# Linux运维事件处理
# 运维事件发生-SWAP使用率超过70%
# 事件描述
蓝鲸告警平台显示某台机器内存SWAP使用率超过70%,触发严重告警后回落,需要分析原因。
# 事件处理
告警机器虽然归属在我们系统,不过里面只部署了Mysql,且是Mysql集群里的主节点,而且是测试环境,不知道为啥就配置了蓝鲸告警。按理说直接丢DBA分析就完事了。不过嘛,SWAP的告警从来没处理过。索性就和DBA同学一起看了。
通过free -h指令查看Swap分区的使用情况。
# 这里test@TEST做了调整,非真实用户以及主机名称
# 可以看到Swap分区还有3G可用。
# 因这是告警后的数据,所以仅供参考
[test@TEST ~]$ free -h
total used free shared buff/cache available
Mem: 15Gi 11Gi 255Mi 29Mi 4.2Gi 4.1Gi
Swap: 8Gi 4.2Gi 3Gi
查询到底是哪些进程占用了Swap分区,且占用了多少容量,参考如下脚本(脚本是在我自己的云主机上跑的数据。)
# 这个指令可以拆分成多个执行,后续有时间再细看
[root@VM-8-5-centos ~]# for i in $(cd /proc;ls | grep "^[0-9]"|awk '$0 >100');do awk
'/Swap:/{a=a+$2}END{print "'$i'", a/1024"M"}' /proc/$i/smaps 2>/dev/null;done | sort -k2nr | head -10
22789 392.082M
1091 10.4414M
680 6.82812M
20314 3.27734M
2983 1.98047M
1026 1.94922M
2828 1.71484M
1263 0.910156M
20304 0.757812M
3164 0.648438M
# 可以看到PID为22789的进程是mysqld
[root@VM-8-5-centos ~]# ps -aux | grep 22789
root 12722 0.0 0.0 112812 972 pts/1 S+ 17:07 0:00 grep --color=auto 22789
polkitd 22789 0.2 5.2 1856884 107452 ? Ssl+ Dec05 29:28 mysqld
按搜索引擎检索的相关知识点,Swap分区只在内存紧张的情况下才会去使用,因此,这里就引出了一个问题,为什么没有像下面的运维事件一样触发内存告警,而是直接触发了Swap分区的告警呢?
与DBA同学沟通,发现MySQL也是和java进程一样,有设置最大的内存使用,测试环境默认情况下设置的是4G,因此这里的真实情况应该是Mysql做了什么吃内存的操作,仅有的可支配资源4G内存不够使用,它(MySQL)就盯上了Swap区。随着Swap分区资源的使用,也就触发了告警。
那么又是因为什么原因,MySQL会去操作Swap分区呢,DBA同学凭经验给的结论是读写操作,经查询慢查询日志,可以看到在告警时间段内,有一个查询语句执行了接近10分钟,查询操作了5000万条数据,这也是这次告警的根因。
提示
一般建议Swap区和内存区设置一样的大小,也可以设置为内存区域的二分之一大小。
参考资料
MySQL运维常用工具&指令 (opens new window)
一条报警引起的对 swap 认识 (opens new window)
【JVM】记录一次线上SWAP偏高告警的故障分析过程 (opens new window)
系统内存还有很多的情况下为何swap使用很高了 (opens new window)
Linux修改Swap分区大小及使用优先级 (opens new window)
# 运维事件发生-内存使用率超过85%
# 事件描述
蓝鲸告警平台显示某台机器内存使用率超过85%,触发告警后回落。需要分析原因。
# 事件处理
登录该机器查看内存使用情况,使用free -h指令查看内存信息。
# 这里test@TEST做了调整,非真实用户以及主机名称
# 可以看到内存使用了11G,总内存15G,目前内存使用率73.3%
[test@TEST ~]$ free -h
total used free shared buff/cache available
Mem: 15Gi 11Gi 255Mi 29Mi 4.2Gi 4.1Gi
Swap: 15Gi 4.2Gi 11Gi
使用top指令实时查看具体哪些进程占用了内存。可以看到PID为1879763的java进程占用26.4%的内存,PID为1880839的java进程占用15.1%的内存,PID为1964558的java进程占用19.4%的内存。三者一共占用60.9%的内存。
[test@TEST ~]$ top
top - 14:15:44 up 634 days, 17:33, 1 user, load average: 5.88, 2.93, 2.32
Tasks: 340 total, 2 running, 336 sleeping, 1 stopped, 1 zombie
%Cpu(s): 14.4 us, 4.0 sy, 0.0 ni, 81.3 id, 0.0 wa, 0.2 hi, 0.2 si, 0.0 st
MiB Mem : 15830.8 total, 258.4 free, 11278.0 used, 4294.4 buff/cache
MiB Swap: 16384.0 total, 12134.4 free, 4249.6 used. 4211.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
...
1879763 root 20 0 9.9g 4.1g 9532 S 27.2 26.4 1502:36 java
1880839 root 20 0 9.8g 2.3g 10192 S 6.3 15.1 809:52.18 java
1964558 root 20 0 11.1g 3.0g 10276 S 3.3 19.4 16457:21 java
...
1229868 test 20 0 56636 4828 3776 R 0.3 0.0 0:00.03 top
1964622 root 20 0 9824644 486056 2792 S 0.3 3.0 396:16.93 java
接下来通过ps -aux | grep PID查看每个进程的详情,可以看到PID为1879763的java进程详细信息如下:
[test@TEST ~]$ ps -aux | grep 1879763
test 1230963 0.0 0.0 12140 1152 pts/0 S+ 14:17 0:00 grep --color=auto 1879763
test 1879763 15.4 26.3 10354080 4279536 ? Ssl Dec06 1502:52
# 重点关注-Xms字段,这个进程允许使用的最大内存是4G
java -Xms4096M -Xmx4096M -Xmn2560M -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m
-Djava.security.egd=file:/dev/./urandom
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/logs/dump.hprof
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=10
-XX:PretenureSizeThreshold=1M
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=85
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=3
-Dspring.profiles.active=prod
# 已做脱敏处理
-Dspring.application.name=test1
-Dspring.cloud.nacos.config.group=DEFAULT_GROUP
# 已做脱敏处理
-Dspring.cloud.nacos.config.server-addr=127.0.0.1:8080
# 已做脱敏处理
-Dspring.cloud.nacos.config.ext-config[0].data-id=test1-node2.properties
# 已做脱敏处理
-jar /test1.jar
接下来通过ps -aux | grep PID查看每个进程的详情,可以看到PID为1880839的java进程详细信息如下:
[test@TEST ~]$ ps -aux | grep 1880839
test 1231346 0.0 0.0 12140 1200 pts/0 S+ 14:17 0:00 grep --color=auto 1880839
test 1880839 8.3 15.0 10304416 2440124 ? Ssl Dec06 810:00
# 重点关注-Xms字段,这个进程允许使用的最大内存是4G
java -Xms4096M -Xmx4096M -Xmn2730M -Xss1M -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/logs/dump.hprof
-XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=128M
-XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=10
-XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=85
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3
# 已做脱敏处理
-jar /test2.jar
# 已做脱敏处理
--spring.application.name=test2
--spring.profiles.active=prod
--spring.cloud.nacos.config.group=DEFAULT_GROUP
# 已做脱敏处理
--spring.cloud.nacos.config.server-addr=127.0.0.1:8081
# 已做脱敏处理
--spring.cloud.nacos.config.ext-config[0].data-id=test2-node2.properties
接下来通过ps -aux | grep PID查看每个进程的详情,可以看到PID为1964558的java进程详细信息如下:
[test@TEST ~]$ ps -aux | grep 1964558
test 1232134 0.0 0.0 12140 1160 pts/0 S+ 14:18 0:00 grep --color=auto 1964558
test 1964558 13.0 19.3 11626944 3141444 ? Ssl Sep17 16457:39
# 重点关注-Xms字段,这个进程允许使用的最大内存是5G
java -Xms5120M -Xmx5120M -Xmn3413M -Xss1M -XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/logs/dump.hprof -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
-XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=10 -XX:PretenureSizeThreshold=3M
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=85
-XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3
# 已做脱敏处理
-jar /test3.jar
# 已做脱敏处理
--spring.application.name=test3
--spring.profiles.active=prod --spring.cloud.nacos.config.group=DEFAULT_GROUP
# 已做脱敏处理
--spring.cloud.nacos.config.server-addr=127.0.0.1:8082
# 已做脱敏处理
--spring.cloud.nacos.config.ext-config[0].data-id=test3-node2.properties
可以看到,理论上3个进程所使用的内存就已经达到了4G+4G+5G,一共13G的内存,除以总内存15G,约为86%,这还是只考虑这3个进程的情况下的数据,所以内存超85%是很正常的,基于这3个进程的内存配置都是一个合理值,得出来的结论就只有一个了,那就是内存资源扩容。
提示
1.很多时候扩容需要停机,停机前,最好通过ps auxwwww指令查看目前主机中有哪些进程在运行。
2.停机前,最好通过cat /etc/rc.local指令查看目前有哪些进程设置了开机自启动。
3.有可能有一些临时的环境变量,使用printenv指令提前记录一下环境变量。
4.通过netstat -nutpl指令查看当前主机上的端口占用情况。
提示
1.通过下面的指令可以查看进程的内存使用率排行,这里查看的是前面10个进程。
ps aux --sort=-%mem | head -n 11
# 运维事件发生-修改ssh用户的密码
# 事件描述
安全部门告知测试环境服务器ssh服务某一个用户名的口令是弱密码,需要修改为符合安全要求的密码。
接到这个运维事件的时候首先纠结了一下,这里ssh用户到底是指什么,我的理解是ssh就是一个服务,开放22号端口用于远程连接主机,这里的ssh用户和linux用户有什么关系呢?查了资料才知道,默认情况下所有的linux用户都能通过ssh访问主机,也可以在ssh的配置里禁止某些用户分访问。
所以这个运维事件实际上指的是修改linux用户的密码。
# 事件处理
与业务系统沟通后,使用passwd指令修改对应用户的密码即可,可以使用在线随机密码生成器 (opens new window)在线生成满足安全规则的随机密码。
passwd username
# 运维事件发生-查看操作系统版本
# 事件描述
因系统某一台机器出现生产问题,出现生产问题的原因是系统使用了特定版本的麒麟系统服务器,因此,需要对同一系统的其他主机的系统配置信息进行确认
# 事件处理
获取到对应系统的服务器资源清单后,申请权限,到对应的主机上使用如下指令查看系统版本即可
cat /proc/version
或
cat /etc/os-release
# 运维事件发生-生产环境数据迁移到测试环境
# 事件描述
业务系统需要将生产环境/app/data/shared路径数据迁移到测试环境/app/data/shared路径,需要运维支持处理。
# 生产环境分析
获取到相关主机的运维权限后,前往生产环境查看系统环境的一些基本信息,这里直接进入/app/data/shared路径,使用如下指令查看该文件夹的磁盘大小。
#查看当前目录磁盘空间使用情况
du -sh
看到这个磁盘空间大小100GB,首先想到的是使用scp指令直接传输到测试环境,经与其他同事沟通,有很多问题,一个是无法获取到测试环境的用户名及密码,第二个是生产环境与测试环境隔离,不能开通防火墙,第三个问题是scp指令本身被禁止使用。因此考虑使用tar指令将生产环境打tar包,做分片处理后下载到本地,再逐个上传到测试环境后合并,然后解压缩的方式完成迁移。
因为这里涉及一个打tar包的过程,需要占用生产环境的磁盘空间资源,需要提前确认是否剩余磁盘空间支持这个操作,使用如下指令查看对应磁盘使用情况。
df -h
查看的结果是剩余磁盘空间大于100G,即允许生成压缩包切片。接下来开始做数据迁移。(这里同样需要确认测试环境的情况,即测试环境也需要剩余200G以上的磁盘空间)。
# 数据迁移
采用先压缩切片生产环境数据,再下载到本地后上传测试环境,然后在测试环境合并切片并解压缩的方式实现数据迁移。
- 打包切片 使用如下指令对生产环境进行打包以及切片处理。
tar zcvf - /app/data/shared | split -b 1024M -d - sharedfile.tar.gz.
- 合并 使用如下指令对测试环境上的切片进行合并
cat sharedfile.tar.gz.* > sharedfile.tar.gz
- 解压缩 使用如下指令对压缩包进行解压缩处理
tar zxvf sharedfile.tar.gz
# 运维事件发生-配置yum仓库
# 事件描述
需要通过yum仓库下载以及安装软件,因此需要配置远程yum仓库。
# 事件处理
yum仓库是以操作系统为维度的,因此,我们首先需要确定主机的操作系统版本,然后选择对应的网络源配置。
# 确认操作系统版本
使用如下指令确认操作系统版本,最终确认操作系统版本为CentOS7.9版本。
# 方法1:查看/proc/version,可以看到是Red Hat红帽操作系统
[root@VM-8-5-centos etc]# cat /proc/version
Linux version 3.10.0-1160.92.1.el7.x86_64 (mockbuild@kbuilder.bsys.centos.org) (gcc version 4.8.5 20150623 (Red Hat 4.8.5-44) (GCC) ) #1 SMP Tue Jun 20 11:48:01 UTC 2023
# 方法2:通过uname -a指令查看
[root@VM-8-5-centos etc]# uname -a
Linux VM-8-5-centos 3.10.0-1160.92.1.el7.x86_64 #1 SMP Tue Jun 20 11:48:01 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
# 方法3:查看/etc/os-release文件
[root@VM-8-5-centos etc]# cat /etc/os-release
NAME="CentOS Linux"
VERSION="7 (Core)"
ID="centos"
ID_LIKE="rhel fedora"
VERSION_ID="7"
PRETTY_NAME="CentOS Linux 7 (Core)"
ANSI_COLOR="0;31"
CPE_NAME="cpe:/o:centos:centos:7"
HOME_URL="https://www.centos.org/"
BUG_REPORT_URL="https://bugs.centos.org/"
CENTOS_MANTISBT_PROJECT="CentOS-7"
CENTOS_MANTISBT_PROJECT_VERSION="7"
REDHAT_SUPPORT_PRODUCT="centos"
REDHAT_SUPPORT_PRODUCT_VERSION="7"
# 方法4:如确定是RedHat系统可查看此文件,最终确定操作系统版本是CentOS 7.9版本
[root@VM-8-5-centos etc]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
# 确认网络yum源
登录阿里巴巴开源镜像站 (opens new window),可以看到有如下两个yum源镜像站可供选择,分别是centos源以及epel源。

# 配置yum源
使用如下指令重新配置yum源。
# 第一步:清理掉旧的yum源文件
[root@VM-8-5-centos ~]# cd /etc/yum.repos.d/
[root@VM-8-5-centos yum.repos.d]# rm -rf *
# 第二步: 下载centos7 yum源文件
[root@VM-8-5-centos yum.repos.d]# wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
--2023-12-21 09:33:55-- https://mirrors.aliyun.com/repo/Centos-7.repo
Resolving mirrors.aliyun.com (mirrors.aliyun.com)... 14.119.65.239, 14.119.65.240, 14.119.65.243, ...
Connecting to mirrors.aliyun.com (mirrors.aliyun.com)|14.119.65.239|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 2523 (2.5K) [application/octet-stream]
Saving to: ‘/etc/yum.repos.d/CentOS-Base.repo’
100%[=====================================================================>] 2,523 --.-K/s in 0s
2023-12-21 09:33:55 (617 MB/s) - ‘/etc/yum.repos.d/CentOS-Base.repo’ saved [2523/2523]
# 第三步:下载epel yum源文件
[root@VM-8-5-centos yum.repos.d]# wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
--2023-12-21 09:34:35-- https://mirrors.aliyun.com/repo/epel-7.repo
Resolving mirrors.aliyun.com (mirrors.aliyun.com)... 14.119.65.243, 14.119.65.238, 14.119.65.240, ...
Connecting to mirrors.aliyun.com (mirrors.aliyun.com)|14.119.65.243|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 664 [application/octet-stream]
Saving to: ‘/etc/yum.repos.d/epel.repo’
100%[=====================================================================>] 664 --.-K/s in 0s
2023-12-21 09:34:36 (232 MB/s) - ‘/etc/yum.repos.d/epel.repo’ saved [664/664]
# 第四步: 保存配置
## 清理所有缓存
[root@VM-8-5-centos yum.repos.d]# yum clean all
Loaded plugins: fastestmirror, langpacks, product-id, search-disabled-repos
Cleaning repos: base epel extras updates
## 创建缓存
[root@VM-8-5-centos yum.repos.d]# yum makecache
Loaded plugins: fastestmirror, langpacks, product-id, search-disabled-repos
Determining fastest mirrors
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
base | 3.6 kB 00:00:00
epel | 4.7 kB 00:00:00
extras | 2.9 kB 00:00:00
updates | 2.9 kB 00:00:00
(1/16): base/7/x86_64/group_gz | 153 kB 00:00:00
(2/16): base/7/x86_64/filelists_db | 7.2 MB 00:00:02
(3/16): epel/x86_64/group_gz | 99 kB 00:00:00
(4/16): base/7/x86_64/primary_db | 6.1 MB 00:00:02
(5/16): epel/x86_64/updateinfo | 1.0 MB 00:00:00
(6/16): epel/x86_64/prestodelta | 704 B 00:00:00
(7/16): base/7/x86_64/other_db | 2.6 MB 00:00:00
(8/16): epel/x86_64/primary_db | 7.0 MB 00:00:02
(9/16): extras/7/x86_64/primary_db | 250 kB 00:00:00
(10/16): extras/7/x86_64/filelists_db | 303 kB 00:00:00
(11/16): extras/7/x86_64/other_db | 150 kB 00:00:00
(12/16): epel/x86_64/filelists_db | 12 MB 00:00:03
(13/16): epel/x86_64/other_db | 3.4 MB 00:00:01
(14/16): updates/7/x86_64/filelists_db | 13 MB 00:00:04
(15/16): updates/7/x86_64/other_db | 1.5 MB 00:00:00
(16/16): updates/7/x86_64/primary_db | 24 MB 00:00:07
Metadata Cache Created
# 运维事件发生-配置永久路由
# 事件描述
测试环境需要开通主机之间的防火墙,联系网络组同事开通以后,使用telnet指令测试验证发现无法联通。反馈给网络组同事后,他说大概率是没有配置路由导致的,并且提供了如下指令配置路由。
## 相关ip做了改动
[test@TEST ~]# route add -net 127.0.0.1 netmask 255.255.0.0 gw 192.168.0.1
执行该指令之后,telnet指令可以正常访问通目标端主机。同事一再强调这条指令配置的是临时路由,重启主机后就会失效,需要重新配置。最好是让系统组同事配置永久路由。因此,这里查找资料了解下永久路由如何配置。
# 事件处理
首先,查看该路由配置是否生效,使用如下指令:
# 可以看到对应的路由记录已经成功显示
[test@TEST ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
127.0.0.1 192.168.0.1 255.255.0.0 UG 0 0 0 ens3
...
使用root指令重启主机,然后使用route指令验证,发现刚才生效的路由记录消失了。同时再次使用telnet指令验证服务,此时服务不通。
# 配置永久路由
通过修改配置文件的形式配置永久路由,如下:
[test@TEST ~]# cd /etc/sysconfig/network-scripts/
[test@TEST network-scripts]# vim route-ens3
# 将如下内容添加到route-ens3文件中
127.0.0.1/16 via 192.168.0.1 dev ens3
使用reboot指令重启主机后重新使用route指令验证,发现路由记录正常存在,通过telnet指令可以正常访问服务,永久修改路由配置生效。
# 运维事件发生-配置ssh免密登录
# 事件描述
下游业务系统反馈某个测试环境做业务的过程中报错,分析定位原因是因为服务间通信依赖ssh免密登录功能,而部署的两台主机之间并没有配置免密登录,因此,需要做配置。
# 事件处理
业务系统中的ssh免密登录是一个单向的访问过程,即a主机需要ssh免密访问b主机。这里称a主机位源端,b主机为目标端。我们这里分两步来实现ssh免密登录,首先是在源端主机上生成ssh公钥以及秘钥,其次是将源端主机的公钥放到目标端主机的已鉴权公钥文件中。
# 源端主机生成私钥公钥
# 切换用户
su test
# 切换目录到.ssh
cd .ssh
# 生成当前主机的ssh公私钥文件
ssh-keygen -t rsa -m pem
# 查看公钥,先复制公钥内容,后面会粘贴到目标主机的已鉴权公钥文件中
cat id_rsa.pub
# 目标端主机中配置源端主机公钥
# 切换用户
su test
# 切换目录到.ssh
cd .ssh
# 修改已鉴权公钥文件,将源端主机的公钥配置到该文件中,然后保存退出即可
vim authorized_keys
# 验证免密登录是否完成
登录源端主机,使用ssh指令访问目标端主机即可验证免密配置:
# test为需要访问目标端的用户账户,127.0.0.1为目标端主机的ip
ssh test@127.0.0.1
# 完整配置
#client
ssh-keygencat ~/.ssh/id_rsa.pub
#server
mkdir -p ~/.sshchmod 700 ~/.sshtouch ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keysclearecho 'xxxxx' >>~/.ssh/authorized_keys
# 运维事件发生-docker容器内生成java进程的dump?
# 事件描述
某个java进程运行在Docker容器之中,需要在Docker容器中使用jmap生成dump并分析dump文件。
# 事件处理
[root@HKDCL144006 bin]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
46263ca75172 50d47598e2e5 "/bin/sh -c 'exec ja…" 7 months ago Up 3 weeks umc-test
# 进入到对应的容器的操作系统里
[root@HKDCL144006 bin]# docker exec -it 46263ca75172 /bin/bash
# 创建app目录,用于后续存放dump文件
[root@HKDCL144006 /]# mkdir /app
# 查看java进程,可以看到进程id为1的java进程
[root@HKDCL144006 /]# ps -ef | grep java
root 1 0 7 2023 ? 2-03:21:35 java -Xms4096M -Xmx4096M -Xmn2560M -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Djava.security.egd=file:/dev/./urandom -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/logs/dump.hprof -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=10 -XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=85 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3 -jar /umc-test.jar
root 3476766 3476685 0 10:06 pts/0 00:00:00 grep --color=auto java
# 判断是否安装java,这步可以省略
[root@TEST /]# java -version
openjdk version "1.8.0_345"
OpenJDK Runtime Environment (Alibaba Dragonwell Standard Edition 8.12.13) (build 1.8.0_345-b01)
OpenJDK 64-Bit Server VM (Alibaba Dragonwell Standard Edition 8.12.13) (build 25.345-b01, mixed mode)
# 找到java的安装路径
[root@TEST /]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/java/openjdk/bin
[root@TEST bin]# cd /opt/java/openjdk/bin
[root@TEST bin]# ./jmap -dump:format=b,live,file=/logs/dump.hprof 1
Dumping heap to /app/test.dump ...
Heap dump file created
[root@TEST bin]# cd /app
[root@TEST app]# ls
test.dump
#退出当前bash
[root@TEST app]# exit
exit
# 将容器内的文件拷贝到宿主机
[root@TEST ~]# docker cp 46263ca75172:/app/dump.hprof /app/dump.hprof
[root@TEST ~]# cd /app
[root@TEST app]# ls
test.dump
参考资料
OOM-内存溢出时,导出docker容器中服务的dump文件 (opens new window)
从容器里dump java堆实验探索(原创) (opens new window)
【内存分析-jmap】已安装JDK,bash: jamp: command not found (opens new window)
# 运维事件发生-测试环境部署多个Nginx服务?
# 事件描述
测试环境A主机,需要迁移到B主机,相关的服务需要做迁移,比较核心的是Nginx服务。
# 事件处理
查看A主机上的Nginx进程,发现同时有4个Nginx进程在运行。
root@TEST:~# ps auxwww | grep nginx
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
# 4个nginx worker进程
test 20346 0.0 0.0 26888 4196 ? S Jan18 0:01 nginx: worker process
root 18282 0.0 0.0 26716 3000 ? S 2022 13:30 nginx: worker process
test 18273 0.0 0.0 25668 216 ? S 2022 0:00 nginx: worker process
test 18276 0.0 0.0 25668 732 ? S 2022 0:00 nginx: worker process
# 4个nginx master进程
root 18278 0.0 0.0 26184 3452 ? Ss 2022 0:00 nginx: master process /app/gravitee/nginx_gravitee_endpoint/sbin/nginx -c /app/gravitee/nginx_gravitee_endpoint/conf/nginx.conf
root 18281 0.0 0.0 25364 132 ? Ss 2022 0:00 nginx: master process /app/gravitee/nginx_gateway_nginx/sbin/nginx -c /app/gravitee/nginx_gateway_nginx/conf/nginx.conf
root 18272 0.0 0.0 25220 4 ? Ss 2022 0:00 nginx: master process /app/gravitee/nginx_gateway_webam/sbin/nginx -c /app/gravitee/nginx_gateway_webam/conf/nginx.conf
root 18275 0.0 0.0 25220 88 ? Ss 2022 0:00 nginx: master process /app/gravitee/nginx_gateway_webapim/sbin/nginx -c /app/gravitee/nginx_gateway_webapim/conf/nginx.conf
这里考虑在迁移后的机器上以编译执行的方式安装Nginx服务(安装过程参见下方资料,yum源的安装找了其他部门同事协助。)。安装完成后进行验证。
[root@TEST ~]# cd /usr/local/nginx
[root@TEST nginx]# ls
client_body_temp conf fastcgi_temp html logs proxy_temp sbin scgi_temp uwsgi_temp
[root@TEST nginx]# cd sbin
[root@TEST sbin]# ls
nginx nginx.old
# 启动nginx之前需要先检查nginx配置
[root@TEST sbin]# nginx -t ../conf/nginx.conf
# 启动nginx
[root@TEST sbin]# ./nginx
# 可以看到nginx启动完成,同时80端口可以获取到欢迎页的html页面
[root@TEST sbin]# curl http://127.0.0.1:80
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
到这里其实一切都还顺利,突然想到个问题,A主机上是同时部署了4个Nginx服务的,这个是怎么做到的呢?百思不得其解,问了几个同事,也没见到这种部署方式。
突然灵光一闪,猜测可能是直接复制/usr/local/nginx到别的路径,验证了一下发现确实如此。后续把nginx复制4份,以不同的端口以及配置文件启动后再验证是否正常。
参考资料
1.Linux下Nginx编译安装过程详解 (opens new window)
2.通过在执行configure配置服务阶段使用如下参数 ./configure --prefix=/app/gateway/nginx_gateway_nginx --with-http_sub_module 可以指定nginx的安装路径。
# 运维事件发生-生产环境停机对内存进行扩容
# 事件描述
生产环境主机内存资源需要扩容,扩容需要停机。在停机之前需要做一些准备工作,以确保在重新开机之后可以恢复系统运行。
# 事件处理
将事件处理分为停机前准备工作,停机后恢复业务进程工作,业务验证工作。
# 停机前准备工作
打印运行中的进程信息。
# 这里仅展示关键进程,其中4个由docker容器创建的业务进程,一个mysqlrouter进程,还有另外一个引发生产问题的aimqry进程
[root@TEST ~]# ps auxwwwwwww
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
# mysqlrouter进程
root 1613090 0.0 0.0 1008132 8000 ? Sl 2023 189:03 ./mysqlrouter --config=/toolsapp/mysqlrouter/mysqlrouter.conf
# 一个未识别到的关键进程,后续引发了生产问题
root 2060555 5.4 1.3 4921072 211048 ? Ssl 2022 40327:11 /toolsapp/test/aimqry/aimqry
# 由docker容器启动的java业务进程1,启动参数略有修改
root 2990339 9.4 14.8 10303808 2401660 ? Ssl 2023 6179:01 java -Xms4096M -Xmx4096M -Xmn2730M -Xss1M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/logs/dump.hprof -XX:MetaspaceSize=128M -XX:MaxMetaspaceSize=128M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=10 -XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=85 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3 -jar /test-storage.jar
# 由docker容器启动的java业务进程2,启动参数略有修改
root 3834548 15.3 19.3 11627152 3142712 ? Ssl 2023 27842:36 java -Xms5120M -Xmx5120M -Xmn3413M -Xss1M -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/logs/dump.hprof -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=10 -XX:PretenureSizeThreshold=3M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=85 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3 -jar /test-business.jar
# 由docker容器启动的java业务进程3
root 3834612 0.3 5.1 9824644 833492 ? Ssl 2023 609:57 java -jar test-monitor-client.jar
# 由docker容器启动的java业务进程4,启动参数略有修改
root 3837975 14.2 27.5 10367428 4471484 ? Ssl 2023 25871:55 java -Xms4096M -Xmx4096M -Xmn2560M -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -Djava.security.egd=file:/dev/./urandom -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/logs/dump.hprof -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=10 -XX:PretenureSizeThreshold=1M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=85 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=3 -jar /test-receiver.jar
root 4119417 0.2 0.0 20852 5572 pts/0 Ss 03:06 0:00 -bash
root 4119707 0.0 0.0 49692 3860 pts/0 R+ 03:07 0:00 ps auxwwwwwww
打印docker容器信息。
[root@TEST ~]# docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
297082710db7 test-receiver 13.69% 4.687GiB / 6GiB 78.11% 0B / 0B 116GB / 1.61GB 200
6ef169729dc9 test-storage 5.34% 2.337GiB / 6GiB 38.95% 0B / 0B 9.44GB / 147kB 156
1b477fd410d7 test-business 21.51% 3.025GiB / 6.5GiB 46.54% 0B / 0B 48.6GB / 1.24MB 293
02c1ab2f951d test-monitor-client 0.32% 821.9MiB / 15.46GiB 5.19% 0B / 0B 31.5GB / 24.6kB 76
打印开机自启动配置信息。
[test@TEST ~]$ cat /etc/rc.local
#!/bin/bash
# THIS FILE IS ADDED FOR COMPATIBILITY PURPOSES
#
# It is highly advisable to create own systemd services or udev rules
# to run scripts during boot instead of using this file.
#
# In contrast to previous versions due to parallel execution during boot
# this script will NOT be run after all other services.
#
# Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure
# that this script will be executed during boot.
touch /var/lock/subsys/local
dmesg -s 1048576
[ -f /usr/local/gse/agent/bin/gsectl ] && /usr/local/gse/agent/bin/gsectl start >/var/log/gse_start.log 2>&1
打印环境变量信息。
[root@TEST ~]# printenv
MODULES_CMD=/usr/share/Modules/libexec/modulecmd.tcl
USER=root
PWD=/root
SSH_ASKPASS=/usr/libexec/openssh/gnome-ssh-askpass
HOME=/root
XDG_DATA_DIRS=/root/.local/share/flatpak/exports/share:/var/lib/flatpak/exports/share:/usr/local/share:/usr/share
LOADEDMODULES=
SSH_TTY=/dev/pts/0
MAIL=/var/spool/mail/root
TERM=xterm
SHELL=/bin/bash
TMOUT=900
SHLVL=1
MANPATH=:
MODULEPATH=/etc/scl/modulefiles:/usr/share/Modules/modulefiles:/etc/modulefiles:/usr/share/modulefiles
LOGNAME=root
DBUS_SESSION_BUS_ADDRESS=unix:path=/run/user/0/bus
XDG_RUNTIME_DIR=/run/user/0
MODULEPATH_modshare=/usr/share/modulefiles:1:/usr/share/Modules/modulefiles:1:/etc/modulefiles:1
PATH=/usr/share/Modules/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/zabbix4/bin:/zabbix4/sbin:/toolsapp/mysqlrouter/bin:/root/bin
MODULESHOME=/usr/share/Modules
HISTSIZE=1000
打印进程占用端口的信息。
# 这条指令需要使用root执行就可以看到PID和端口的映射关系,也就是说可以看到端口是被哪个进程开启的。
# 实际生产环境变更前,忘记执行这条指令了。
[test@TEST ~]$ netstat -nutpl
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 10.28.87.158:60020 0.0.0.0:* LISTEN -
tcp 0 0 192.168.122.1:53 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:7001 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:7002 0.0.0.0:* LISTEN -
tcp 0 0 10.28.87.158:10060 0.0.0.0:* LISTEN -
# 遗漏的关键端口,对应的进程是aimqry
tcp 0 0 0.0.0.0:9806 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN -
tcp6 0 0 :::8080 :::* LISTEN -
tcp6 0 0 :::8081 :::* LISTEN -
tcp6 0 0 :::22 :::* LISTEN -
tcp6 0 0 :::8091 :::* LISTEN -
tcp6 0 0 :::9087 :::* LISTEN -
tcp6 0 0 :::8000 :::* LISTEN -
tcp6 0 0 :::111 :::* LISTEN -
udp 0 0 192.168.122.1:53 0.0.0.0:* -
udp 0 0 0.0.0.0:67 0.0.0.0:* -
udp 0 0 0.0.0.0:111 0.0.0.0:* -
udp 0 0 0.0.0.0:123 0.0.0.0:* -
udp 0 0 127.0.0.1:323 0.0.0.0:* -
udp 0 0 0.0.0.0:5353 0.0.0.0:* -
udp 0 0 0.0.0.0:57831 0.0.0.0:* -
udp 0 0 10.28.87.158:60020 0.0.0.0:* -
udp6 0 0 :::111 :::* -
udp6 0 0 ::1:323 :::* -
udp6 0 0 :::49698 :::* -
udp6 0 0 :::51183 :::* -
udp6 0 0 :::5353 :::* -
udp6 0 0 :::57057 :::* -
udp6 0 0 :::57109 :::* -
udp6 0 0 :::60331 :::* -
其他停机前准备工作
# 可以通过memdump指令备份内存快照为一个文件,后续恢复,这个操作没有尝试执行过,也不清楚具体效果。
# 停机后恢复进程
停机后,恢复mysqlrouter以及docker中4个容器的运行。
# 业务验证
在恢复mysqlrouter以及docker容器的运行后,登录系统,数据库可以正常链接,验证系统核心功能(短信发送),最终用户可以成功接收到短信。业务验证完成。
# 生产问题-9806端口丢失
在验证完核心业务功能后,准备下班,监控的同事发出告警,告警显示9806端口的进程未开启。
分析原因
按说停机前能确认的东西都确认了,该开启的进程也开启了,核心业务也可以正常使用了。实在是不知道这个端口是干什么的,无奈之下,只能去找应用的部署文档。通过部署文档可以看到,确实是有一个docker容器占用了9806端口。

问题是,停机之前有4个容器,对应4个java进程,都开启了的呀。和供应商确认,说是这个容器是做智能短信功能的,并未在生产环境部署。这个就很怪了,既然没部署,为啥还会被监控端口呢?和旁边的同事交流了下,推测可能是有镜像存在,而没有使用镜像生成容器。通过docker images指令查看镜像,发现确实有一个镜像没有生成容器,对应的就是文档里占用9806端口的进程。这个进程并不是一个java进程。
通过aimqry关键字检索停机前的进程信息,发现该进程确实停机前启动着,而停机后并未开启,也就是说这个进程由docker容器启动调整为宿主机系统进程启动,在调整过程中并没有删除对应的镜像信息。启动aimqry进程
启动aimqry进程后,查看端口占用情况,发现9806端口开启。后续监控的同事反馈成功获取到该端口的监控信息。
# 生产问题-短信状态异常
在生产做验证的时候,发现短信的状态异常,查看短信发送记录,发现如下3种记录:
1.分别是短信发送成功,短信接收状态未知。
2.短信未发送,未接收。
3.短信未发送,短信已接收。
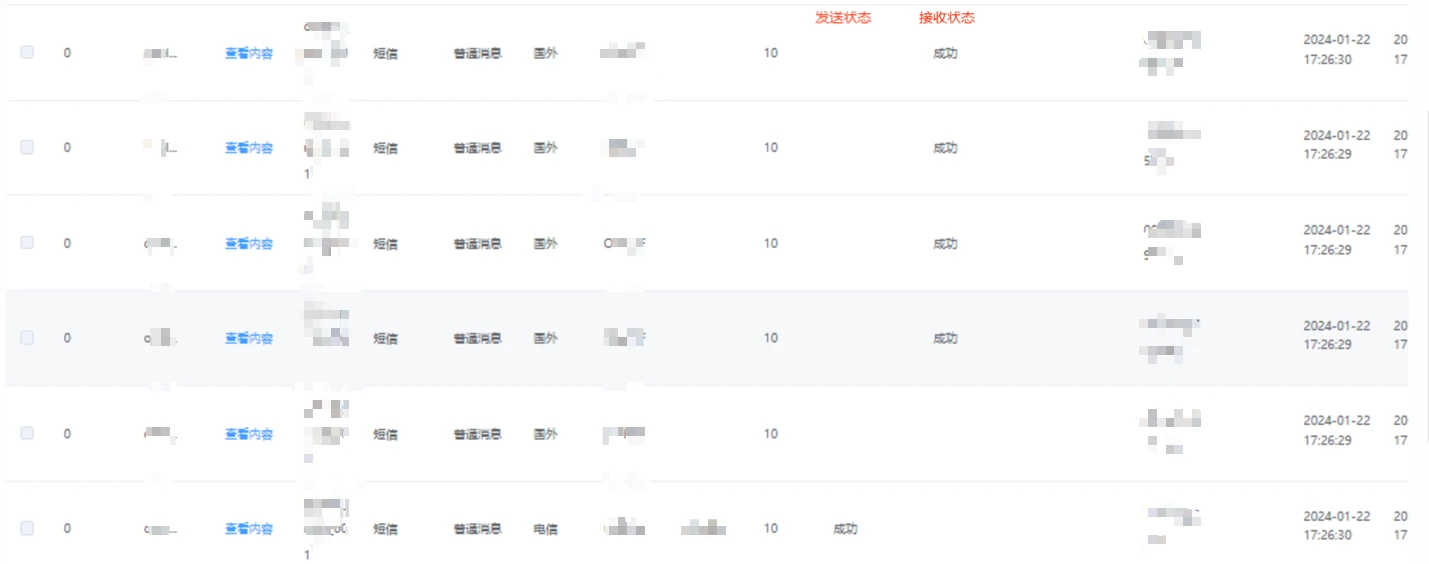
实在是太诡异了,怎么会存在没有发送成功记录,但是短信又接收成功的记录呢。考虑还是变更导致的,分析变更的两台主机的日志。发现有1台机器报错,报错信息如下:

通过该日志,可以看出是使用了从库做写操作,因此报错。而变更的主机确实是会对短信的发送状态和接收状态做写入操作的。这也就解释了为什么会出现有短信没有发送成功记录,却有接收成功记录的原因。即发送记录的写入负载到了有问题的主机上,写入失败。而接收成功记录负载到了正常的主机上,接收记录写入成功。
找到DBA分析原因,发现是异常主机的mysqlrouter配置有问题,修改配置后该问题成功修复(为啥停机前功能正常,这个就是人类未解之谜了)。
# 运维事件发生-永久修改主机名及添加主机名解析ip地址
# 事件描述
测试环境主机的主机名不符合规范,需要修改。同时修改完成后,需要添加相应的主机名解析ip地址功能。
# 事件处理
将事件处理分为修改主机名以及添加主机名解析ip地址两个事件去处理。
# 修改主机名
[root@test215138 /]# vim /etc/sysconfig/network
NETWORKING=yes
# 这里是修改主机名的键值对,修改value即可
HOSTNAME=test215138
# 修改完成后保存,然后重启主机,重启完成后即可生效
[root@test215138 /]# reboot
# 添加主机名解析ip地址
[root@test215138 /]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# 这里添加完ip地址的主机映射后保存即可生效
10.6.1.1 test215138
# 运维事件发生-测试环境安装ElasticSearch
# 事件描述
测试环境迁移,因业务服务依赖ElasticSearch,因此需要再新环境上部署ES服务。
# 事件处理
Elasticsearch下载
~# cd /app
~# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.2.2.tar.gz
Elasticsearch解压
~# tar -zxf elasticsearch-6.2.2.tar.gz -C /app/elasticsearch/
Elasticsearch配置文件修改
~# cd /app/elasticsearch/
~# vim config/elasticsearch.yml
#Centos6不支持SecComp,
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
# 默认的只能本机访问,修改后就可以远程访问了
network.host: 0.0.0.0
network.port: 9200
~# :wq保存
Elasticsearch启动
~# su imodule
# 启动nginx,启动完成后可以看到9200以及9300端口被占用
~# /app/elasticsearch-6.5.1/bin/elasticsearch -d
# 运维事件发生-linux中配置信任自签名证书
# 事件描述
测试环境中,有服务需要通过https请求访问我负责的一个应用,通过代码请求的时候提示“证书不安全”的报错,自己验证,同样是提示证书不安全。
[root@hkdcl025002 ~]# curl -X GET https://km-staff-uat.chinalife.com.hk/api/service-file/file/file-view?id=8c3d1f83-0d4e-40af-84a6-b4ffcb9c4e65
curl: (60) Peer's certificate issuer has been marked as not trusted by the user.
More details here: http://curl.haxx.se/docs/sslcerts.html
# 这里提示的很清楚,该证书不是CA 签发的,所以默认不受信,因此代码报错
curl performs SSL certificate verification by default, using a "bundle"
of Certificate Authority (CA) public keys (CA certs). If the default
bundle file isn't adequate, you can specify an alternate file
using the --cacert option.
If this HTTPS server uses a certificate signed by a CA represented in
the bundle, the certificate verification probably failed due to a
problem with the certificate (it might be expired, or the name might
not match the domain name in the URL).
# 可以在请求的时候增加-k参数跳过证书认证
If you'd like to turn off curl's verification of the certificate, use
the -k (or --insecure) option.
如果是自己写代码的话,可以通过在请求中增加-k参数跳过证书的校验,但是业务系统反馈他们是依赖的三方jar包,没办法对jar包做调整,因此,需要我这边把证书调整为“安全证书”。
咨询了证书的签发同学,他也不了解什么是所谓的“安全证书”,因此,只能自己了解相关知识了。
# 事件处理
问题有三,1.什么是SSL证书? 2.什么是自签发证书,什么是CA证书? 3.如何配置信任自签发证书?
什么是SSL证书?
SSL证书是数字证书的一种,类似于驾驶证、护照和营业执照的电子副本。因为配置在服务器上,也称为SSL服务器证书。
SSL证书就是遵守 SSL协议,由受信任的数字证书颁发机构CA,在验证服务器身份后颁发,具有服务器身份验证和数据传输加密功能。
SSL证书通过在客户端浏览器和Web服务器之间建立一条SSL安全通道(Secure socket layer(SSL)安全协议是由Netscape Communication公司设计开发。该安全协议主要用来提供对用户和服务器的认证;对传送的数据进行加密和隐藏;确保数据在传送中不被改变,即数据的完整性,现已成为该领域中全球化的标准。
个人理解SSL证书就是让第三方对你的网关进行验证(如漏洞扫描),验证完了证明你的网站是安全的,可以给普通用户访问,就会给你一个证书。浏览器在请求你的系统的时候会看看这个证书对不对,对的话就校验通过,不对就给用户提示,即“访问你的网站存在风险”。
什么是自签发证书,什么是CA证书?
自签发证书就是自己生成的证书,不具有太多安全性,CA证书则是由大厂生成的证书,没有安全问题。浏览器会识别证书的签发机构,如果是大的机构,证书就校验完成(如识别到证书是赛门铁克的域名签发的,就是安全的),如果不是大机构的证书(自签发证书),就会给用户提示。
目前大的证书签发机构有Symantec、GeoTrust、Comodo、RapidSSL。一般签发一个证书需要3000元左右/年。

Linux中如何配置信任自签发证书?
在我的使用场景里,证书的签发机构是自己公司,且证书是在内网使用,因此从操作系统层面来看,他就不是一个可信的证书,因此,需要在Linux里自己设置自签发证书为可信证书。
经验证,在麒麟操作系统里将PEM或DER文件格式的证书文件复制到/etc/pki/ca-trust/source/anchors/目录,然后运行update-ca-trust命令即可完成可信证书的配置。
# 在配置可信证书完成后,就不再提示证书不可信了,成功下载了对应的文件
[root@hkdcl025002 app]# wget https://km-staff-uat.chinalife.com.hk/api/service-file/file/file-view?id=8c3d1f83-0d4e-40af-84a6-b4ffcb9c4e65
--2024-03-21 10:27:18-- https://km-staff-uat.chinalife.com.hk/api/service-file/file/file-view?id=8c3d1f83-0d4e-40af-84a6-b4ffcb9c4e65
Resolving km-staff-uat.chinalife.com.hk (km-staff-uat.chinalife.com.hk)... 172.20.25.91
Connecting to km-staff-uat.chinalife.com.hk (km-staff-uat.chinalife.com.hk)|172.20.25.91|:443... connected.
HTTP request sent, awaiting response... 200
Length: unspecified [multipart/form-data]
Saving to: ‘file-view?id=8c3d1f83-0d4e-40af-84a6-b4ffcb9c4e65’
[ <=> ] 28,265 --.-K/s in 0s
2024-03-21 10:27:18 (382 MB/s) - ‘file-view?id=8c3d1f83-0d4e-40af-84a6-b4ffcb9c4e65’ saved [28265]
[root@hkdcl025002 app]# ll -h
total 462M
-rw-r--r-- 1 root root 28K Mar 21 10:27 file-view?id=8c3d1f83-0d4e-40af-84a6-b4ffcb9c4e65
drwxr-xr-x 3 root root 4.0K Oct 18 18:01 home
drwxrwxr-x 5 imodule imodule 4.0K Dec 5 20:37 kmpro
文件上传到Linux后为什么看不到了?
在实际操作过程中,需要将证书放到特定目录/etc/pki/ca-trust/source/anchors/,我在上传了之后却看不到文件,就很奇怪。

其实原因就是证书文件是以“.”号开头的文件,上传完成后隐藏了,需要使用特殊指令才能查看。
[root@hkdcl025002 app]# cd /etc/pki/ca-trust/source/anchors/
[root@hkdcl025002 anchors]# ll -a
total 20
drwxr-xr-x. 2 root root 4096 Mar 21 09:57 .
drwxr-xr-x. 4 root root 4096 Oct 26 2022 ..
-rw-r--r-- 1 root root 1949 Mar 21 10:38 .chinalife.com.hk.key.pem
-rw-r--r-- 1 root root 4782 Mar 21 10:38 .chinalife.com.hk.pem
# 运维事件发生-curl请求报错
# 事件描述
生产发版后需要对服务的部分接口进行验证,在测试环境curl调接口无异常后,将测试数据备份到了变更实施方案(docx文件)中。生产发版完成后验证过程,发现curl接口并没有按预期的结果执行。报错如下:

# 事件处理
生产环境的变更没有达到预期的执行结果,还是很慌的,这时候,鸵鸟心态就来了,一次不行就再执行一次,执行了之后还是没效果。这时候冷静下来了,停一下分析原因,这里像是报一个指令的错,说明不是接口的原因,百度一下,发现有现成的解决方案(Linux执行curl命令报错:No such file or directory (opens new window)),导致这个问题的原因是docx改了空格的文本内容,直接手敲指令,接口按预期结果返回数据。
# 运维事件发生-查看操作系统的crontab
# 事件描述
生产环境需要查看每天定时触发的操作系统脚本,需要执行crontab指令。
# 事件处理
[root@VM-24-3-centos ~]# crontab -l
*/5 * * * * flock -xn /tmp/stargate.lock -c '/usr/local/qcloud/stargate/admin/start.sh > /dev/null 2>&1 &'
# 运维事件发生-查看磁盘空间使用率
# 事件描述
生产环境触发磁盘空间使用率95%的告警,需要分析原因。
# 事件处理
登录对应主机,使用df -h指令查看磁盘空间使用率,发现使用率93%。
[root@VM-24-3-centos ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 19G 0 19G 0% /dev
tmpfs 20G 0 20G 0% /dev/shm
tmpfs 20G 2.0G 18G 11% /run
tmpfs 20G 0 20G 0% /sys/fs/cgroup
/dev/mapper/vg_system-lv_root 35G 13G 21G 38% /
tmpfs 20G 616K 20G 1% /tmp
/dev/vda1 976M 219M 691M 25% /boot
/dev/mapper/vg_tolsapp-lv_tolsapp 196G 172G 15G 93% /app
/dev/vda2 500M 2.5M 498M 1% /boot/efi
tmpfs 3.9G 0 3.9G 0% /run/user/0
tmpfs 3.9G 0 3.9G 0% /run/user/1000
使用du指令查看具体是哪些文件夹使用了这么多的磁盘空间。
[root@VM-24-3-centos ~]# du -h --max-depth=1 /app
# 真实生产环境,这个指令的执行结果不宜展示
# 运维事件发生-Nginx的access.log丢失
# 事件描述
生产环境巡检的时候,发现某台nginx的error.log文件存在,但是没有access.log日志文件。供应商反馈可能是人为删除了该文件,导致文件丢失。
# 测试环境验证
准备一台测试环境主机,找到nginx日志路径,删除access.log文件,同时访问该主机,发现access.log文件并不会重新生成。尝试自己复制一个access.log进去,发现访问日志也并不会写入该nginx。在执行nginx -s reload之后,access.log重新生成并写入(供应商反馈情况确实存在,这个应该和进程占用文件读写权限有关)。
# 事件处理
在生产环境执行nginx -s stop指令,发现nginx进程并没有停止,同时进程号pid变了,很奇怪,尝试kill掉master,发现只剩下worker进程,把所有worker都kill掉之后,新的master进程和worker进程又出现了。(后来发现是keepalived脚本会自动启动nginx)。
在生产环境重启nginx成功后,access.log没有出现,查看nginx.conf配置文件,发现了access.log off;该文件被人为关闭。考虑该文件关闭时间是去年6月,近一年生产问题分析也没拿过这台机的access.log日志,故不做处理。
# history历史指令检索
# 事件描述
需要对history的指令进行检索,故做记录,可以使用ctrl+R快捷键检索历史指令,输入关键词,会检索到一条指令,如果该检索结果不是自己想要的,可以再次使用ctrl+R,就会从指令检索结果里再检索下一条检索结果
# linux中如何查看服务端Socket端口范围以及客户端端口范围
可以通过cat /proc/sys/net/ipv4/ip_local_port_range来查看Socket服务端端口范围以及客户端端口范围,如下:
# 可以看到服务端端口范围是0到32768,客户端端口范围是32769到60999,其中0到1024端口是受保护的,需要root权限操作
[root@VM-24-3-centos ~]# cat /proc/sys/net/ipv4/ip_local_port_range
32768 60999
# linux下如何对服务端执行压测
可以通过ab指令对一个服务端接口进行压测,参考ab压测命令 (opens new window)
# linux下如何修改家目录
默认情况下,用户的家目录的地址是在/home/user路径,如用户howl的家目录是在/home/howl/,其实家目录也是可以修改的,使用如下指令即可:
usermod -d /new/home/username username
# 查看及设置服务开机自启
因运维需要设置某些服务开机自启动,故做记录。
# 查看服务开机自启情况
可以通过如下指令查看服务是否设置了开机自启。
systemctl list-unit-files --type=service | grep enabled | grep 服务名
# 设置服务开机自启
可以通过如下指令设置服务开机自启。
# systemctl enable 服务名,如keepalived.service
systemctl enable keepalived.service
# linux下搜索文件及文本内容
linux查询文件内容关键字 (opens new window)
# 通过jar指令查看jar包内的文件
可以使用如下指令遍历jar包中的文件:
jar -tf my-package.jar
# zookeeper,solr,kafka集群部署方案及未授权访问问题
zk集群作为分布式协调的角色,提供给solr以及kafka作为注册中心以及配置中心使用。
# zk集群搭建
zk集群搭建的核心是在集群的每个节点的配置项中都配置集群所有服务的ip地址以及选举端口,投票端口。
zookeeper超详细安装集群部署_zookeeper集群安装部署 (opens new window)
# zk未授权访问
针对zk的未授权访问,可以使用acl(Access Control List)方案,参见zookeeper--ACL详解 (opens new window)
# solr集群搭建
solr是基于java开发的web服务,功能是全文检索。solr的集群搭建也类似java web服务使用nacos作为分布式服务协调者的场景,在每个服务的配置上配置zk集群的所有节点的ip,端口,同时将solr的配置放到zk做配置中心,参见solr快速上手:搭建solr集群并创建核心,设置数据同步(十一) (opens new window)
# solr-admin未授权访问
针对solr-admin管理端未授权访问的问题,修改配置添加管理员账号密码即可,参见solr-web页面未授权可访问漏洞整改-身份认证授权访问 (opens new window)
# kafka集群搭建
kafka的集群搭建与其他mq基本一致,在配置项里写入所有分布式服务协调者(zk)的ip以及端口,同时指明当前节点的broker信息,参见Kafka集群部署(手把手部署图文详细版) (opens new window)
# kafka未授权访问
kafka默认没有管理端页面,需要加装kafka-manager,目前尚未部署,无需做处理。
# json中添加注释
众所周知,json不允许添加注释,但是实际业务场景里也会有需求要对json添加注释,比如我碰到的场景是熟悉一个前端项目,package.json这个文件里有很多项目模块依赖,启动脚本等信息。如果能添加注释,肯定会对我熟悉项目有所帮助。
# VSCode添加插件
在VSCode中可以添加插件来满足我的这一个使用场景,推荐的插件是JsonComments。
如何为package.json添加注释 (opens new window)
其他方式
除了插件方式,还有如下方式可以给json添加注释
JSON文件加注释的7种方法 (opens new window)
# telnet联通后如何退出
# 事件描述
我们通常会使用telnet ip prots 指令验证与其他服务器的网络策略是否联通,联通后我一般都是多次使用Ctrl+C退出,经常出现无法退出的情况,故搜索了telnet的退出指令。
# 事件处理
telnet联通后,可以通过Ctrl+]进入telnet指令,然后使用Ctrl+D指令退出。
# 使用telnet ip 端口测试连通性
telnet 192.168.0.1 8080
# 联通后,使用Ctrl+]进入telnet指令界面
Ctrl+]
# 在telnet命令下,输入Ctrl+D退出telnet即可,需要特别注意,Ctrl+D不能连续输入,否则会退出Xshell
# 如何查看堆内存及元空间使用情况?
# 安全问题处理-host头攻击
# 事件描述
安全组同事找上门说我负责的系统存在host头攻击,需要针对该问题进行处理。
# 事件处理
安全组同事的说法是在HTTP拦截后,可以修改请求头里的host,服务端收到该host后,会针对host做业务逻辑,如缓存,响应头里添加被篡改的host让客户端浏览器执行301重定向等。 针对该描述,我其实最大的疑问是,既然都能做HTTP拦截了,还能修改host,为啥不直接修改请求本身呢?直接将请求修改到黑客自己的后端服务不就好了吗?
# 为什么能修改请求头的host而不能修改整个请求?
浏览器本质上就是一个客户端,比如我们玩电脑游戏的客户端,这个客户端当然有它自己的"反外挂机制",体现在浏览器上就是不能修改HTTP请求本身,只允许修改请求头/请求体。如果某用户下载了一个外挂,如翻墙插件等,他的浏览器就很可能感染病毒,病毒会自动修改请求头中的host,如果这时用户访问我们的后端服务的话,我们的后端服务就会被攻击,或者是我们重定向301的地址会被修改,用户在不知情的情况下就会跳转到假站点。
# HOST头攻击的危害
Host头攻击的危害主要包括以下几个方面:
1. 缓存污染:
危害描述:如果Web服务器使用Host头部字段来确定缓存的键,攻击者可能会发送恶意请求来污染缓存。这会导致其他用户从缓存中获取到错误或恶意的内容,进而造成信息泄露或执行恶意代码的风险。
示例场景:攻击者发送一个包含恶意Host值的请求,服务器将其内容缓存。随后,其他用户访问相同资源时,会从缓存中获取到攻击者注入的恶意内容。
2. 跨站脚本攻击(XSS):
危害描述:如果Web应用程序在响应中直接包含了未经适当转义或过滤的Host头部字段的值,攻击者可能会注入恶意脚本。当受害者的浏览器执行这些脚本时,攻击者可以窃取敏感信息、进行会话劫持或执行其他恶意操作。
示例代码:
在下面的代码中,如果攻击者将Host头字段设置为<script>alert('XSS');</script>,则受害者的浏览器会执行该脚本,导致XSS攻击。
php
Copy Code
<?php
$host = $_SERVER['HTTP_HOST'];
echo "Welcome to " . $host . "!"; // 未对$host进行转义或过滤,存在XSS风险
?>
3. Open Redirect:
危害描述:如果Web应用程序使用Host头部字段来构建重定向URL且未进行有效验证,攻击者可能会将用户重定向到恶意网站。这可能导致钓鱼攻击、安装恶意软件或进行其他欺诈活动。
示例场景:攻击者发送一个包含恶意Host值的请求,Web应用程序构建了一个重定向URL,并将用户重定向到攻击者控制的恶意网站。
4. 数据泄露和服务器劫持:
危害描述:通过伪造Host头字段,攻击者可能欺骗服务器获取未经授权的敏感信息,如用户凭证或个人数据。在严重的情况下,攻击者甚至可能实现对服务器的控制或篡改。
示例场景:攻击者发送一个包含管理员域名(如admin.example.com)的Host头字段的请求,如果服务器未进行验证,则可能返回管理员界面的内容,进而泄露敏感信息或允许攻击者执行管理员操作。
5. 跨站请求伪造(CSRF):
危害描述:攻击者可以通过修改Host头字段来伪装成合法的域名,诱使用户在当前会话中执行恶意请求。这可能导致用户在不知情的情况下执行了攻击者指定的操作,如更改账户设置、发送敏感信息等。
示例场景:攻击者构造一个包含恶意Host头字段的请求,并诱使用户点击一个链接或提交一个表单。当请求发送到服务器时,服务器会将其视为来自合法域名的请求,并执行相应的操作。
为了防范Host头攻击,建议采取以下措施:
- 验证和清理Host头值,确保其符合预期的格式和长度。
- 使用安全的编程语言和框架,减少潜在的安全漏洞和攻击面。
- 实施CSRF防护措施,如使用随机生成的令牌进行身份验证。
- 定期更新和修补服务器和应用程序的漏洞,以减少攻击者利用Host头攻击的机会。
- 配置Web服务器以识别和拒绝恶意请求,如禁止空主机头请求或限制Host头字段的值。
参考资料:Host头攻击 (opens new window)
# 如何查看Nginx的安装路径
进入Nginx的sbin目录,可以通过nginx -V查看nginx的安装详情
# 配置域名解析服务器地址及验证
# 为文件增加写入权限
chattr -i /etc/resolv.conf
# vim指令修改文件增加如下配置
vim /etc/resolv.conf
# 域名解析服务器地址
nameserver 10.6.10.10
# 移除文件的写入权限
chattr +i /etc/resolv.conf
# 使用nslookup指令验证域名解析结果
nslookup www.qq.com
# 查看当前有多少进程在使用内存,根据内存使用量倒排
top -o RES