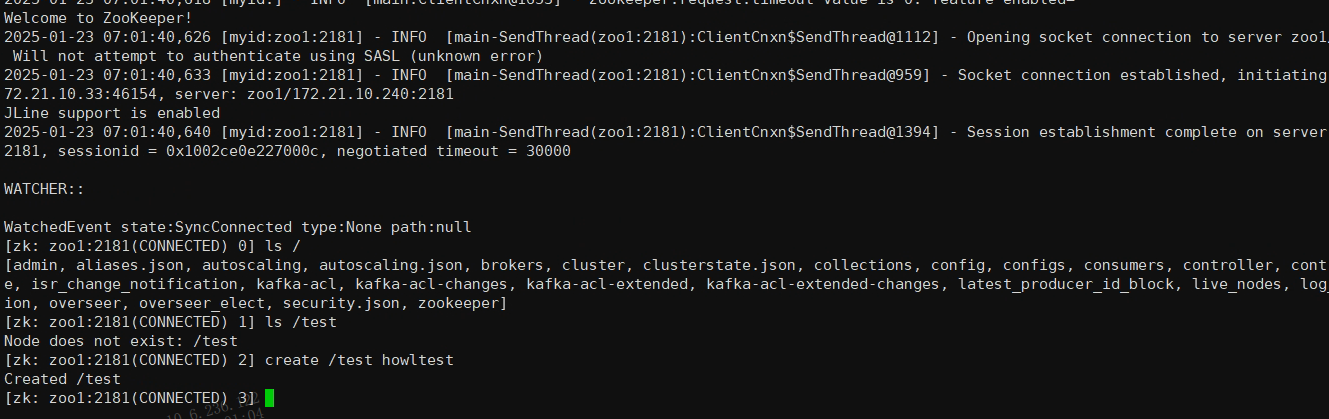
使用ls指令可以查看节点信息(子节点信息)
ls /

使用create 指令创建一个节点信息,在其他ZooKeeper节点上通过get path查看数据是否创建即可验证集群是否可用

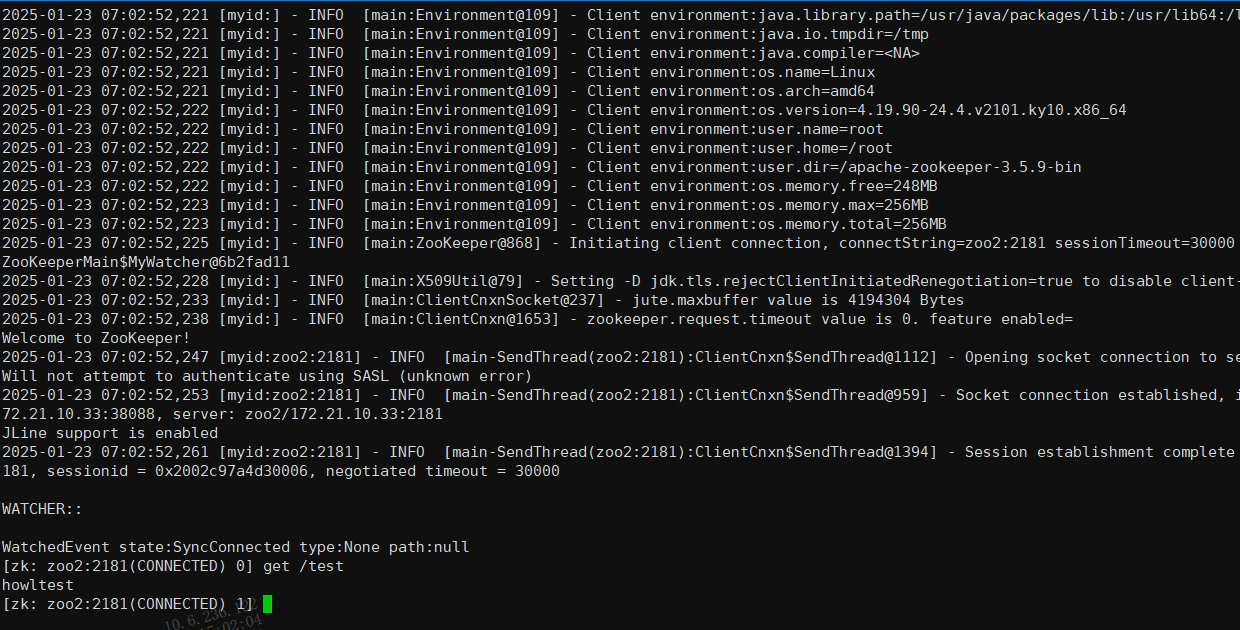
# ZooKeeper节点操作
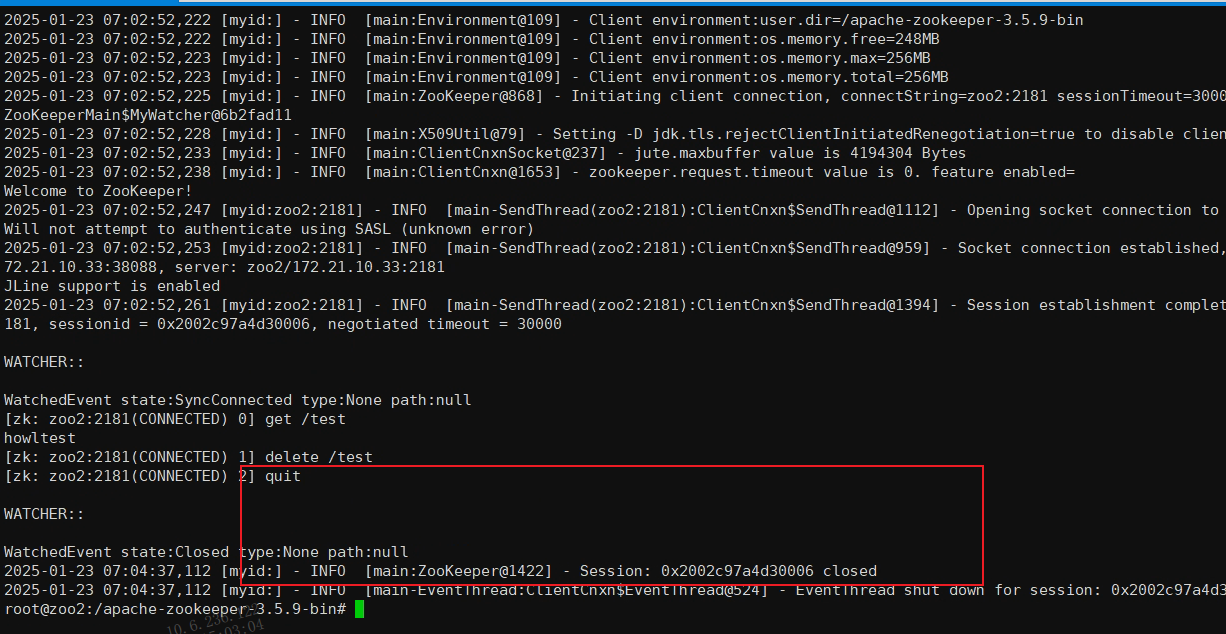
1.创建临时节点(当创建该节点的客户端会话结束时,该节点会自动删除。)
create -e /test howltest
2.创建永久节点
create /test howltest
3.查看节点及子节点
ls /test

4.查看某个节点中存储的数据
get /test
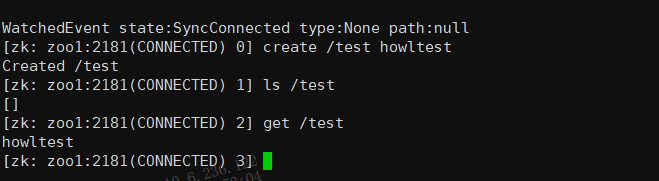
5.设置节点数据
set /test howl1234
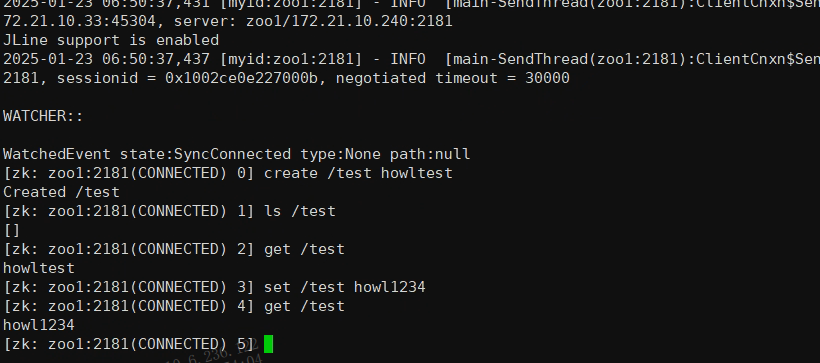
6.删除节点(子节点需要为空)
delete /test

7.删除节点(递归删除子节点)
deleteall /test
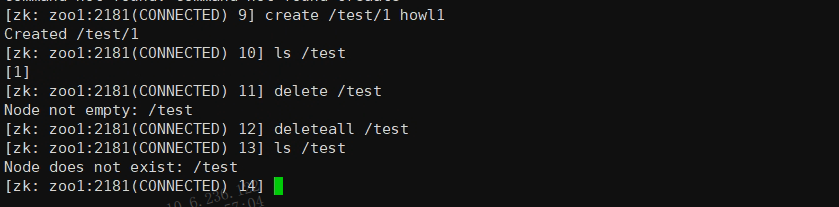
8.使用quit指令可以退出zk连接
quit
# ZooKeeper常见问题排查
- 日志文件:检查 logs/zookeeper.out 文件中的日志,以诊断任何启动或运行时错误。
- 防火墙和端口:确保没有防火墙规则阻止端口(如 2181, 2888, 3888,7000,8080)的通信。
- 网络延迟和分区:使用网络监控工具检查网络延迟和分区情况。
- 版本兼容性:确保所有 ZooKeeper 服务器的版本相同,以避免不兼容问题。
通过以上步骤,你可以部署并验证一个基本的 ZooKeeper 集群。确保在实际部署前在测试环境中充分测试配置和性能。
参考资料
Zookeeper-基本操作:查看节点信息、状态、登陆连接 (opens new window)
黑马程序员Zookeeper视频教程,快速入门zookeeper技术 (opens new window)
# Kafka集群搭建
1.进入kafka的config目录,修改server.properties配置文件,修改的配置如下:
# 每台broker的id不能重复,此外kafka的broker是无状态的
broker.id=1
# broker的监听端口
listeners=PLAINTEXT://127.0.0.1:9092
# 数据文件地址,默认是/tmp
log.dirs=/app/kafka/logs
# 默认每个topic的分区
num.partitions=1
# zk集群的地址
zookeeper.connect=192.168.0.1:2181,192.168.0.2:2181,192.168.0.3:2181
2.启动kafka服务
bin/kafka-server-start.sh -daemon config/server.properties
3.创建topic
# 创建topic
[root@VM-8-5-centos kafka_2.13-3.8.0]# bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --replication-factor 2 --partitions 4 --topic test
Created topic test.
4.操作另外一个节点查看topic
[root@VM-8-5-centos kafka_2.13-3.8.0]# bin/kafka-topics.sh --list --bootstrap-server localhost1:9092
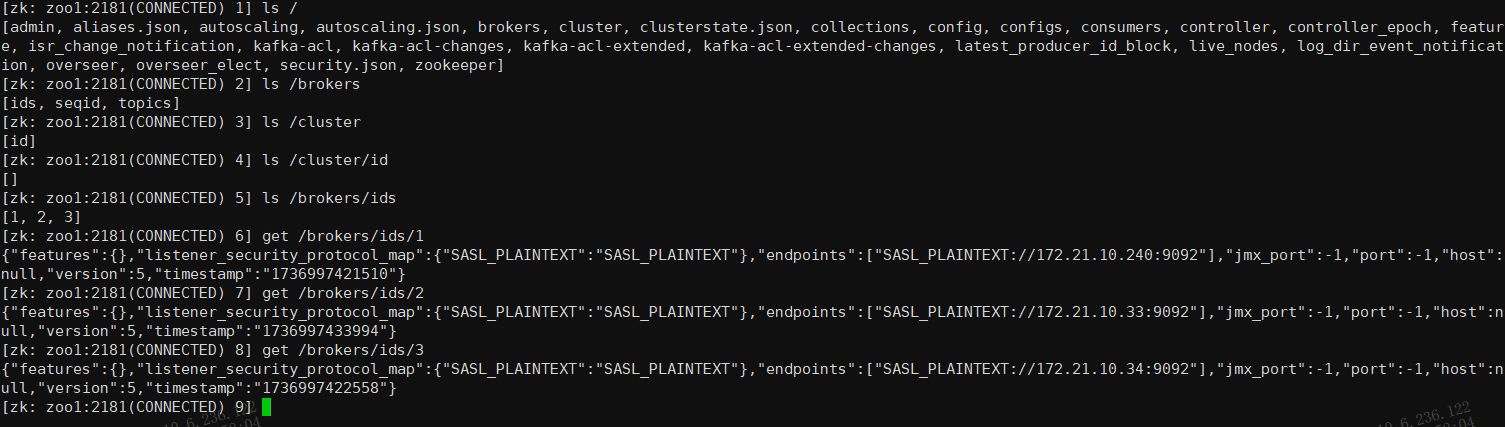
5.在ZooKeeper中查看kafka的broker节点,确认节点是否全部注册
ls /brokers/ids
# Kafka 管理端界面
如果需要以web门户的方式管理Kafka集群,需要额外加装KafkaManager三方管理界面。
# Kafka关键概念
# 消费者分组
kafka中每一个消费者一定从属于一个消费者组,消息消费过程中,一条消息只会发送到消费者组中某一个消费者。同一时间,一个Partition只会和同一消费者组一个Consumer绑定。
使用redis记录offset偏移量
kafka中偏移量offset存储在broker,而偏移量的修改则交给Consumer来处理,Consumer无法感知offset是否修改,修改结果是否正确。如broker中offset异常就有可能出现重复消费问题,因此可以使用redis记录某个Partition的offset,从根本上避免重复消费问题。
# 生产者拦截器
kafka允许在生产者生产消息过程中配置拦截器,对生产者生产消息的各个环节进行增强操作。
# 消息序列化机制
在kafka中,生产者往kafka传输的消息需要进行序列化,消费者消费消息前也需要反序列化,一般情况下我们使用kafka自己提供的string序列化反序列化机制即可,如需实现自己的序列化及反序列化机制,我们需要实现kafka提供的相关接口。
# 消息分区路由策略
# 生产者分发消息
Kafka消息分发策略主要指的是生产者如何将消息分发到不同的分区中。Kafka 支持以下三种分发策略:
Random:随机分区分配器,这是默认的分区分配策略。它会随机选择一个分区并将消息发送至该分区。
RoundRobin:轮询分区分配器,它会按照轮询策略逐个分配分区。
Range:范围分区分配器,它会根据消息键的哈希值来分配分区。所有具有相同键的消息将被写入同一个分区。
在使用 Kafka 生产者客户端时,可以通过配置 partitioner.class 属性来设置分区分配器。
# 消费者消费指定分区消息
如果你想要让消费者直接消费特定的分区,你需要在消费者的配置中设置topic.properties来让消费者消费特定分区的消息。可选的策略有range范围分区,round-robin轮询策略,sticky粘性策略。
kafka如何实现顺序消费
通过指定生产者发送消息的分区以及消费者消费消息的分区,我们就可以在kafka中实现顺序消费。
# 生产者消息缓存机制
kafka生产者为了避免高并发请求对Broker造成过大压力,每次发消息并不会来一条发送一条,而是有一些缓存机制对消息进行批量发送。
# 发送应答机制
发送应答机制其实就是ACK机制,本身没那么复杂,就是面试喜欢问而已。
# 生产者消息幂等性
在生产者像Broker发送消息的时候(如ack机制),实际上涉及两次网络请求,网络本身就不具备稳定性,且一次消息传输还涉及两次请求,因此很容易出现消息重复的情况,kafka的broker内置实现了生产者消息幂等性策略。能防止消息重复发送。
# 生产者消息压缩机制
kafka生产者在发送消息前会对消息体进行压缩,broker收到消息后会进行解压缩。
# 生产者消息事务机制
kafka消息一般是批量发送,一批消息可能会发送到多个broker下的多个partition(很明显的一个跨jvm场景),kafka需要保证这个单词发送支持事务机制。
# SpringBoot集成Kafka
1.在SpringBoot中,引入Maven依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
2.在application.properties中配置kafka相关参数
###### 【kafka集群】 ######
spring.kafka.bootstrap-servers=worker1:9092,worker2:9092,worker3:9092
# 重试次数,生产者发送失败重试
spring.kafka.producer.retries=0
# 生产者应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0,1,all/-1)
spring.kafka.producer.acks=1
# 批量提交的大小
spring.kafka.producer.batch-size=16384
# 提交延迟
spring.kafka.producer.properties.liner.ms=0
# 生产端缓冲区大小
spring.kafka.producer.buffer-memory=33554432
# 配置序列化及反序列化类
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
# 消费者配置
spring.kafka.consumer.group-id=my-group
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
3.创建生产者
@Component
public class KafkaProducer {
// 引入kafkaTemplate即可使用生产者
private final KafkaTemplate<String, String> kafkaTemplate;
@Autowired
public KafkaProducer(KafkaTemplate<String, String> kafkaTemplate) {
this.kafkaTemplate = kafkaTemplate;
}
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message);
}
}
4.创建消费者
@Component
public class KafkaConsumer {
@KafkaListener(topics = "myTopic", groupId = "my-group")
public void listen(String message) {
System.out.println("Received message in group my-group: " + message);
}
}
原生api中生产者及消费者代码编写
1.生产者代码
在kafka里,生产者同样有三种消息发送方式,分别是单向发送,同步发送,异步发送,这点和RocketMQ一致。
/**
* 示例代码:创建 Kafka 生产者,同时单向发送消息
*/
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(properties);
// 发送消息到主题 "my-topic"
producer.send(new ProducerRecord<>("my-topic", "key", "Hello, Kafka!"));
// 关闭生产者
producer.close();
2.消费者代码
// 示例代码:创建 Kafka 消费者
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("group.id", "my-group");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> consumer = new KafkaConsumer<>(properties);
// 订阅主题 "my-topic"
consumer.subscribe(Collections.singletonList("my-topic"));
// 消费消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("Received message: " + record.value());
}
// 同步提交
consumer.commitSync();
// 异步提交
// consumer.commitASync();
}
// 关闭消费者
consumer.close();
# 参考资料
# Kafka是什么?架构是什么样的?
Kafka 是什么?主要应用场景有哪些? (opens new window)
消息队列Kafka是什么?架构是怎么样的?5分钟快速入门 (opens new window)