# Java面试总结
# 集合
# List和Set的区别?
List和Set都是Java提供的集合接口,List的特点是有序(按对象进入顺序保存对象)、可重复,Set的特点则是无序、不可重复。 常见的List集合实现有ArrayList、LinkedList。常见的Set实现有HashSet、TreeSet。
# ArrayList和LinkedList的区别?
- ArrayList底层基于数组实现(如果往集合中填充元素的时候,发现数组已满,就会执行扩容操作,扩容后的容量是扩容前的1.5倍),LinkedList底层基于链表实现。
- 两者之间在增删改查的时间复杂度上存在显著差异,如随机查找ArrayList的时间复杂度是O(1),LinkedList的时间复杂度是O(n)。
- 实际开发中,我们大部分情况下更关注的是查找的性能,因此用到的比较多的是ArrayList,除非是碰到了Queue队列的场景才会使用LinkedList(LinkedList底层实现了Deque接口,可以充当队列使用)。
# JDK8中HashMap如何实现?
HashMap使用数据+链表+红黑树实现,当元素放入HashMap的时候,首先会计算哈希来决定数据应该存放在数据的哪个下标,如果此时发现插入后数组的75%都有数据了,那么就会将数据长度做扩容(长度变为原来的2倍),所有元素都需要重新存放。如果发现存放后不会超过75%,则存放到对应的数组下标中,如果下标中也有数据了,那么就会以链表存放元素,如果链表长度超过8,则会将链表调整为红黑树,反之如果是从HashMap中移除元素,如果发现移除后红黑树长度小于7,又会退化成链表。
# JDK8中ConcurrentHashMap如何实现?
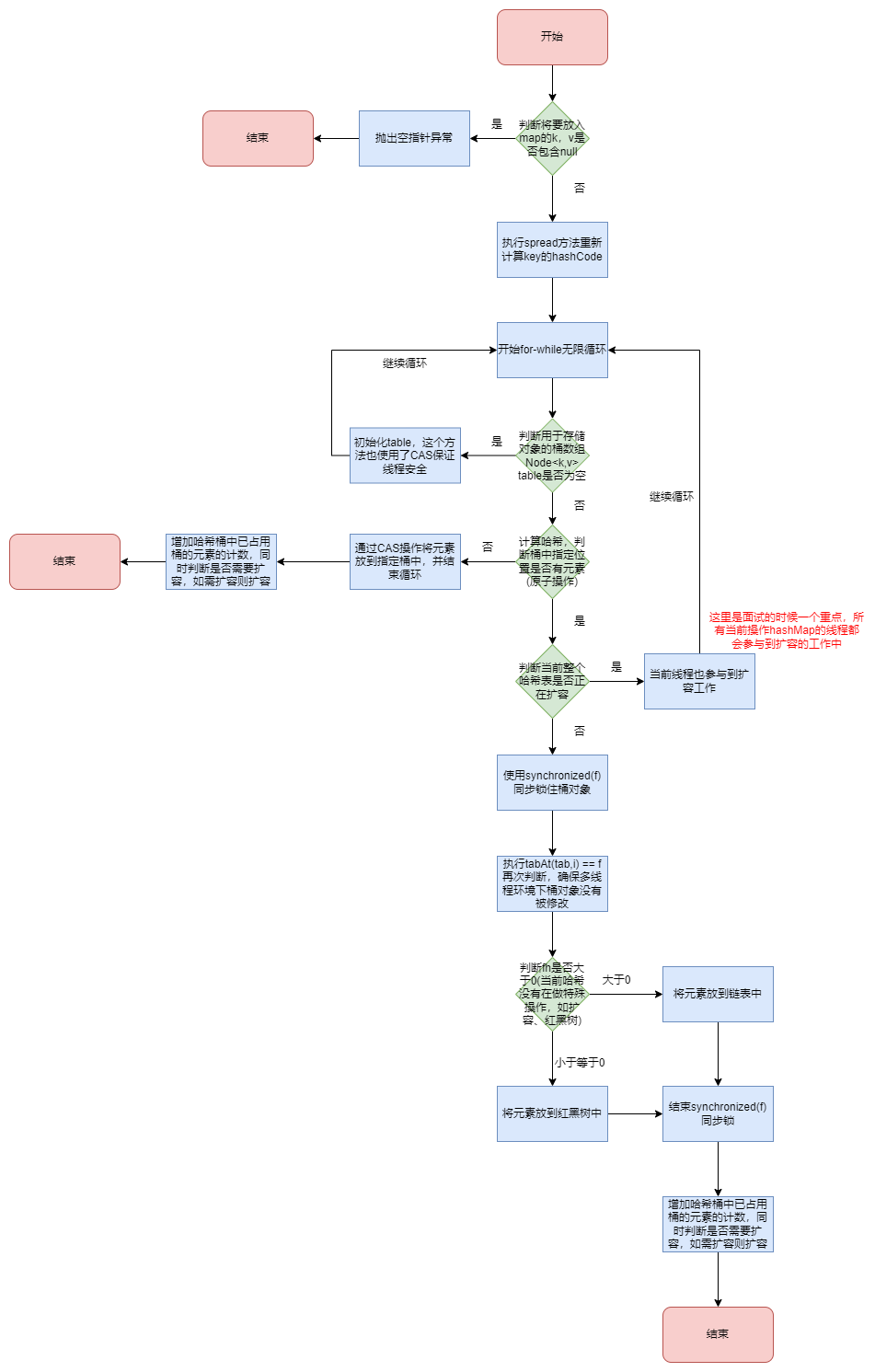
之所以强调JDK8是因为JDK7中ConcurrentHashMap使用的是分段锁来实现,在JDK8中,ConcurrentHashMap的同步机制则调整成了synchronized同步关键字以及CAS实现(下面是jdk8中向ConcurrentHashMap插入元素的流程图)。需要特别注意的是,ConcurrentHashMap中如果识别到需求扩容,所有当前操作的线程都会参与到扩容这个事项中来。
# 异常
# java异常分类
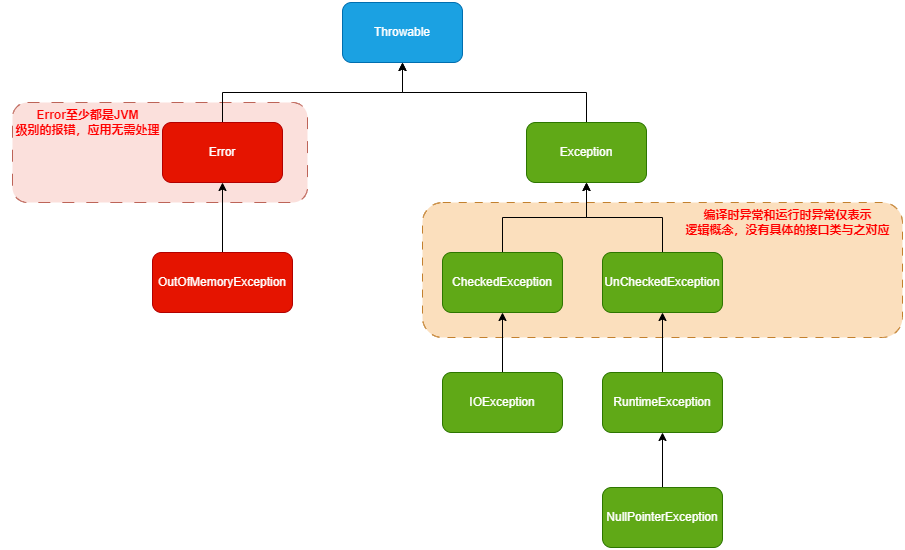
- java中所有异常均继承自Throwable,Throwable有两个实现,分别是Error以及Exception。
- Error代表系统级别异常(JVM级别/操作系统级别异常,应用本身无法处理,也无需处理)。
- Exception异常则分为编译时异常(受检异常CheckedException),以及运行时异常UncheckedException(RuntimeException及其子类),其中RuntimeException可以捕获后处理,也可以不捕获,编译器不会给任何提示,更不会导致编译失败。编译时异常则不同,如果未在编译时对这类异常做处理(捕获/在方法定义中使用throws关键词抛出)的话,编译会报错(提示你需要关注这类异常,并且对他们做处理)。
# 异常日志如何打印
// 日志对象,通过AIController的类的class的name(字符串)参数去找log,根据log去找append,最终输入到append中
private static Logger logger = LogManager.getLogger(AIController.class);
try{
// 业务代码
// 模拟抛出IO异常
throw new IOException("IO异常啦");
}catch (IOException e){
// 打印内容到控制台,绝对不要这样写,这里的动作是把日志打印到控制台,环境上是用linux的后台进程跑的,显然没有控制台啦
// 不打这行开发环境咋看日志呢???开发环境有控制台的呀
// 但是是日志对象的append,其中一个append就是console,所以开发环境控制台能看到异常栈
// <root level="info">
// <appender-ref ref="STDOUT"/>
// <appender-ref ref="FILE"/>
// </root>
// <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"></appender>
// 很明显,针对测试/生产环境的配置,STDOUT 这个appender应该移除,然而我自己的项目里没移除
// https://blog.csdn.net/dingjs520/article/details/123739514
e.printStackTrace();
// 异常打印方式1:
// 打印完整异常栈及异常信息 1.请求AI服务异常:{}
// 接下来是异常栈
logger.info("1.请求AI服务异常:{}", e);
// 异常打印方式2:
// 打印完整异常栈及异常信息 1.请求AI服务异常:
// 接下来是异常栈
// 可以看出来打印方式1多出来一个无效的{},因此推荐使用这种方式
logger.info("2.请求AI服务异常:", e);
// 3.请求AI服务异常:IO异常啦
// 打印信息过少 3.请求AI服务异常:IO异常啦
logger.info("3.请求AI服务异常:{}", e.getMessage());
// 4.请求AI服务异常:IO异常啦,java.io.IOException: IO异常啦
// 同样打印信息过少
logger.info("4.请求AI服务异常:{},{}", e.getMessage(),e);
}
特别说明
- 不要通过JSON将对象转为json再打印到日志(转换过程影响性能,且极易报错),推荐重写对象的toString()方法
- 可以通过手写工具类来输出完整的异常栈日志中如何输出完整的堆栈异常 (opens new window)
- 捕获异常后重新抛出的几种方式java如何重新抛出异常并保留原始堆栈? (opens new window)
# 多线程
# Java中有三种方式创建线程,分别是?
# 直接继承Thread类创建线程
通过继承Thread类,重写run()方法,创建线程对象并执行start()方法来创建线程,这种方式没有任何优点,缺点是线程类无法再继承其他对象,实际项目里禁止使用这种方式创建线程。
package com.kieoo.interview;
/**
* 通过继承Thread类来实现线程,重写的是run()方法而不是start()方法,同时
* 因为Java中的类是单继承,以这种方式实现的线程就不支持继承其他类了
*
* @author xuhaodi
*/
public class MyThread extends Thread {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
}
@Override
public void run() {
System.out.println("MyThread execute");
}
}
# 实现Runnable接口创建线程
通过实现Runnable接口,实现run()方法的方式来创建线程,推荐使用。
package com.kieoo.interview;
/**
* 实现Runnable接口及接口中的run()方法,通过
* 创建new Thread()对象并在构造器中提供当前类实例的方式创建线程。
*
* @author xuhaodi
*/
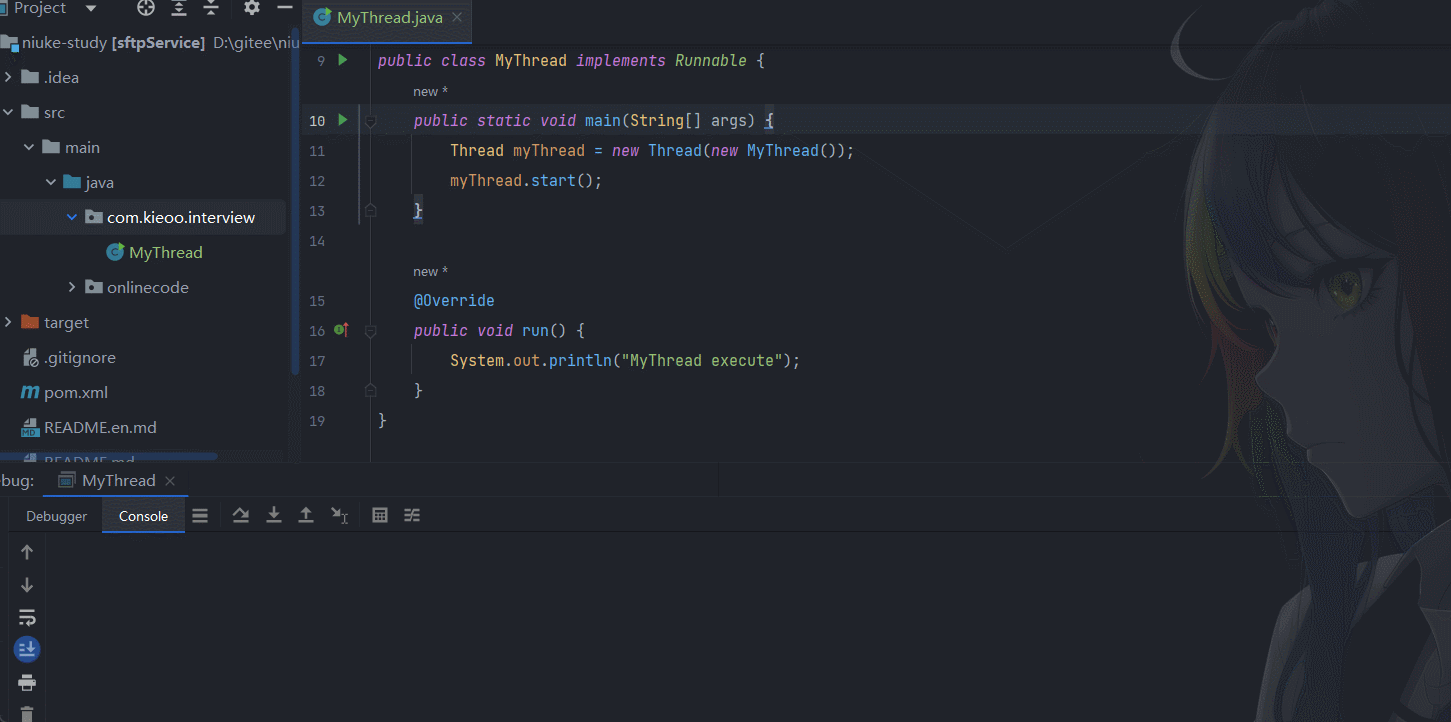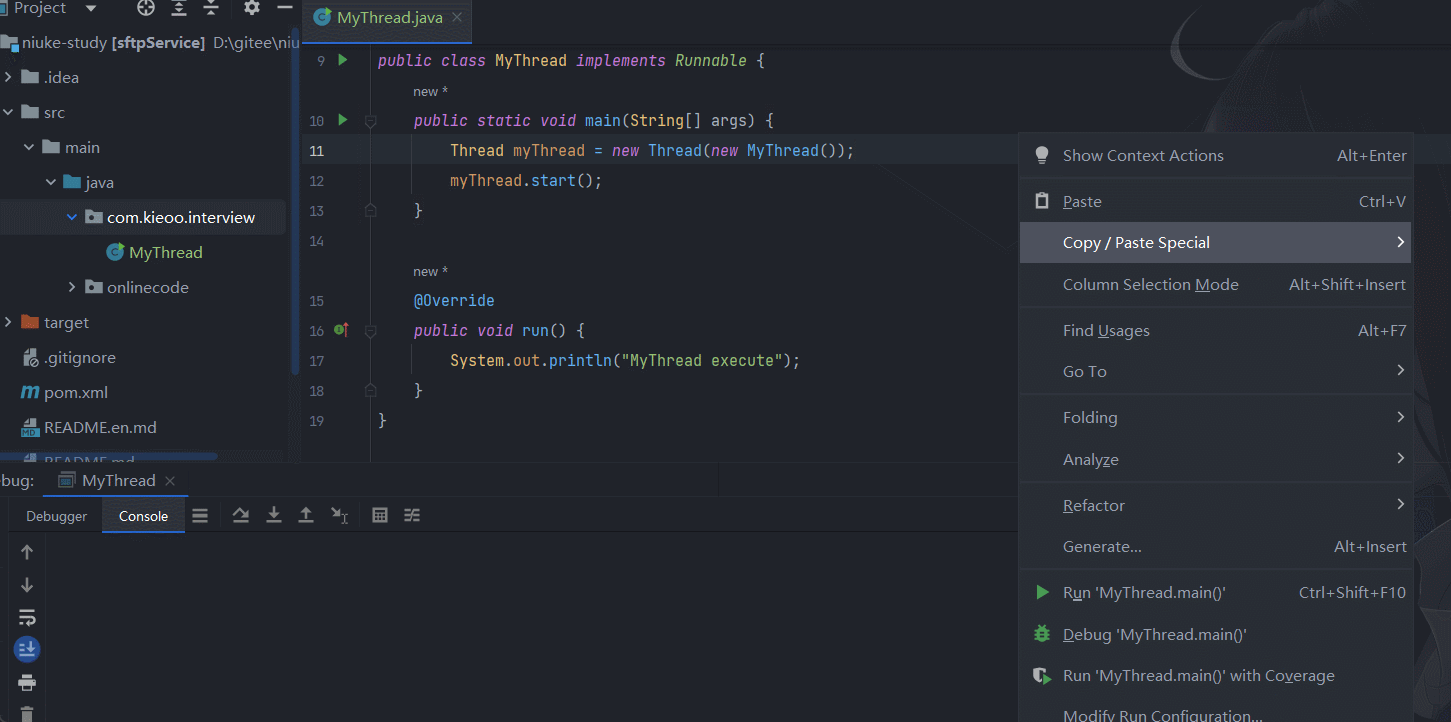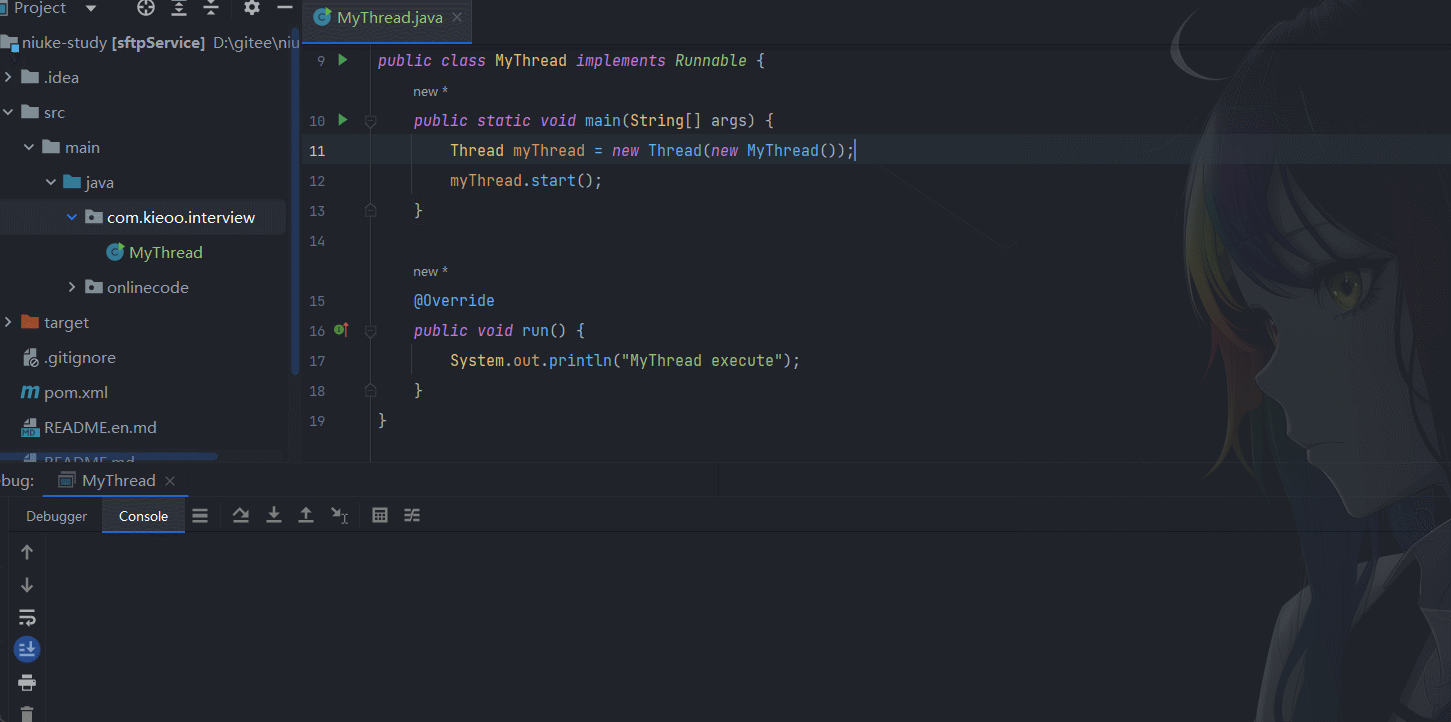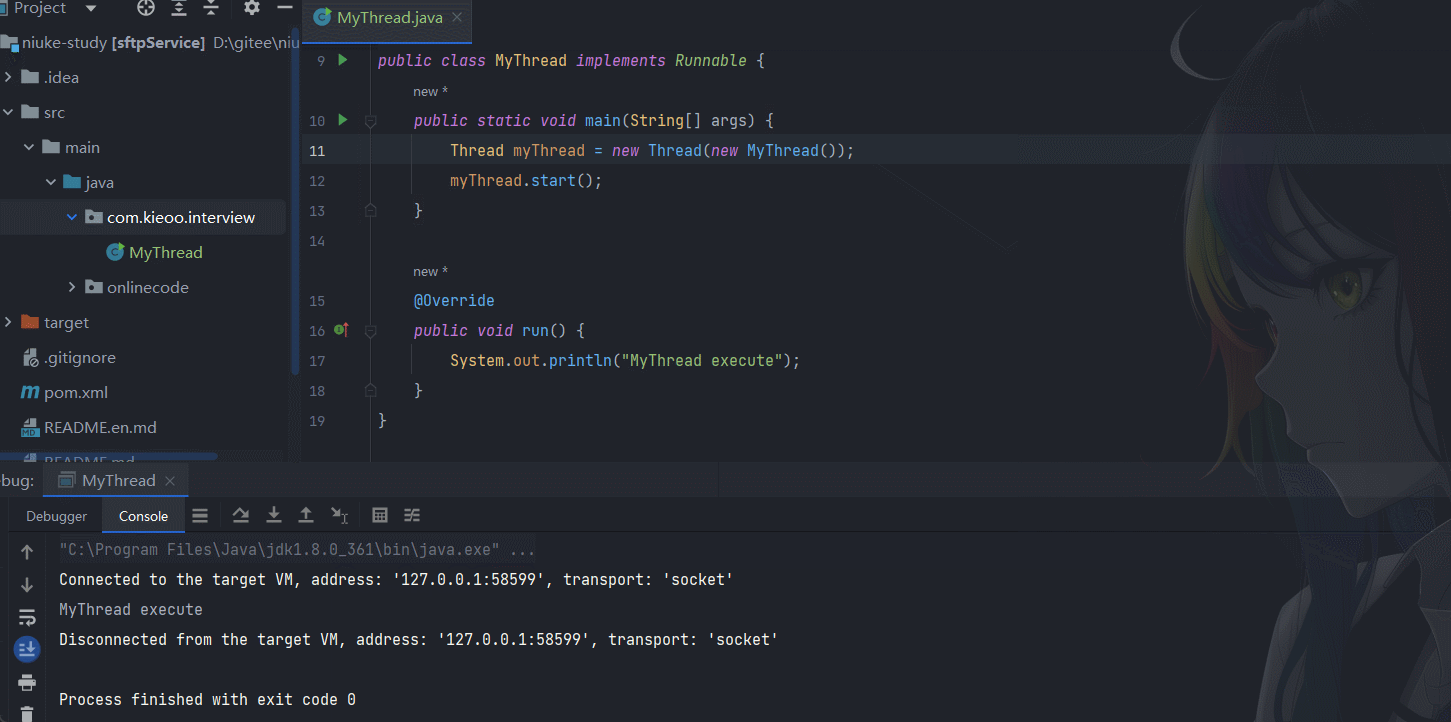
public class MyThread implements Runnable {
public static void main(String[] args) {
Thread myThread = new Thread(new MyThread());
myThread.start();
}
@Override
public void run() {
System.out.println("MyThread execute");
}
}
# 实现Callable接口创建线程
Callable接口和Runnable的区别是,Runnable接口里线程异步执行,当前线程不需要获取子线程的结果,而Callable接口配合FutureTask使用,FutureTask会阻塞当前线程,最终获取到Runnable线程(子线程)的返回结果。
package com.kieoo.interview;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
/**
* 实现Callabe接口及接口中的call()方法,同时结合使用FutureTask类获取线程的执行结果
*
* @author xuhaodi
*/
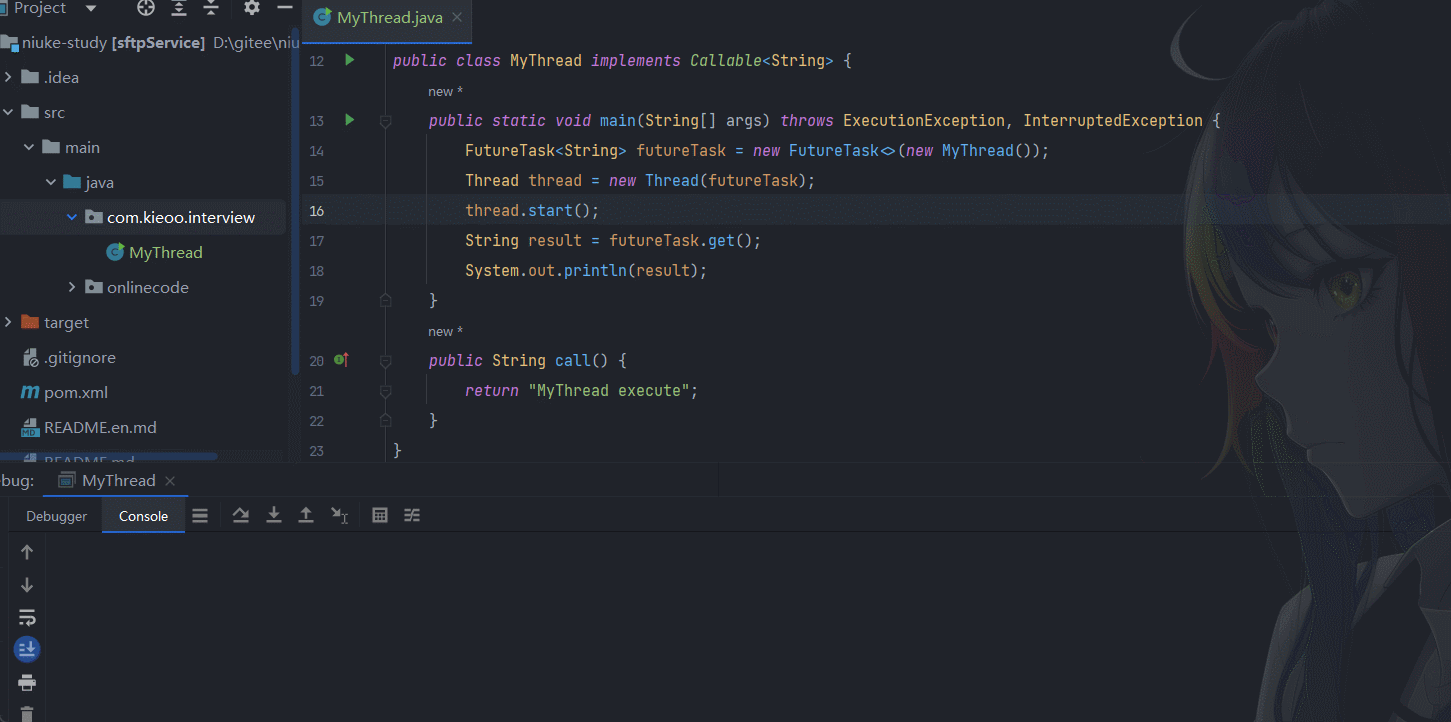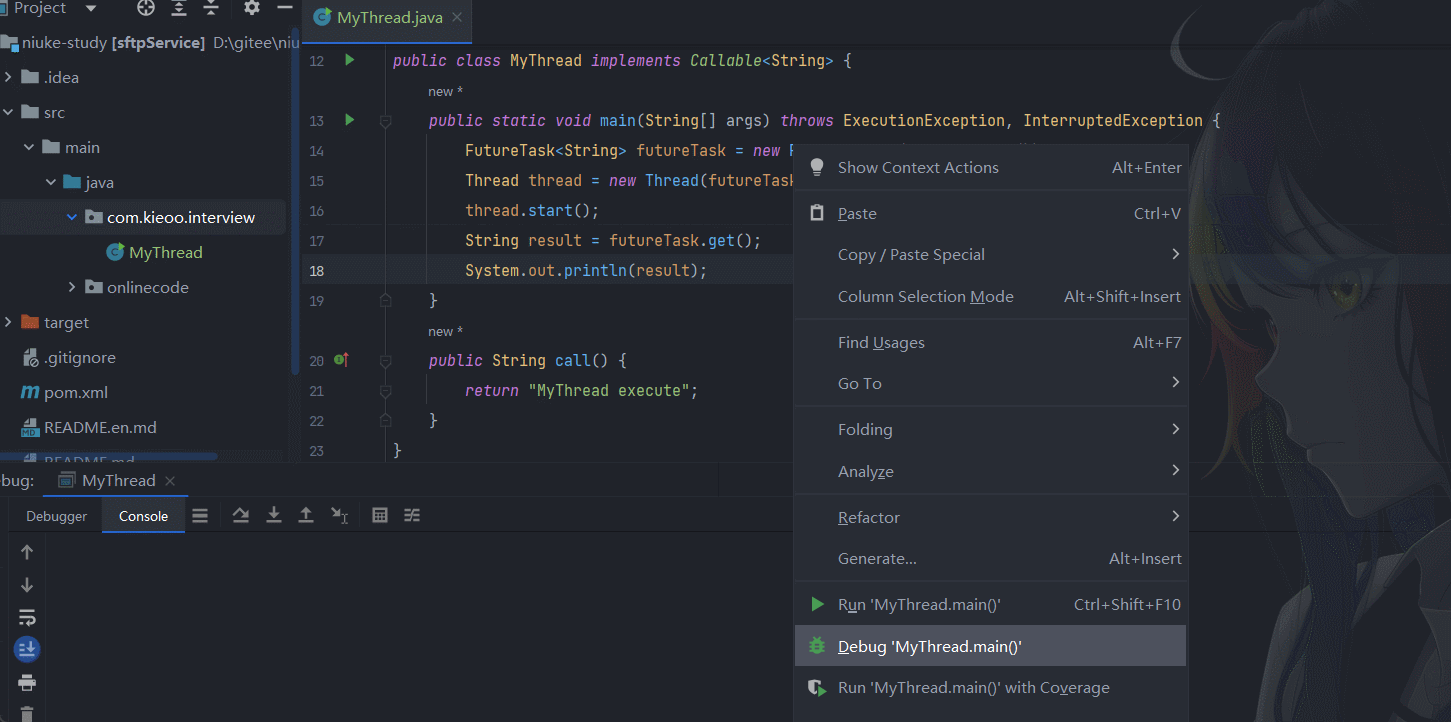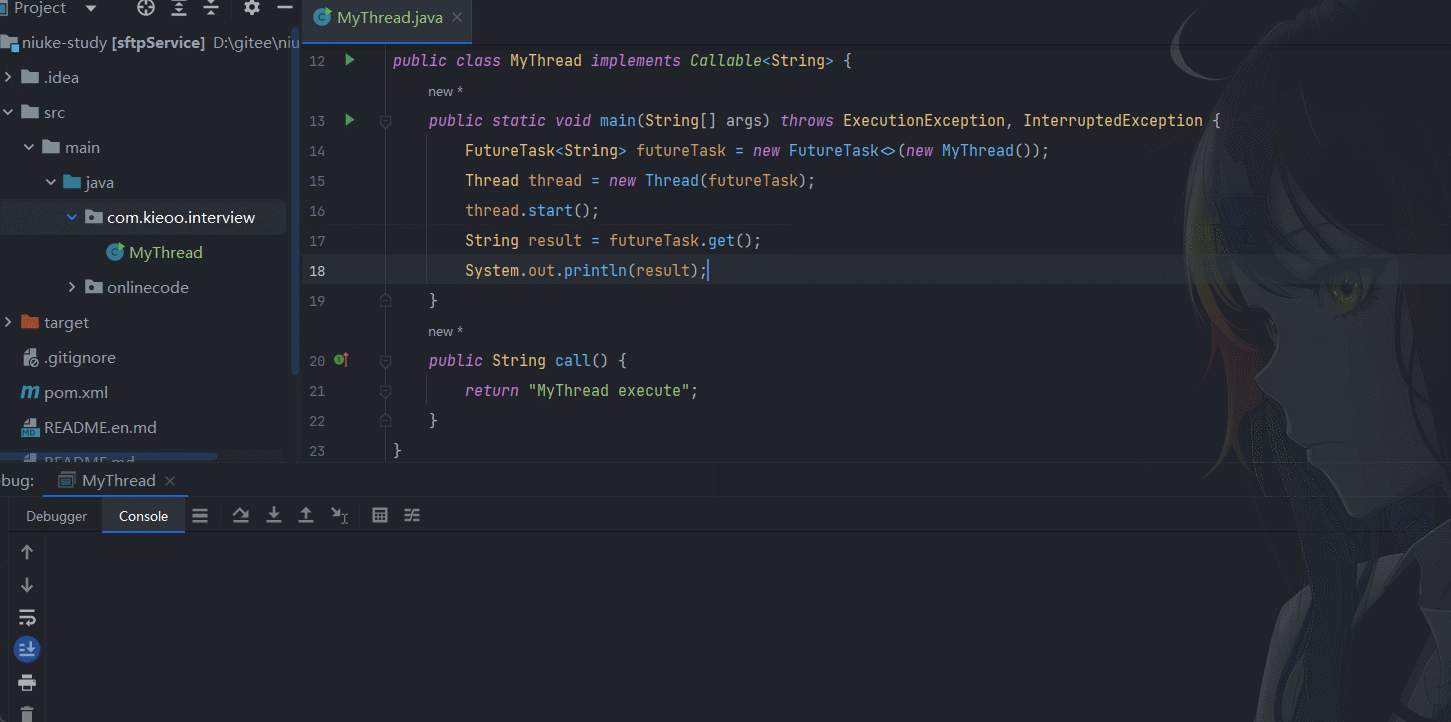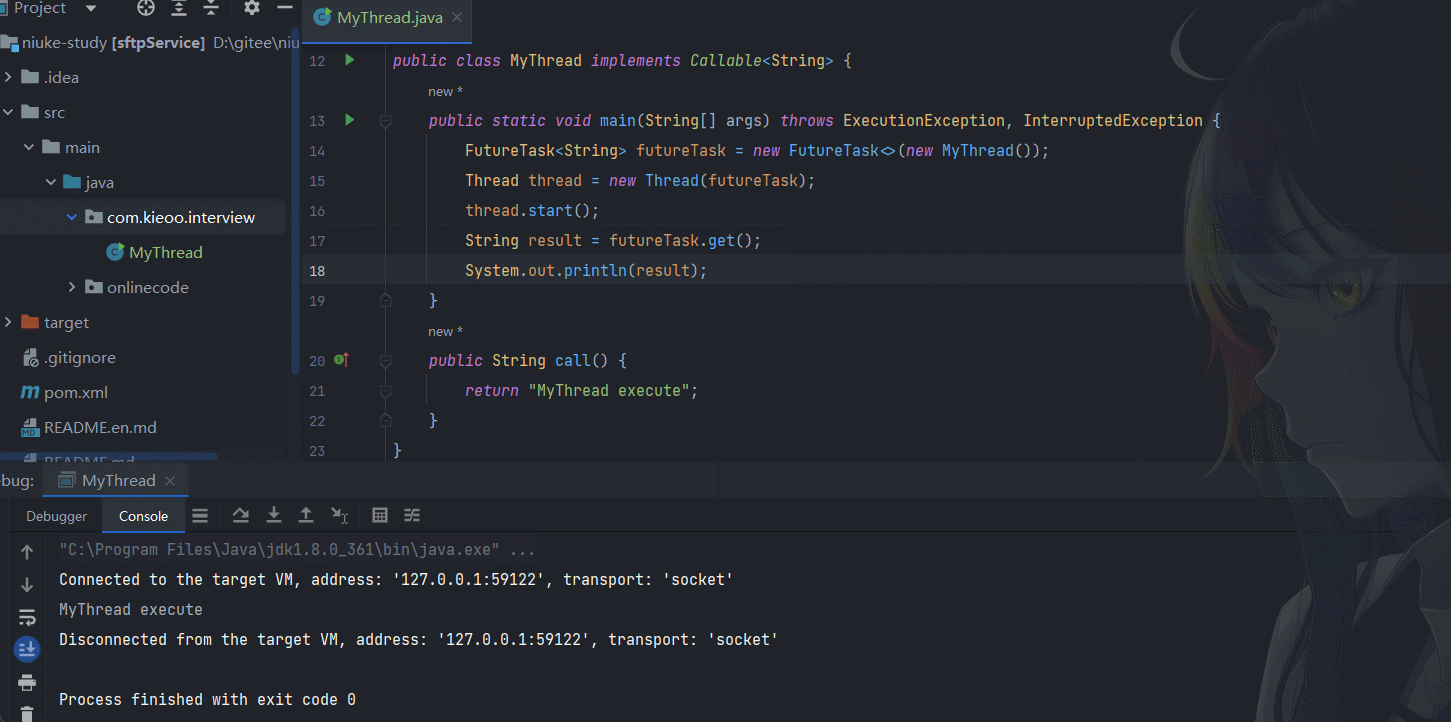
public class MyThread implements Callable<String> {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> futureTask = new FutureTask<>(new MyThread());
Thread thread = new Thread(futureTask);
thread.start();
String result = futureTask.get();
System.out.println(result);
}
public String call() {
return "MyThread execute";
}
}
# 为什么不建议使用Executors来创建线程池?不用Executors那要用什么呢?
# 为什么不建议使用Executors来创建线程池?
Executors是java提供的一个线程池工具类,这个工具类提供了很多方便易用的线程池模型,如固定线程池(FixedThreadPool)、单线程池(SingleThreadExecutor)、缓存线程池(CachedThreadPool)、定时线程池(ScheduledThreadPool)。有利就有弊,这些工具类在方便我们的同时也隐藏了一些细节(底层数据结构的队列默认长度是Integer.MAX_VALUE),在项目投产运行过程中线上经常会出现线程池导致的OOM问题或CPU过载问题,因此不推荐使用。
FixedThreadPool 和 SingleThreadPool:
允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。CachedThreadPool 和 ScheduledThreadPool:
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
# 不用Executors那要用什么线程池呢?
在不使用Executors的情况下,我们可以使用java提供的另一个线程池工具ThreadPoolExecutor,使用ThreadPoolExecutor需要我们设置corePoolSize:核心线程数,maximumPoolSize:最大线程数,workQueue:工作队列,handler:拒绝策略等配置,因此使用ThreadPoolExecutor不容易出现线程池相关问题。
考虑到我们的开发生态是Spring,推荐使用Spring提供的ThreadPoolTaskExecutor线程池,这个线程池是基于ThreadPoolExecutor实现的,在Spring容器中以单例Bean存在,可以很好的与@Async、事务管理等 Spring 特性配合使用时。
补充说明
1.在我目前所负责开发的项目中,由于项目本身是微服务架构,且已经迭代到了v7版本,存在Executors、ThreadPoolExecutor、ThreadPoolTaskExecutor混用的情况。
# 线程池有哪些关键参数?如何设置这些参数呢?
# 关键参数
名称定义
线程池的名称对问题定位至关重要,必须要为线程池指定线程名称。核心线程数
corePoolSize:核心线程数,即使线程空闲也不会被回收,除非设置allowCoreThreadTimeOut。最大线程数
maximumPoolSize:最大线程数,当工作队列满了之后,可以创建的最大线程数。拒绝策略
handler:拒绝策略,当线程池和队列都满了之后,如何处理新提交的任务。
# 设置参数的核心原则
明确配置所有参数,使用有界队列,设置合理的拒绝策略,并给线程命名以便监控和排查问题。
# 线程池有四种拒绝策略,分别是?
# 直接报错
AbortPolicy(默认策略):抛出异常,拒绝新任务
# 由调用者线程执行任务
CallerRunsPolicy:调度者线程相当于线程池里负责协调任务的线程,由它负责执行新的任务的话,会降低新任务提交速度,起到削峰填谷作用。生产环境推荐使用。
# 静默丢弃新任务
DiscardPolicy:直接丢弃新任务,不抛异常,无任何通知
# 丢弃队列中最旧的任务
DiscardOldestPolicy:丢弃队列中最旧的任务
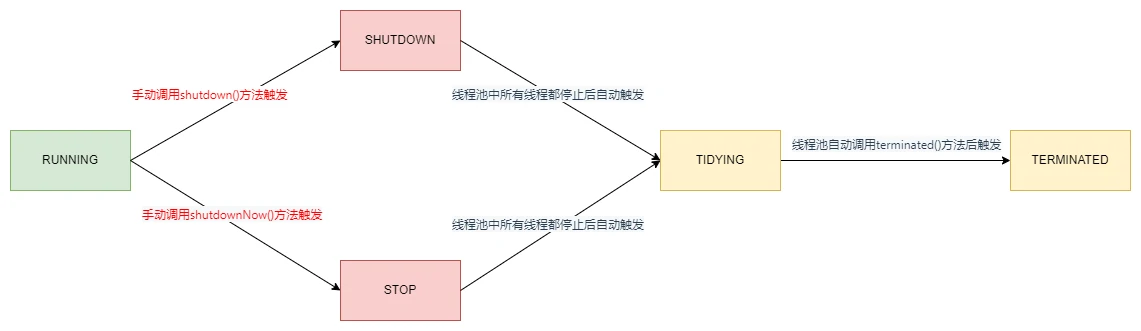
# 线程池有几种状态?分别是如何变化的?
线程池有五种状态,分别是:
| 状态 | 说明 |
|---|---|
| RUNNING | 表示线程池正常运行,会接收新任务并且会处理队列中的任务 |
| SHUTDOWN | 不会接收新任务并且会处理队列中的任务,任务处理完会中断所有线程 |
| STOP | 不会接收新任务并且不会处理队列中的任务,并且会直接中断所有线程 |
| TIDYING | 所有线程都停止了之后,线程池的状态就会变成TIDYING,一旦到达此状态,就会调用线程池的terminated()方法,这个方法是一个空方法,留给程序员进行扩展。 |
| TERMINATED | terminated()方法执行完之后状态就会变成TERMINATED |
这五种状态不能随意转换,只会有以下几种转换情况:
| 转换前 | 转换后 | 转换条件 |
|---|---|---|
| RUNNING | SHUTDOWN | 手动调用shutdown()方法触发 |
| RUNNING | STOP | 手动调用shutdownNow()方法触发 |
| SHUTDOWN | TIDYING | 线程池中所有线程都停止后自动触发 |
| STOP | TIDYING | 线程池中所有线程都停止后自动触发 |
| TIDYING | TERMINATED | 线程池自动调用terminated()方法后触发 |
线程池状态转换图如下:
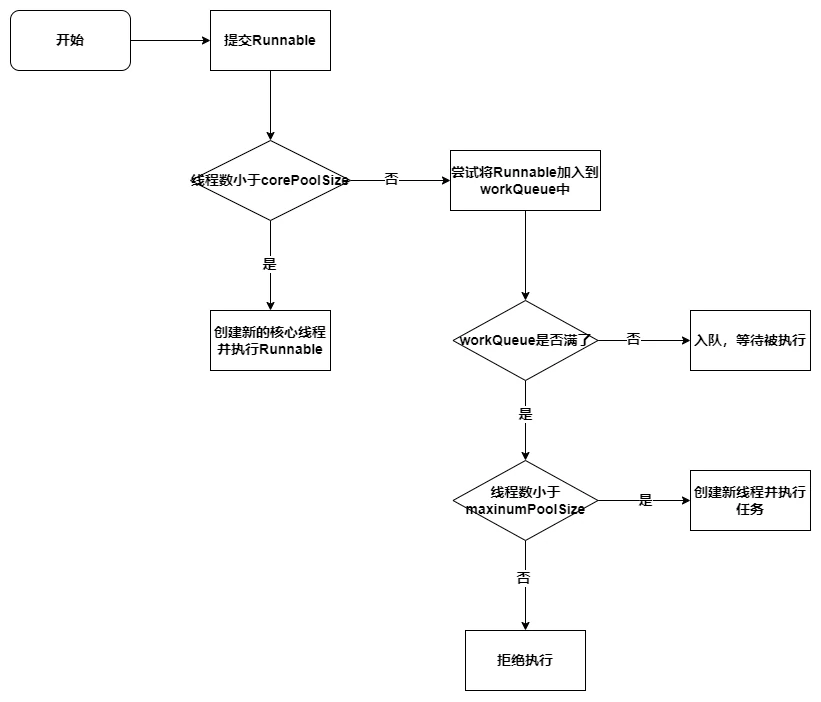
# 线程池中提交一个任务的流程?
1)使用execute()方法提交Runnable对象
2)判断线程池中当前线程数是否小于corePoolSize核心线程数
3)如果小于,创建新的核心线程并执行Runnable
4)如果大于等于,则尝试将Runnable加入到workQueue工作队列中
5)如果workQueue没满,则将Runnable正常入队,等待执行
6)如果workQueue满了,则会入队失败,线程池会继续尝试增加线程
7)判断当前线程池中的线程数是否小于maxinumPoolSize
8)如果小于,则创建新线程并执行任务
9)如果大于等于,则执行拒绝策略,拒绝此Runnable
对应的流程图如下:
# 线程池中核心线程数,最大线程数如何设置?
线程池负责执行的任务可以分为三种类型,分别是CPU密集型任务,IO密集型任务以及混合型任务。
# 设置核心线程数
- CPU密集型任务
特点:这类任务主要消耗CPU资源,很少进行I/O操作,如复杂的计算任务。
设置策略:线程池大小建议设置为CPU核心数+1(可以通过Runtime.getRuntime().availableProcessors();获取CPU核心数)。因为对于CPU密集型任务,增加线程数量并不能提高执行效率,反而可能导致线程上下文切换的额外开销,降低系统性能。CPU核心数+1的策略可以在多核CPU上尽可能利用CPU资源的同时,保留一定余地处理系统任务调度。
- CPU密集型任务
- IO密集型任务
特点:这类任务执行过程中,大部分时间都在等待I/O操作完成,如文件读写、网络通信。
设置策略:
方法一:推荐线程池大小设置为CPU核心数*2。由于I/O操作不占用CPU,增加线程可以让CPU在等待I/O时处理其他任务,提升CPU利用率。
方法二:更精细的计算方法是根据线程CPU运行时间和等待时间的比例来确定。公式为:((CPU时间占比 + 等待时间占比) / CPU时间占比) * CPU核心数。例如,如果每个线程CPU运行0.5秒,I/O等待1.5秒,那么线程数为((0.5+1.5)/0.5)*8=32。简化公式为:最佳线程数 = (等待时间与CPU时间比 + 1) * CPU核心数。
- IO密集型任务
- 混合型任务
特点:既包含CPU密集操作也包含I/O操作。
设置策略:针对这种情况,较为理想的做法是将任务拆分为CPU密集型和IO密集型,分别使用专门的线程池处理。这样可以根据各自的特点,按照上述原则分别设置合适的线程数。如果拆分困难,可以评估任务中CPU和I/O操作的比例,折中选取一个相对平衡的线程池大小。
- 混合型任务
# 设置最大线程数
最大线程数一般设置为核心线程数的2~3倍,这个数值是不固定的,可以通过压测等操作来确定合适的最大线程数。
补充说明-实际项目中如何设置
1.在我负责的项目中,有两个微服务使用了Spring的ThreadPoolTaskExecutor线程池,他们分别是如下设置:
// 核心线程=CPU核心数+1
// 最大线程数=核心线程数*2
@Bean
public Executor convertPool(){
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(5);
threadPoolTaskExecutor.setMaxPoolSize(10);
threadPoolTaskExecutor.setQueueCapacity(99999);
threadPoolTaskExecutor.setThreadNamePrefix("file-convert-");
// 拒绝策略-由调度者线程负责执行该任务
threadPoolTaskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
threadPoolTaskExecutor.initialize();
return threadPoolTaskExecutor;
}
// 核心线程数=动态获取的CPU核心数
// 最大线程数=核心线程数*2
@Bean
public ThreadPoolTaskExecutor threadPool() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(Runtime.getRuntime().availableProcessors());
executor.setMaxPoolSize(Runtime.getRuntime().availableProcessors() * 2);
executor.setQueueCapacity(1000);
executor.setKeepAliveSeconds(300);
// 拒绝策略:默认策略-抛出异常
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
executor.initialize();
return executor;
}
# synchronized的底层实现原理是什么?
synchronized的底层实现原理是monitor(可翻译为监视器也可以翻译为管程),每一个类对象以及实例对象创建后,在对象头里都会创建一个引用,该引用指向一个monitor对象,想要执行synchronized代码块及方法,就必须要获取到monitor的锁。管程由操作系统/JVM提供,由JVM保证同一时间仅一个线程可操作管程。
什么是管程
管程是一种进程同步互斥工具,属于操作系统中的概念。它提供了一种机制,用于确保多个进程或线程在访问共享资源时的互斥性和同步性。管程的基本特征包括互斥性、封装性、条件等待、条件通知、可阻塞性和公平性。这些特征使得管程成为一种强大的并发编程机制,可以简化并发程序的编写和调试过程,并提供良好的线程或进程间的协作方式。管程对应jdk提供的monitorenter以及monitorexit原语。
# Synchronized同步关键字和ReentrantLock的区别?
| Synchronized同步关键字 | ReentrantLock可重入锁 |
|---|---|
| Java中的一个关键字 | JDK提供的一个类 |
| 自动加锁与释放锁 | 需要手动加锁和释放锁 |
| JVM层面的锁 | API层面的锁 |
| 非公平锁 | 公平锁/非公平锁 |
| 锁的是当前对象,锁信息保存在对象头中 | int类型的state标识来标识锁的状态 |
| 底层有锁升级过程 | 没有锁升级过程 |
项目中哪些地方用到了synchronized
看了下项目,没用到,所以自己写一个
public class Test {
private String node;
// 在方法上使用,锁当前实例对象
public synchronized void method(){
// 在代码块使用,锁当前实例对象
synchronized (this){
node++;
}
}
// 在静态方法使用,锁类对象Test.class
public synchronized static void staticMethod(){
// 在代码块中使用,锁类对象Test.class
synchronized (Test.class){
node++;
}
}
}
项目中哪些地方用到了ReentrantLock
项目中在消息队列消费消息时使用了可重入锁
@Override
public void listen(String message, String topic, String tag) {
try {
lock.lock();
logger.info("service-point::::::::::接收到MQ消息topic={}, tags={}, 消息内容={}", topic, tag, message);
//部门相关操作事件
if ("department".equals(topic)) {
departmentConsume.consume(message, topic, tag);
}
/**
* tag:createPointConfig||createPointItem
*
*/
if ("point".equals(topic)) {
if ("initRootPointConfigAndItem".equals(tag)) {
pointConsume.consume(message, topic, tag);
}
if ("addPoints".equals(tag)) {
pointConsume.consumeAddPoints(message, topic, tag);
}
//2-扣除,3-返还,4-增加 悬赏分
if ("deductionOrReturn".equals(tag)) {
pointConsume.deductionOrReturn(message, topic, tag);
}
}
} finally {
lock.unlock();
}
}
# 公平锁和非公平锁的区别?
# 公平锁
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
// 正常获取锁
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
// 获取state
int c = getState();
// 为0代表没有资源获取到锁
if (c == 0) {
// 检查队列中是否有比当前线程等待更久的线程
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// 重入逻辑,检查当前线程是否是持有锁的线程
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
# 非公平锁
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* Performs lock. Try immediate barge, backing up to normal
* acquire on failure.
*/
/**
* 尝试执行一个判断state是否为0,如果是,将其改成1的原子操作,如果操作成功,立刻获取锁
* 如果获取锁失败,则使用正常的方式获取锁
*/
final void lock() {
if (compareAndSetState(0, 1))
// 将当前线程设置为独占模式下的锁持有者。这样,在重入锁的时候,就可以检查当前线程是否是锁的持有者,从而允许重入。
setExclusiveOwnerThread(Thread.currentThread());
else
// 这里获取锁的时候会调用tryAcquire(int acquires);
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
// 调用父类的非公平获取锁方法
return nonfairTryAcquire(acquires);
}
}
# ThreaLocal有哪些使用场景?
ThreadLocal底层会将ThreadLocal数据存储在线程栈内存中,当前线程可以在任意时刻,任意方法中获取ThreadLocal中的信息。
仅在当前线程中会使用的数据,可以放在ThreadLocal中,如用户信息,线程日志每个线程中唯一,且不会在不同线程间共享,就可以存储在ThreadLocal中。
补充说明
在我参与的项目中,在日志中使用了ThreadLocal,以及项目使用的框架SA-Token默认的用户信息存储机制中,会通过过滤器解析Token,将用户信息存储到线程本地存储中(好处之一是可以解决参数透传问题)。
此外,数据库连接等信息也是非常适合存入ThreadLocal中的。在Spring中,最常见的一个问题就是@Transaction是如何实现的,这个注解只会让Spring“加”一部分代码到方法上,加的这部分方法则是获取到ThreadLocal的数据库连接对象并开始、关闭、提交事务。
ThreadLocal使用场景1:日志分析
package com.kieoo.myservice.aop;
import org.apache.log4j.Logger;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.AfterThrowing;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.springframework.stereotype.Component;
import java.util.Arrays;
@Component //声明组件
@Aspect // 声明切面
public class LogAop {
//自定义日志
private Logger logger = Logger.getLogger(LogAop.class);
//用来记录请求进入的时间,防止多线程时出错,这里用了ThreadLocal
private ThreadLocal<Long> startTime = new ThreadLocal<>();
@Before("execution(* com.kieoo.myservice..*.*(..)) || execution(* com.kieoo.myservice..*.*(..))")
public void before(JoinPoint point) {
startTime.set(System.currentTimeMillis());
String beforeLog = "starting invoke class:::" + point.getTarget().getClass() + "===" +
"currentThread= " + Thread.currentThread().getId() + "===" +
"args: " + Arrays.asList(point.getArgs()) + "===" +
"method: " + point.getSignature();
logger.info(beforeLog);
}
@After("execution(* com.kieoo.myservice..*.*(..)) || execution(* com.kieoo.myservice..*.*(..))")
public void after(JoinPoint point) {
String afterLog = "ending invoke class::: " + point.getTarget().getClass() + "===" +
"currentThread= " + Thread.currentThread().getId() + "===" +
"args: " + Arrays.asList(point.getArgs()) + "===" +
"method: " + point.getSignature();
//打印请求耗时
long spendTime = System.currentTimeMillis() - startTime.get();
logger.info("Request spend times: " + spendTime + "ms");
logger.info(afterLog);
}
@AfterThrowing(value = "execution(* com.kieoo.myservice..*.*(..)) || execution(* com.kieoo.myservice..*.*(..))", throwing = "e")
public void afterThrowing(JoinPoint point, Exception e) {
String happen = "exception has been happened! class::: " + point.getTarget().getClass() + "===" +
"currentThread= " + Thread.currentThread().getId() + "===" +
"args: " + Arrays.asList(point.getArgs()) + "===" +
"method: " + point.getSignature() + "===" +
"exceptionInfo: " + e;
logger.info(happen);
}
# CountDownLatch和Semaphore的区别?
- CountDownLatch翻译成中文是“计数器下降门闩”,它的使用场景是一个线程需要等待其他几个线程执行完毕再执行的使用场景
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class CountDownLatchBasicDemo {
public static void main(String[] args) throws InterruptedException {
// 创建CountDownLatch,计数为3(需要等待3个任务完成)
CountDownLatch latch = new CountDownLatch(3);
ExecutorService executor = Executors.newFixedThreadPool(3);
System.out.println("主线程启动,等待3个工作线程完成...");
// 启动3个工作线程
for (int i = 1; i <= 3; i++) {
final int taskId = i;
executor.submit(() -> {
try {
// 模拟任务执行时间
Thread.sleep(1000 + taskId * 500L);
System.out.println("工作线程" + taskId + " 完成任务");
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
// 任务完成,计数器减1
latch.countDown();
System.out.println("计数器减少,当前计数: " + latch.getCount());
}
});
}
// 主线程等待所有工作线程完成
latch.await();
System.out.println("所有工作线程已完成,主线程继续执行");
executor.shutdown();
}
}
- Semaphore则表示信号量,它的使用场景是只要信号量不为零,当前线程就可以操作某对象,如数据库连接池
import java.util.concurrent.Semaphore;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class DatabaseConnectionPoolDemo {
// 模拟数据库连接池
static class ConnectionPool {
private final Semaphore semaphore;
private final int poolSize;
private final AtomicInteger connectionsInUse = new AtomicInteger(0);
public ConnectionPool(int poolSize) {
this.poolSize = poolSize;
this.semaphore = new Semaphore(poolSize, true); // 公平模式
}
public Connection getConnection() throws InterruptedException {
System.out.println(Thread.currentThread().getName() + " 尝试获取数据库连接...");
// 尝试在2秒内获取连接
if (semaphore.tryAcquire(2, TimeUnit.SECONDS)) {
int inUse = connectionsInUse.incrementAndGet();
System.out.println(Thread.currentThread().getName() + " 成功获取连接。" +
" 已使用连接: " + inUse + "/" + poolSize);
return new Connection(this);
} else {
throw new RuntimeException(Thread.currentThread().getName() + " 获取连接超时");
}
}
private void releaseConnection() {
semaphore.release();
int inUse = connectionsInUse.decrementAndGet();
System.out.println(Thread.currentThread().getName() + " 释放连接。" +
" 已使用连接: " + inUse + "/" + poolSize);
}
// 模拟数据库连接
class Connection implements AutoCloseable {
private final ConnectionPool pool;
public Connection(ConnectionPool pool) {
this.pool = pool;
}
public void executeQuery(String sql) throws InterruptedException {
System.out.println(Thread.currentThread().getName() + " 执行SQL: " + sql);
Thread.sleep(1000); // 模拟查询时间
System.out.println(Thread.currentThread().getName() + " 完成SQL: " + sql);
}
@Override
public void close() {
pool.releaseConnection();
}
}
}
public static void main(String[] args) {
// 创建只有3个连接的连接池
ConnectionPool pool = new ConnectionPool(3);
// 创建8个线程模拟并发请求
for (int i = 1; i <= 8; i++) {
final int threadId = i;
new Thread(() -> {
try (ConnectionPool.Connection conn = pool.getConnection()) {
conn.executeQuery("SELECT * FROM users WHERE id = " + threadId);
} catch (Exception e) {
System.err.println(Thread.currentThread().getName() + " 错误: " + e.getMessage());
}
}, "线程-" + threadId).start();
}
}
}
# 如何理解java并发中的可见性,原子性,有序性?
# 什么是原子性?
原子性是指一个或一系列操作要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
# 如何保证原子性?
我们在Java多线程环境中需要使用同步策略(如synchronized关键字或ReentrantLock锁)来保证原子性。保证了原子性也就保证了可见性以及有序性了。
下面的代码是原子性的吗?
i++;
答:不是原子操作。i++分为三个阶段,分别是:1.内存到寄存器 2.寄存器自增 3.回写内存。这3个阶段都可以触发CPU的中断程序,也就是说操作系统和CPU的底层都不保证这个操作的原子性。
如何确保多行代码的原子性?
连i++;这么简单的一行代码,操作系统和cpu都不确保原子性,那么,我们要怎么保证我们的业务代码具有原子性呢。jdk给的方案是synchronized同步修饰原语,该原语对应操作系统的monitor(管程)。
# 什么是有序性?
有序性是指程序执行的顺序按照代码的先后顺序执行。在并发环境中,为了提高效率,编译器和处理器可能会对代码进行重排序,但是这种重排序不会影响单线程程序的执行,却可能影响到多线程并发执行的正确性。
# 如何保证有序性?
在Java中,我们可以使用volatile关键字来修饰属性,volatile会禁止指令重排,可以保证部分有序性,或者使用synchronized和Lock来保证线程之间的执行顺序。
指令重排序说明
Java中的字节码最终会转变成一个一个的指令执行,jdk为了性能考虑,会有一些规则对指令重新排序,这当然无可厚非,同样的,在当前线程中,指令是否重排不会影响程序的运行结果,但是在多线程环境下,jdk可没办法保证多个线程的指令重排序不会影响到多线程的运行结果,因此jdk提供了两个方案,一个是volatile属性,它会禁止指令重排序,另外一个是synzhronized,它同时确保了有序性,原子性,可见性(对象被当前线程同步锁定期间其他线程无法读写)。
# 什么是可见性?
可见性是指当一个线程修改了共享变量的值,其他线程能够立即看到修改的值。在并发环境中,由于线程的内存缓存(cache)和优化,可能会导致一个线程修改了数据,但是其他线程看到的还是旧的值。
# 如何保证可见性?
可以使用Java的volatile关键字保证可见性。同时volatile会禁止指令重排,能保证一定的有序性,但是volatile不保证原子性。
Java内存模型及可见性说明
Java内存模型分为工作内存和主内存,Jvm会为每个线程分配工作内存,工作内存里存储了对象的属性,对这些属性的读写都需要先从主内存读取到工作内存,在工作内存中修改后再同步到主内存。同样的jdk为了性能考虑,提供了volatile关键字,被这个关键字修饰的属性的写操作其他线程理解可见。同样的这个关键字也禁止指令重排(推测可能没办法做到不确保指令重排的情况下保证可见性)。
原子性,可见性,有序性的说明
可见性,有序性,原子性是Java并发的三个问题,Java保证可见性的实现方式的底层内存屏障,Java保证有序性的实现方式也是底层的内存屏障,同时Java还将这两个问题合并到一个volatile关键字上,即Java同时保障了可见性及有序性。
针对原子性,Java的synchronized关键字使用了可见性,有序性的内存屏障,同时使用了锁保证了原子性。
synchronized总结:怎么保证可见性、有序性、原子性? (opens new window)
# AQS相关
# 什么是AQS,简单说一下
AQS(Abstract Queued Synchronizer 抽象队列同步器),是Java并发包中构建锁和同步器的核心框架,像ReentrantLock、CountDownLatch等常用同步工具都是基于它实现的。
# AQS的核心思想
AQS使用一个经volatile修饰的int类型的state变量来表示同步状态,同时保证同步状态在多线程环境下的可见性,通过CAS操作state,保证针对state的复合操作具有原子性。此外,针对未获取同步器的线程,使用一个FIFO队列来管理获取同步状态失败的线程。避免线程的自旋等待以及阻塞。
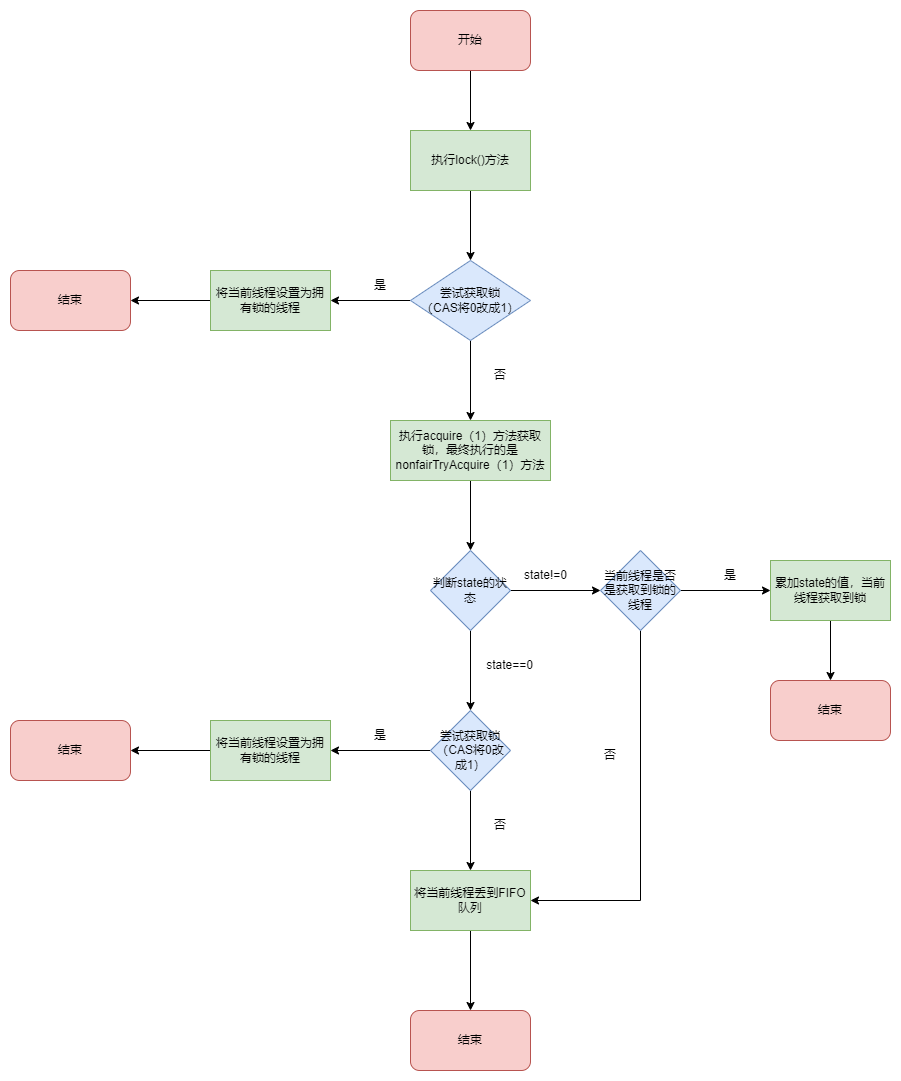
# ReentrantLock的非公平锁如何实现?
// 非公平锁
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* 1. 尝试把state从0改成1(获取锁),能获取到直接使用资源
* 2. 获取不到锁的话执行acquire()方法,这个方法又会执行tryAcquire()方法,最终执行父类的nonfairTryAcquire()方法
* 3. nonfairTryAcquire方法判断锁是否释放,如果释放,同样使用CAS加锁,如果没释放,判断当前线程是否是加锁的线程,是的话锁的次数+1
* 4. 步骤3也获取不到锁,将当前线程放到队列中排队
*/
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
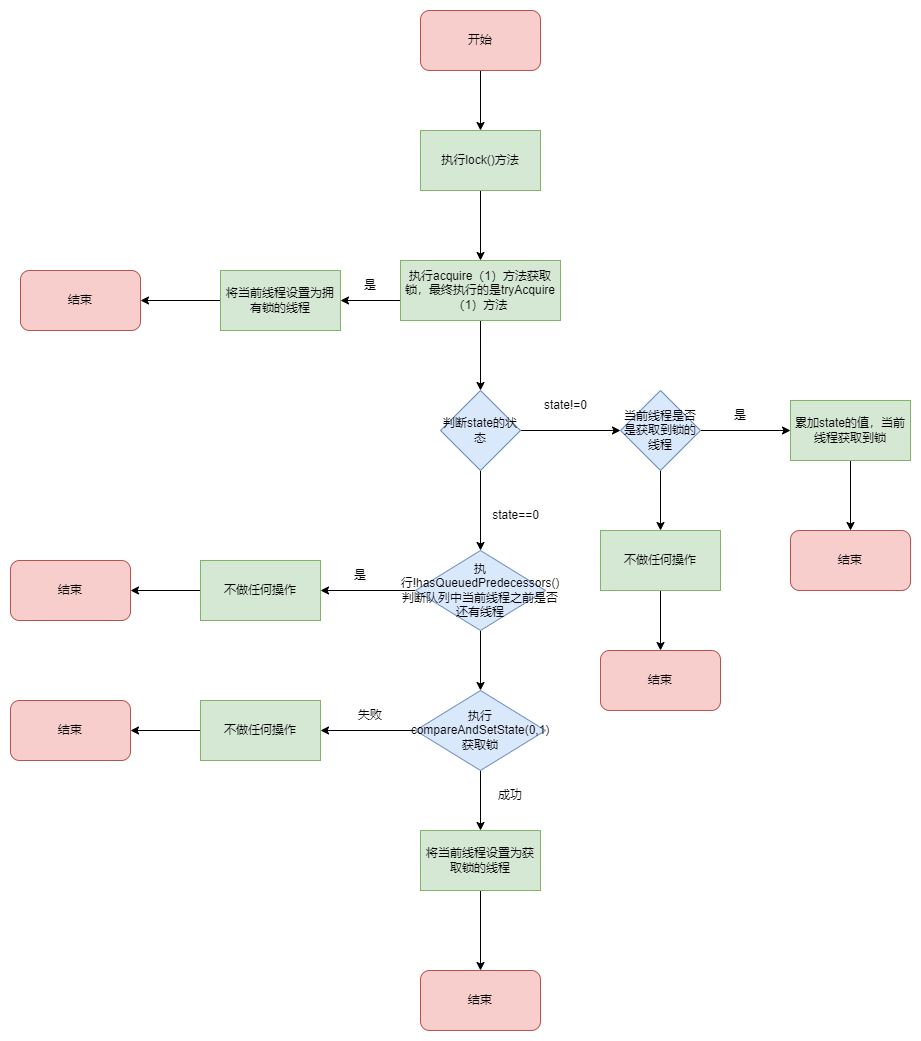
# ReentrantLock的公平锁如何实现?
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
# JDK8流处理
# 遍历集合,将其中某个字段拼接为字符串
/**
* productList是一个List集合,内部存储的是ProductVO对象,这里遍历集合中每个对象的englishValue,然后使用逗号拼接为一个字符串
* 拼接结果中最后一个元素后面没有逗号,其他元素后有逗号分割。
*/
productList.stream().map(ProductVO::getEnglishValue).collect(Collectors.joining(","));
# 综合
# Cookie和Session的区别?
Cookie和Session在定义、存储位置、安全性、应用场景方面均存在显著差异。Cookie存储在浏览器,Session存储在服务器,应用通过在Cookie里传SessionId对请求进行认证。
定义不同
Cookie属于HTTP协议,它是一种存储在用户本地终端(如电脑、手机等)上的小型文本文件,用于辨别用户身份和进行Session跟踪。它允许服务器在客户端上存储少量数据,并在后续的请求中检索这些数据。
Session(会话)是服务器为了区分和跟踪不同用户而创建的一个服务器端状态。由于HTTP协议本身是无状态的,Session机制就是为了解决这个问题而诞生的。Session用于存储和管理用户会话相关的数据。每个用户都会被分配一个唯一的Session ID,该ID通过Cookie或URL重写的方式发送给客户端浏览器,并在后续的存储位置不同
Cookie存储在客户端用户浏览器的本地磁盘中,Session数据存放在服务器的内存中,但Session ID通常通过Cookie或URL重写的方式传递给客户端。安全性差异
Cookie存储在客户端,因此存在被分析或篡改的风险,安全性较低。Session存储在服务器端,对客户端不可见,因此安全性较高。应用场景不同
Cookie常用于记录用户偏好、登录状态等。Session常用于用户身份认证、购物车功能等。
# Session和Token的区别?
Session和Token的存在都是为了解决HTTP本身的无状态问题。两者在存储位置,状态管理,数据结构,生命周期等方面都有区别。
| 特性 | Session | Token (以JWT为例) |
|---|---|---|
| 存储位置 | 服务器端(内存、Redis等) | 客户端(浏览器的LocalStorage、Cookie等) |
| 状态管理 | 有状态的 | 无状态的 |
| 数据结构 | 只是一个ID,实际数据在服务器 | 自包含的(包含用户信息、过期时间等) |
| 扩展性 | 需要Session共享机制 | 天然支持分布式 |
| 跨域支持 | 需要额外配置 | 天然支持 |
| 生命周期 | 服务器端控制 | Token自身控制(通过过期时间) |
# 死锁的四个条件是什么?如何避免死锁?
- 互斥条件(Mutual Exclusion):资源每次只能被一个进程使用。即资源是独占的,其他进程必须等待该资源被释放。
- 占有并等待(Hold and Wait):一个进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不可剥夺(No Preemption):进程已获得的资源,在未使用完之前,不能被其他进程强行剥夺,只能由该进程主动释放。
- 循环等待(Circular Wait):若干进程之间形成一种头尾相接的循环等待资源关系。 其中1,2,3三个条件都是多线程访问资源的必要条件,不可能规避,因此只能针对循环等待做一些处理,如线程在获取锁的时候设置超时时间,当前线程迟迟无法获取锁,则线程也要释放自身占有的锁。
# 如何设计一个合理的微服务架构方案?
# 核心持久化库使用CP设计
针对系统中的核心数据库,如Mysql,ZooKeeper,Redis,使用CP方案设计分布式集群,确保整个系统的关键业务逻辑支持CP强一致性。
# 不使用分布式事务,而使用MQ+失败补偿
针对系统中的具体业务,不使用分布式事务(如果是转账之类的核心业务,也可以考虑使用2PC等分布式事务),针对其余的业务场景,使用MQ解耦合+失败补偿。(也就是结合使用CP+BASE理论使用)。
# 怎么拆分微服务?
拆分微服务的时候,为了保证微服务的稳定,会有以下的准则:
1.微服务之间尽量不要有业务交叉
2.微服务之间只能通过接口进行服务调用,不能绕过接口直接访问对方的数据
3.高内聚,低耦合
# 微服务设计原则
- 单一职责
- 服务自治
- 轻量级通信原则
- 粒度进化原则
# 什么是CAP理论?
# 什么是BASE理论?
# 2PC,3PC和CAP的关系?
CAP指的是在分布式存储系统系统设计中我们只能使用CP,AP,CA(理论上存在,实际不存在,P在分布式系统中一定存在),只能二选一,而2PC,3PC,以及ZooKeeper所使用的就是CP(保证强一致性)的方案。
# 2PC和ZK的区别?
2PC和ZK都是CP系统,2PC 是用于实现分布式事务原子性的原子提交协议。Paxos 是用于在不可靠分布式系统中达成共识的共识算法。
# Quartz实现原理
在Quartz中,有Scheduler,Trigger,Job的概念,Job是一个接口,我们要实现该接口,在该接口的方法里实现业务逻辑。同时我们要配置Trigger触发器(CronTrigger),用Scheduler这个调度器将Trigger和Job绑定在一起,同时执行Scheduler的start()方法开始调度。当start方法执行时,会创建唯一的一个QuartzSchedulerThread 线程(该线程会一直执行),该线程会查询所有的Trigger,从所有Trigger中找到下一个触发点,在触发点调用具体的Job并执行。当找不到最近的触发点的时候,这个线程会休眠。
在微服务架构中,我们往往会启动多个服务,显然多个服务的代码是同一份,其中的定时任务执行时间和执行逻辑也是一样的,如果多个服务同时执行定时任务,那就麻烦了,好在Quartz早就通过数据库实现了分布式锁。多个相同的定时任务同时触发,也只有一个会被执行。
参考资料
在 Quartz 的集群模式中,SchedulerThread线程多久会执行一次检查? (opens new window)
quartz(三)调度器Scheduler和任务监听 (opens new window)
Quartz 源码分析 (opens new window)
Quartz 是什么?一文带你入坑 (opens new window)
JAVA面试题分享三百七十九:Quartz讲解 (opens new window)
分布式任务调度框架之开山鼻祖:Quartz (opens new window)
quartz (从原理到应用)详解篇 (opens new window)
# 什么是同源跨域问题?如何处理跨域请求?
WEB开发本质上是一种特殊的Client/Server架构,我们的服务器当然对应的是Server端,用户浏览器则对应客户端,浏览器自身有一些安全相关的策略,如同源策略,举例来说,如果浏览器请求的网址是www.kieoo.com,在加载到静态资源之后,发现js中又通过fetch/xhr请求了note.kieoo.com这个二级域名,那么没有任何问题,因为二级域名和一级域名对浏览器来说是同源(也就是这两个域名归属是同一家企业/个人),如果发现静态资源js中请求了www.baidu.com。那么浏览器在收到请求的返回结果后会认为该请求存在安全问题并拒绝执行。
# 如何解决跨域问题?
跨域实际上是一个三方行为,也就是A网站,B网站,用户浏览器三方的一个合作行为,跨域访问是一个客观存在的应用场景,用户的诉求必须要得到满足。A公司和B公司存在合作,你在请求A公司的网站的时候,相关的js脚本会请求B公司的接口,这没有任何问题。浏览器作为用户代理,识别到了这种异常行为,提示风险也没有任何问题。
当浏览器识别到异常请求的时候,浏览器并不会直接拦截,而是会请求异常接口,如果异常接口的返回结果中不包含特定的请求头,那么浏览器就拒绝获取响应体并执行其中的代码。同时会在请求中标注一个报错。与之相对应的,如果在异常请求的响应体里识别到了特定的标志位,浏览器会继续执行其中代码逻辑。也就是浏览器识别到了问题,同时,它也识别到了B公司的接口对A公司开放,这个方案就是CORS解决方案。
# CORS解决方案
服务端知道自己的请求可以被哪些跨域的源访问,因此收到请求后,可以设置响应体,浏览器收到响应体后确认无异常就会配合执行相应的代码逻辑了。
# 实际项目中,我们需要先获取请求的req.headers.origin;是允许放行的源的前提下才设置下面的CORS参数
Access-Control-Allow-Origin: http://example.com # 允许的源,可以是具体域名,或*(表示任何源)
Access-Control-Allow-Methods: GET, POST, PUT # 允许的方法
Access-Control-Allow-Headers: Content-Type, Authorization # 允许的请求头
Access-Control-Allow-Credentials: true # 是否允许发送Cookie
浏览器同源、跨域机制到底在保护谁?
从浏览器的角度,同源机制显然是为了保护浏览器的使用者(用户),但是浏览器保护用户的前提需要当前用户访问站点自身做好安全防护机制,如果用户在访问银行系统,该银行系统存在xss漏洞被攻击,那么用户正常请求的时候会执行xss攻击的脚本,很可能就会请求黑客自己的站点,当然黑客自己的站点肯定是允许跨域的,因此脚本的请求可以正常执行。这里显然和同源机制无关,且同源机制也无法规避这个场景,这时就需要银行站点自身做好防护了。同样的,在正常的业务场景下,如果用户浏览一些存在问题的站点,这些站点的脚本同样可能请求无关系统,如请求百度,那么百度这个系统同样需要做好防护,因为频繁的非业务请求同样应该被视为对网站的一种攻击行为。
# 浏览器发出一个请求到请求执行完成的流程?
- 用户在浏览器中输入要访问的服务器的域名。
- 浏览器读取session级别的缓存,判断该域名的解析后IP是否存在,如不存在,则首先读取hosts文件获取,如还是无法获取,会请求DNS解析服务器,如还是无法获取,直接报错。如最终获取到域名对应的IP,会将IP做session级别的缓存。
- 浏览器发送请求到具体的服务端,服务端收到请求后返回。
- 浏览器接收到返回结果并执行静态资源解析/js脚本执行动作。
# TCP三次握手和四次挥手
# 三次握手
- 在客户端请求服务端的时候,首先会发起一个连接信号SYN。
- 服务端收到连接信号后,同样会发送一个信号SYN_ACK。
- 客户端收到信号后,再给服务端发一个信号ACK。此时三次握手建立完成,双方开始流量数据传输。
# 四次挥手
- 在客户端与服务端通信完成后,客户端首先发起一个断开信号FIN。
- 服务端收到信号后,向客户端发回一个ACK信号,之后服务端开始处理断开准备的工作。
- 服务端处理完断开准备工作后,向客户端发送FIN信号。
- 客户端收到FIN信号后,向服务端发送ACK信号,连接正式断开。
# IO多路复用中select、poll、epoll分别指什么?
select、poll、epoll是操作系统针对网络请求的IO多路复用技术,在应用上层我们能感知到的是一个个的Http请求,而在操作系统层面,所谓的网络请求其实是一个个的隐藏文件的写入及读取动作(文件称为Socket文件),如N个请求同时建立,在操作系统中就对应N个文件的文件描述符及文件的写入以及读取。而select、poll、epoll则对应非阻塞IO的多路复用技术。
- select模型使用数组存储Socket连接的文件描述符,数组的大小是固定的,通过轮询来判断是否发生了IO事件。
- poll模型使用链表存储Socket连接的文件描述符,链表的大小是不固定的,poll模型同样通过轮询来判断是否发生了IO事件。
- epoll模型使用事件监听方案来实现IO多路复用,只有发生了IO事件时,才会触发应用程序的读写请求。其中触发事件的方式又分为两种,分别是边缘触发和水平触发。
# epoll模型的边缘触发和水平触发的区别?
首先必须强调一点,这两个术语来自硬件底层,属于应用层复用底层硬件的专有名词,因此它的语义必须在了解硬件底层基本语义的情况下才能理解。
# 边缘触发
如信号量从0变成1,仅在从0变1的这一个瞬间才会触发,因此称为边缘触发。对应到IO多路复用的epoll模型,也就是只会通知一次。如果没有被消费,也不会继续通知。
# 水平触发
只要信号量是1,就通知,只要信号量是0就不通知。也就是只要通知没有被消费,就一直通知。
# IO多路复用之前的BIO操作系统又是如何实现的呢?
在IO多路复用出现之前,操作系统处理并发I/O的最直接方式就是为每个客户端连接分配一个专用线程,该线程会阻塞在I/O操作上,直到数据就绪。
BIO的核心是同步阻塞,操作系统通过线程调度和等待队列来实现阻塞语义。当数据未就绪时,线程被挂起,不消耗CPU;数据到达时,通过中断机制唤醒等待线程。
这种模型的优点是简单直观,符合人类线性思维。但面对高并发时,线程成为稀缺资源,创建/销毁开销大,内存占用高,上下文切换频繁,最终导致了C10K((Client 10,000 Problem))问题。
正是BIO的这些局限性,推动了操作系统提供更高效的I/O多路复用机制(select→poll→epoll/kqueue→io_uring),使得单线程管理大量连接成为可能,这是现代高并发服务器的技术基础。
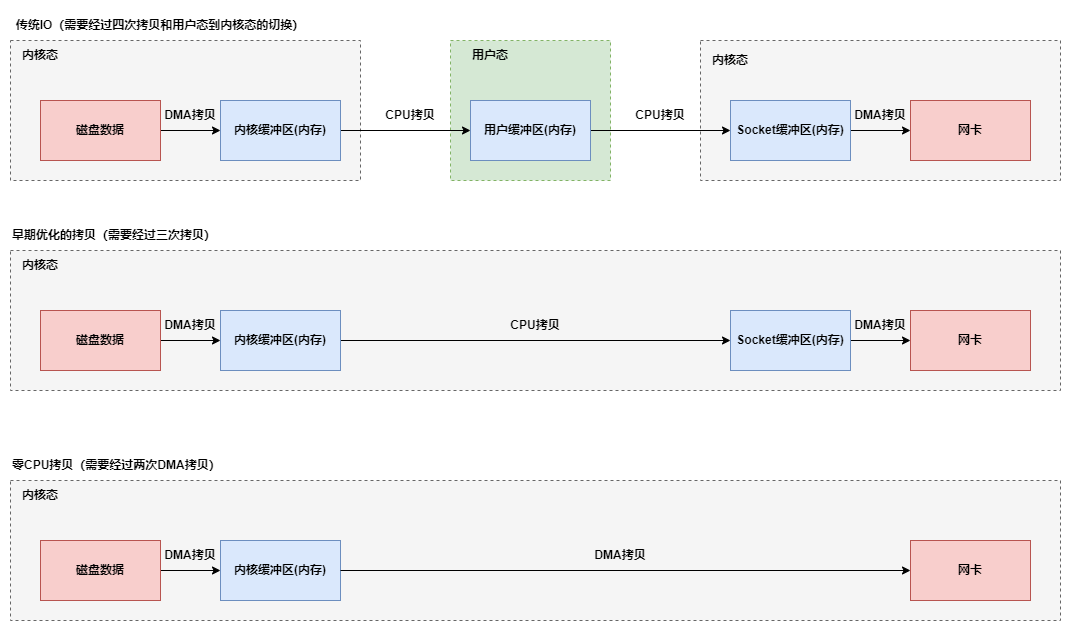
# 什么是零拷贝技术?
零拷贝的全程是零CPU拷贝,传统的I/O中数据的读取到写入(以WEB请求场景从磁盘复制到网卡为例说明),需要经历两次DMA(Direct Memory Access直接内存访问)拷贝,两次CPU拷贝,以及用户态和内核态的切换,而零拷贝技术则省略了两次CPU拷贝,也因此省略了用户态和内核态的切换,IO读写的性能可以获得很大的提升。
# Java中如何使用零拷贝技术?
在Java中,零拷贝(Zero-copy)技术通常指的是避免在内存中复制数据,从而减少CPU占用和内存带宽,提升性能。Java中零拷贝主要通过以下几种方式实现:
- 使用java.nio.channels.FileChannel的transferTo()或transferFrom()方法:这两个方法允许将字节直接从源通道传输到目标通道,而不需要经过应用程序的缓冲区。这在内核空间中进行数据传输,避免了不必要的拷贝。
import java.io.*;
import java.nio.channels.*;
public class ZeroCopyExample {
public static void transferTo(File source, File destination) throws IOException {
try (FileChannel sourceChannel = new FileInputStream(source).getChannel();
FileChannel destinationChannel = new FileOutputStream(destination).getChannel()) {
sourceChannel.transferTo(0, sourceChannel.size(), destinationChannel);
}
}
}
- 使用java.nio.MappedByteBuffer进行内存映射文件:通过FileChannel.map()方法可以将文件的一部分或全部映射到内存中,然后可以直接通过内存地址来访问文件数据,避免了从内核空间到用户空间的拷贝。
import java.io.*;
import java.nio.*;
import java.nio.channels.*;
public class MappedByteBufferExample {
public static void readFile(File file) throws IOException {
try (FileChannel fileChannel = new FileInputStream(file).getChannel()) {
long fileSize = fileChannel.size();
MappedByteBuffer buffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileSize);
// 现在可以直接从buffer中读取数据,而不需要经过用户空间的拷贝
// 例如,读取一个字节
byte b = buffer.get();
// 处理数据...
}
}
}
- 使用java.nio.channels.FileChannel的read(ByteBuffer[] dsts)和write(ByteBuffer[] srcs)方法:这些方法支持分散(scatter)和聚集(gather)操作,可以在一次调用中从通道读取数据到多个缓冲区,或将多个缓冲区的数据写入通道,减少了系统调用的次数,并且可以结合零拷贝技术。
import java.io.*;
import java.net.*;
import java.nio.*;
import java.nio.channels.*;
public class ScatterGatherExample {
public static void scatterRead(File file) throws IOException {
try (FileChannel fileChannel = new FileInputStream(file).getChannel()) {
ByteBuffer header = ByteBuffer.allocate(128);
ByteBuffer body = ByteBuffer.allocate(1024);
ByteBuffer[] buffers = {header, body};
fileChannel.read(buffers); // 分散读取到多个缓冲区
header.flip();
body.flip();
// 处理header和body
}
}
public static void gatherWrite(File file, ByteBuffer header, ByteBuffer body) throws IOException {
try (FileChannel fileChannel = new FileOutputStream(file).getChannel()) {
ByteBuffer[] buffers = {header, body};
fileChannel.write(buffers); // 将多个缓冲区聚集写入到通道
}
}
}
# SOA、微服务、分布式三者的异同?
# SOA
SOA是 Service-Oriented Architecture 的缩写,中文译为 面向服务的架构。
SOA是一种软件设计和架构风格,其核心思想是将应用程序的不同功能单元(称为“服务”) 通过定义良好的接口和契约联系起来,使得这些服务能够以统一和通用的方式进行交互和组合,从而快速构建灵活、可重用的业务应用系统。
简单来说,SOA将传统的、庞大的单体应用,拆分成一系列独立的、可复用的“业务服务”。这些服务就像乐高积木,可以根据业务需求,灵活地拼装成不同的应用流程。
在SOA中,最核心的是企业总线ESB,将各个分散的服务通过SOAP/XML协议整合成单个的服务接口部署到总线上。需要特别强调,SOA架构旨在抽象出公共的服务,同时对服务做轻量级的改造,如从单体应用中抽象出用户服务,存款即可。自身不会对服务之间是否共库共表做任何处理。
在国内互联网发展过程中,SOA几乎是和dubbo捆绑销售的,或者说,dubbo的出现就是为了解决单体应用存在的问题,但是这个时候微服务的理念还不流程,因此基于SOA思想的dubbo的才会出现。
# 微服务
微服务指的是将一个大的单体服务进行拆分,服务与服务之间不能共库,且服务与服务之间通过服务注册及发现机制交互。服务整体对外提供应用的能力。
# 分布式
分布式架构指的是将大的单体服务拆分,然后部署到不同的机器与进程中。SOA和微服务是分布式的两个具体实现方案。
# SOA和微服务的区别?
| 维度 | SOA (面向服务的架构) | 微服务架构 (Microservices) |
|---|---|---|
| 核心目标 | 整合与重用。打破信息孤岛,将企业内已有的、异构的系统(如Java的CRM、.NET的财务系统)连接起来,实现业务流程自动化。 | 敏捷与交付。快速、独立地构建、部署和扩展一个大型单体应用的各个小功能,实现持续交付。 |
| 服务粒度 | 较粗。服务通常代表一个完整的、独立的业务功能域或一个完整的业务系统封装。例如:“客户信息服务”、“整个订单处理系统”作为一个服务。 | 较细。服务代表一个单一的、具体的业务能力。例如:“获取客户信息”、“创建订单”、“计算运费”各自都是独立的服务。 |
| 通信方式 | 强调标准化和智能管道。通常依赖企业服务总线(ESB) 作为中心枢纽,处理消息路由、协议转换、安全、监控等。通信协议常用SOAP/WS-*等重量级协议。 | 强调轻量和去中心化。使用简单的API网关(处理路由、认证等边界问题),服务间通过轻量级协议(如HTTP/REST, gRPC) 直接通信,或通过简单的消息队列(如RabbitMQ, Kafka) 异步通信。 |
| 数据管理 | 倾向于共享数据库。不同服务可能访问同一个中心数据库,以实现强一致性和数据重用。 | 坚持数据库私有。每个微服务拥有自己独立的数据库(可以是不同技术),只能通过自己的API访问。数据一致性通过最终一致性等模式解决。 |
| 核心组件 | ESB (企业服务总线) 是中枢神经系统,非常复杂和强大。 | API 网关 + 服务注册与发现中心 (如Consul, Eureka)。架构更简单、扁平。 |
| 治理与标准 | 自上而下,强治理。强调严格的服务契约(如WSDL)、统一的安全策略、管理流程和开发标准。 | 自下而上,轻治理。强调文化、 DevOps实践和“聪明的终端,笨的管道”。允许技术多样性(不同服务用不同语言/框架)。 |
| 典型应用场景 | 大型企业(如银行、电信)的异构系统整合、遗留系统现代化、B2B集成。 | 互联网公司或需要快速迭代的新应用开发、复杂的单体应用拆解。 |
# 新公司架构选型选哪个方案?
- 技术债务为零,无需背负历史包袱
- 经典SOA的核心使命是“整合”:它擅长用ESB这根“总线”把一堆老旧、异构、紧耦合的“铁疙瘩”系统连接起来。但新公司没有这些“铁疙瘩”,没有需要被整合的遗留系统。从第一天起就引入一个复杂的ESB,无异于给自己打造了一副昂贵的枷锁。
- 微服务的核心使命是“敏捷”:它从一开始就倡导小而专、独立部署、快速迭代。这正是一个新公司追求速度和市场响应能力的天然盟友。
- 组织架构与文化匹配
- 新公司通常是小团队,需要快速试错。微服务倡导的 “一个服务一个团队” (双披萨团队)的自治模式,能最大化团队效率和责任感,避免早期就陷入笨重的跨团队协调和治理流程。
- 经典SOA通常需要较强的、自上而下的中心化治理委员会,这会拖慢初创公司的节奏。
- 技术栈与云原生时代的契合度
- 微服务与 容器化(Docker)、编排(Kubernetes)、 DevOps、 持续交付 等现代云原生技术栈是“天作之合”。这些工具生态就是为了高效地构建、部署和运维大量小型服务而生的。
- 新公司没有历史技术栈的羁绊,可以直接拥抱最现代的、云原生的全套技术,站在更高的起点上。
- 成本与复杂度
- 一个功能完备的商用ESB(如IBM WebSphere, Oracle SOA Suite)采购和维护成本极高,且需要专门的专家团队。这对于资源有限的初创公司是难以承受的。
- 微服务架构的基石(API网关、服务网格、开源框架)大多基于开源和云服务,启动成本和灵活性要好得多。
# 什么是服务熔断?
服务熔断是一种容错机制,用于防止分布式系统中的级联故障。当某个服务出现故障或响应过慢时,熔断器会自动切断对该服务的调用,避免系统资源被耗尽,提高整体系统的弹性。
在真实的微服务场景下,服务与服务之间的调用可以分为两类,分别是应用网关调用下层服务,以及下层服务间的相互调用。针对这两种调用都可以使用熔断机制,一般情况下网关对下游服务的调用的熔断机制比较常见,服务与服务之间的熔断相对较少出现。
- 场景一:服务间调用熔断(以Spring Cloud + Resilience4j为例)
@Service
public class UserService {
private final RestTemplate restTemplate;
private final CircuitBreakerFactory circuitBreakerFactory;
public UserService(RestTemplate restTemplate, CircuitBreakerFactory circuitBreakerFactory) {
this.restTemplate = restTemplate;
this.circuitBreakerFactory = circuitBreakerFactory;
}
public String getUserOrders(Long userId) {
CircuitBreaker circuitBreaker = circuitBreakerFactory.create("userService");
return circuitBreaker.run(() -> {
// 调用订单服务
return restTemplate.getForObject("http://order-service/orders?userId=" + userId, String.class);
}, throwable -> {
// 降级逻辑
return "订单服务暂不可用";
});
}
}
- 场景二:网关调用下层服务(以Spring Cloud Gateway + Resilience4j为例)
# 网关中封装好了熔断策略,只需要添加配置即可实现
spring:
cloud:
gateway:
routes:
- id: order-service
uri: http://order-service
predicates:
- Path=/orders/**
filters:
- name: CircuitBreaker
args:
name: orderServiceBreaker
fallbackUri: forward:/fallback/order
# 什么是服务降级?
服务降级是一种有损的容错策略,当系统资源紧张、故障或高负载时,主动关闭或简化非核心功能,确保核心业务的可用性和响应速度。降级是一种"丢车保帅"的自我保护机制。
# 什么是服务限流?
服务限流是一种通过限制请求速率来保护系统不被过量请求压垮的技术手段。当请求量超过系统处理能力时,限制一部分请求通过,确保系统在极限压力下仍能正常运行。
# 微服务开发中,如何做限流、降级、熔断?
- 服务自身限流:每个服务都要确保自身不会被高流量冲垮,因此每个服务都要有限流策略。
- 服务间熔断:在应用网关调用下层服务以及下层服务之间相互调用的时候,服务调用方需要提前考虑熔断策略。
- 非核心服务降级:非核心服务要随时做好被降级关停的准备。实际业务中可以在测试环境直接关停非核心服务以验证核心业务是否可用。
# 分布式缓存寻址算法有哪些?
其实这个问题的完整描述应该是,在基于集群实现的Redis/其他缓存系统中,如何确定要查找的数据在哪一个分片中?也许应该描述为在分片集群中,如何根据条件查找数据所在分片?主要有如下几种实现方案:
哈希取模
如果集群中的分片数固定,我们可以采用哈希取模的方式来获取数据所在分片,通过对key做哈希,然后将哈希结果与分片取模,即可获取数据所在分片信息。需要特别强调的是哈希取模这种方式集群分片数不能调整,如果调整(如新增分片),则缓存全部失效,服务很可能出现缓存雪崩问题。一致性hash
哈希取模是将key与哈希计算后和分片数进行取模,而一致性哈希则是计算哈希后和2的32次方取模,如果将0和2的32次方首尾相连,这里就组成了一个数字环(也叫哈希环),通过hash计算每个分片,如hash(A),则A分片也落在环的某个数值中,key的哈希环的值通过顺时针(数字递增)后归属到hash(A)/hash(B),hash(C)中即可。这样即使新增分片,也只会有一个分片的缓存会失效(可能存在哈希倾斜,大量缓存只存在某一个分片,针对这个情况可以使用虚拟节点哈希解决)。
# 如何实现接口的幂等性?
幂等性是指同一个操作执行一次或多次,对系统产生的影响是相同的。一个幂等性的接口,需要满足以下的设计要点:
- 幂等键设计:使用全局唯一 ID(如雪花算法)作为请求标识。
- 先查后改:执行业务前先检查是否已处理。
- 失败友好:重复请求应返回与第一次相同的结果(不要报错)。
- 日志记录:关键操作记录日志,便于排查问题。
示例(支付接口幂等)
public class PaymentService {
// 使用 Redis 记录已处理订单
public Result pay(String orderId, BigDecimal amount) {
String key = "pay:" + orderId;
// 尝试设置 Key,若已存在则说明已处理
if (redis.setnx(key, "processing", 300)) {
try {
// 检查订单状态
Order order = orderDao.get(orderId);
if (order.getStatus() == OrderStatus.PAID) {
return Result.success("已支付");
}
// 执行支付逻辑...
orderDao.updateStatus(orderId, OrderStatus.PAID);
return Result.success("支付成功");
} finally {
redis.delete(key); // 或保留用于查询
}
} else {
return Result.fail("请勿重复支付");
}
}
}
# 唯一id实现幂等
每次操作都根据操作和内容生成唯一id,在执行之前判断唯一id是否存在,如果不存在则执行后续操作,并且将唯一id保存到数据库/redis中。
# Token机制实现幂等
服务端提供获取token的接口,客户端在请求具体业务接口前,先请求token接口,获取token后在调用具体业务接口的时候携带token,后端判断token是否存在,存在表示第一次请求,执行具体的业务逻辑,业务逻辑执行完成后将token删除。
# 负载均衡算法都有哪些?
完全随机 完全随机指的是针对任意单一请求,通过随机算法,随机算出某一台机器,然后将请求负载到该机器。缺点很多,一个是请求负载可能不均,第二个是没有办法做会话保持。
轮询 轮询由负载均衡实现端,如Nginx,根据请求依次负载到目标主机清单的主机上。适用于所有主机资源性能接近的情况,缺点同时是没有办法做会话保持。
加权轮询 针对目标主机清单的每台主机设置权重,根据权重做轮询。适用于所有主机资源性能差异较大的情况,缺点同时是没有办法做会话保持。
源地址hash 根据客户端IP计算哈希值,固定分配到某服务器,该方案可以实现会话保持(同一用户请求到同一服务器)。如果服务器动态增减,会话保持会失效。
一致性hash 将服务器和请求映射到哈希环上,相对源地址hash算是优化方案,使用虚拟节点解决数据倾斜问题后,该方案基本可以算是负载均衡的最终解决方案。
其他负载均衡算法 如预测算法、动态权重调整算法、AI驱动负载算法等。
# DataSource是什么?
DataSource是JDK2以上版本提供的一个数据库连接的公共接口,该接口有如下的实现:DriverManagerDataSource(每次返回新链接,不能在生产使用,性能极差),SingleConnectionDataSource(所有请求使用一个链接),拥有链接池缓存的DataSource(如C3P0链接池,Druid连接池)。
如果不使用DataSource,我们就要写如下的丑陋代码了:
// 其实说白了数据库连接也是HTTP请求与响应
Class.forName("driverClassName",true,getClss().getClassLoader());
String jdbcUrl = "...";
Properties connectionInfo = new Properties();
connectionInfo.put("user","");
connectionInfo.put("password","");
...
Connection connection = DriverManager.getConnection(jdbcUrl, connectionInfo);