# Java Web
对Java Web相关知识进行归纳总结
# 1.Java Web综述
# 1.1 B/S架构的优点有哪些?
B/S架构有如下的好处:
1.客户端使用统一的浏览器(Browser)。由于浏览器具有统一性,它不需要特殊的配置和网络连接,有效地屏蔽了不同服务提供商提供给用户使用服务的差异性。更重要的一点是,浏览器的交互特性使得用户使用它非常方便,且用户行为具有可继承性,只要用户学会了上网,不管使用的是哪个应用,一旦学会了,在使用其他应用时就具备了使用经验,因为各个web应用都是基于浏览器操作的。
2.服务端(Server)基于统一的HTTP。和传统的C/S架构使用自定义的应用层协议不同,B/S架构使用的是统一的HTTP。使用统一的HTTP也为服务器提供商简化了开发模式,基于HTTP的服务器有很多,如Tomcat,Nginx,Apache,JBoss,这些服务器都是拿来可用的。不仅如此,连服务器上的应用也是由统一的框架可以使用(如Java中的Servlet规范),这极大的简化了服务提供者的开发。
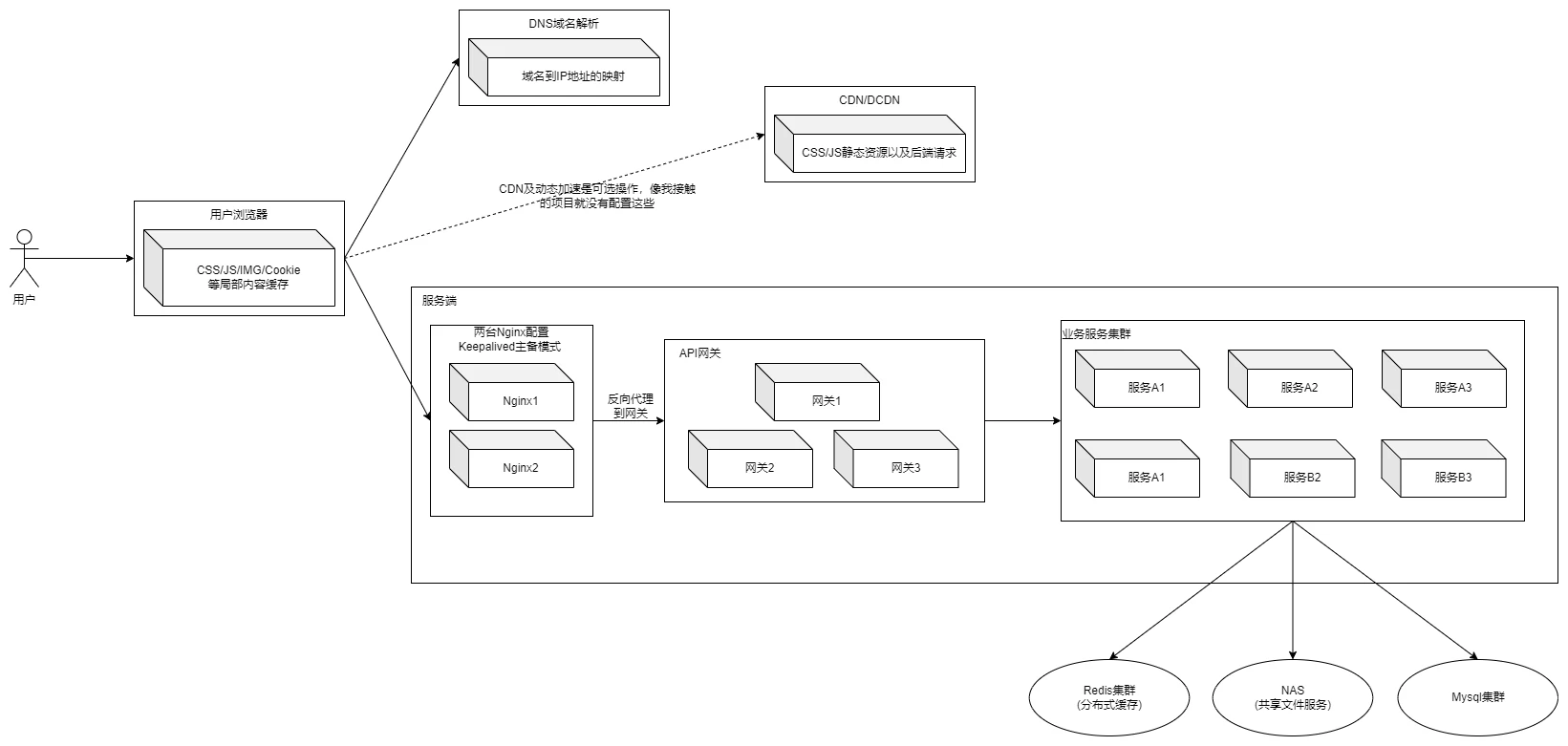
# 1.2 B/S架构的架构图
目前我自己所接触的项目正在使用的一个B/S架构示意图如下所示:
# 1.3 常见的HTTP请求头,响应头,状态码信息都有哪些?
# 请求头
| 请求头 | 说明 |
|---|---|
| Accept-Charset | 用于指定客户端接受的字符集。 |
| Accept-Encoding | 用于指定可接受的内容编码,如Accept-Encoding:gzip.deflate。 |
| Accept-Language | 用于指定一种自然语言,如Accept-Language:zh-cn。 |
| Host | 用于指定被请求资源的Internet主机和端口号,如Host:www.taobao.comHTTP协议Host请求头的作用 (opens new window)。 |
| User-Agent | 客户端把它的操作系统,浏览器和其他属性告诉服务器。 |
| Connection | 是否保持连接,如Connection:Keep-Alive。 |
# 响应头
| 响应头 | 说明 |
|---|---|
| Server | 使用的WEB服务器名称,如Server:Nginx。 |
| Content-Type | 用来指定发送给接收者的实体正文的媒体类型,如Content-Type:text/html;charset=GBK。 |
| Content-Encoding | 与请求头中Accept-Encoding对应,告诉浏览器服务端采用的是什么压缩编码。 |
| Content-Language | 描述了资源所用的自然语言,与Accept-Language对应。 |
| Content-Length | 指定实体正文的长度,用以字节方式存储的十进制数字表示。 |
| Keep-Alive | 保持连接的时间,如Keep-Alive:timeout=5,max=120 表示5毫秒后超时,还能请求120次。 |
# 状态码
| 状态码 | 说明 |
|---|---|
| 502 | 服务器报错,一般是网关报错,它的业务含义是服务提供方服务异常(如500)。 |
| 500 | 服务器发生不可预期的错误。 |
| 404 | 404 Not Found,请求的资源不存在。 |
| 403 | 403 Forbidden,禁止访问。通常应用于身份验证通过但权限不足的情况。客户端已验证身份,但由于权限不足,服务器拒绝了请求。 |
| 401 | 401 Unauthorized(未授权)。通常表示请求需要身份验证,但客户端未提供有效的凭据(如未提供令牌或用户名密码)。 |
| 400 | 400 Bad Request (客户端请求存在语法错误,服务端不能解析)。如请求头不符合HTTP格式规范,用了服务器不支持的请求方法等原因。解析HTTP错误码400 Bad Request及其常见原因与解决方法 (opens new window) |
| 304 | 一般由服务器返回,告知浏览器当前请求的资源是最新的,浏览器直接使用缓存即可。 |
| 302 | 临时重定向。HTTP状态码301和302,你都了解有哪些用途吗 (opens new window) |
| 301 | 永久重定向。 |
| 200 | 客户端请求成功。 |
# 1.4 HTTP缓存机制
在HTTP中,前端浏览器及后端静态资源缓存服务都会对静态资源进行缓存。默认情况下,浏览器会对请求的静态资源进行缓存,此外,如果后端服务部署了缓存服务器,缓存服务器同样会对静态资源进行缓存。
如果需要取消这个缓存,可按HTTP规范,在请求的请求头中添加Pragma:no-cache属性以及Cache-Control:no-cache参数来实现。添加了这两个参数的请求,浏览器及后端的静态资源缓存服务器均不会使用缓存。以下是Cache-Control的可选值:
| 可选值 | 说明 |
|---|---|
| Public | 在响应头设置,所有内容都将被缓存。 |
| Private | 在响应头设置,所有内容只缓存到私有缓存中。 |
| no-cache | 不使用缓存,在请求头或响应头设置均可对该请求生效。 |
| no-store | 在响应头设置,所有内容都不会被缓存。 |
| must-revalidation/proxy-revalidation | 在请求头设置,浏览器对服务端的静态资源缓存服务器的缓存要求,如果缓存的内容失效,请求必须发送到服务器/代理进行重新验证。 |
| max-age=xxx | 在响应头设置,缓存的内容将在XXX秒后失效,这个选项只在HTTP1.1可用。 |
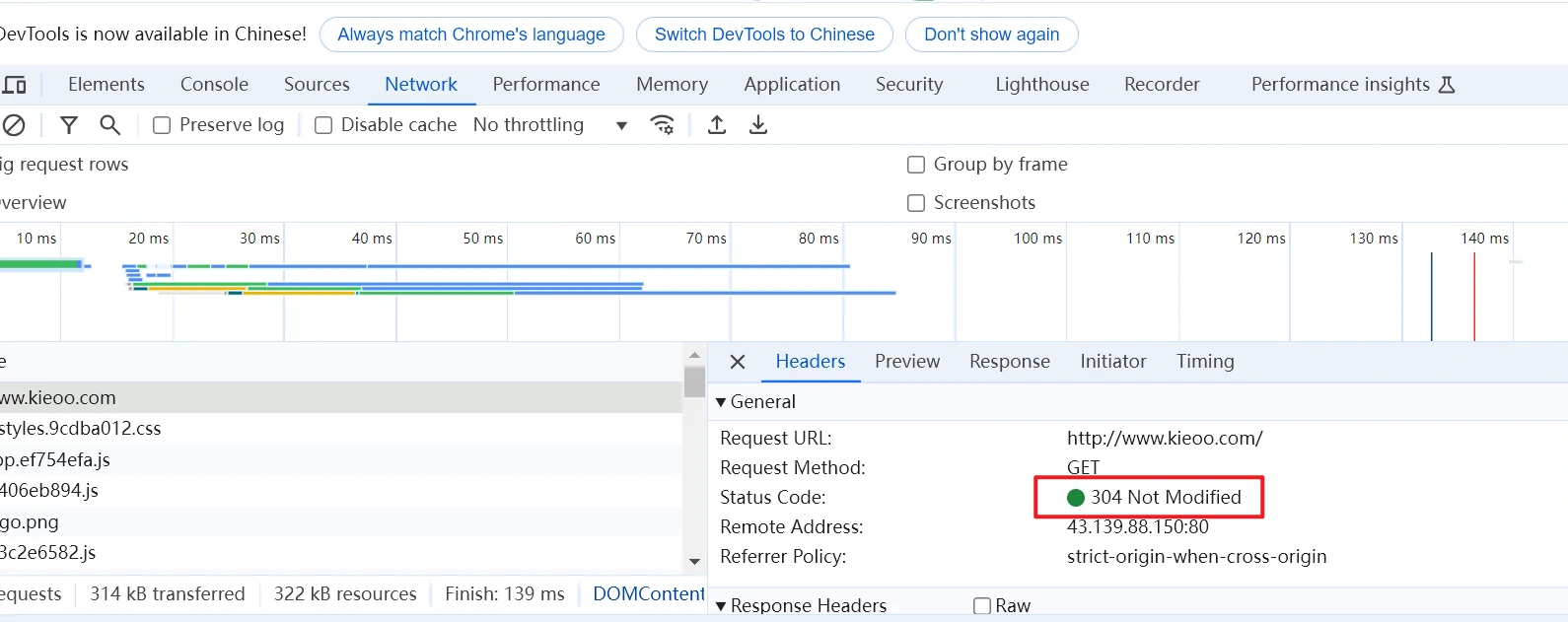
HTTP 状态码304
如果浏览器使用缓存请求后端资源,Nginx会判断浏览器的资源是否是最新的(如根据资源的修改时间做判断),如是最新的资源,Nginx会修改响应头的状态码为304,然后直接返回请求。
如何取消HTTP缓存
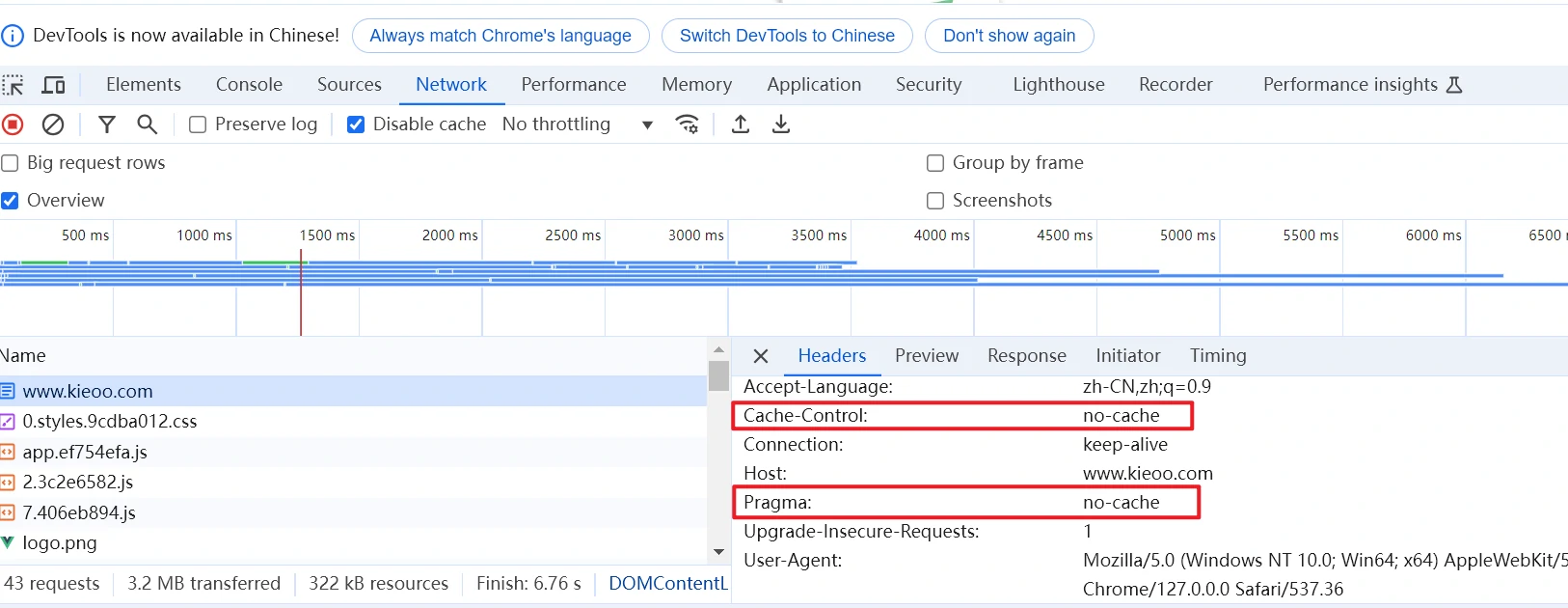
我们可以通过F12快捷键打开调试界面,勾选调试页面Network中的Disable cache按钮的方式来禁用浏览器及后端缓存服务的缓存。
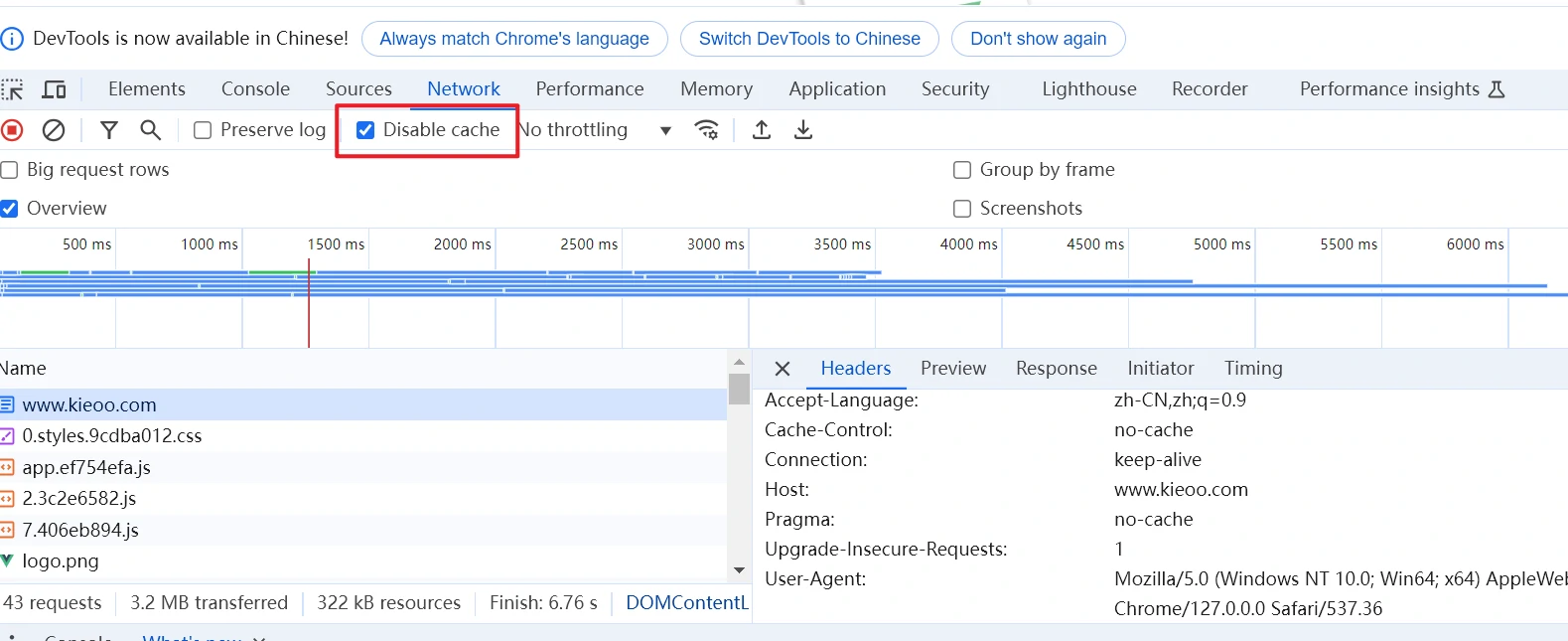
可以看到,该请求返回HTTP状态码为200,而不是304,说明前端浏览器请求了后端服务(即浏览器未使用缓存),后端缓存服务返回200,也说明后端未使用缓存。
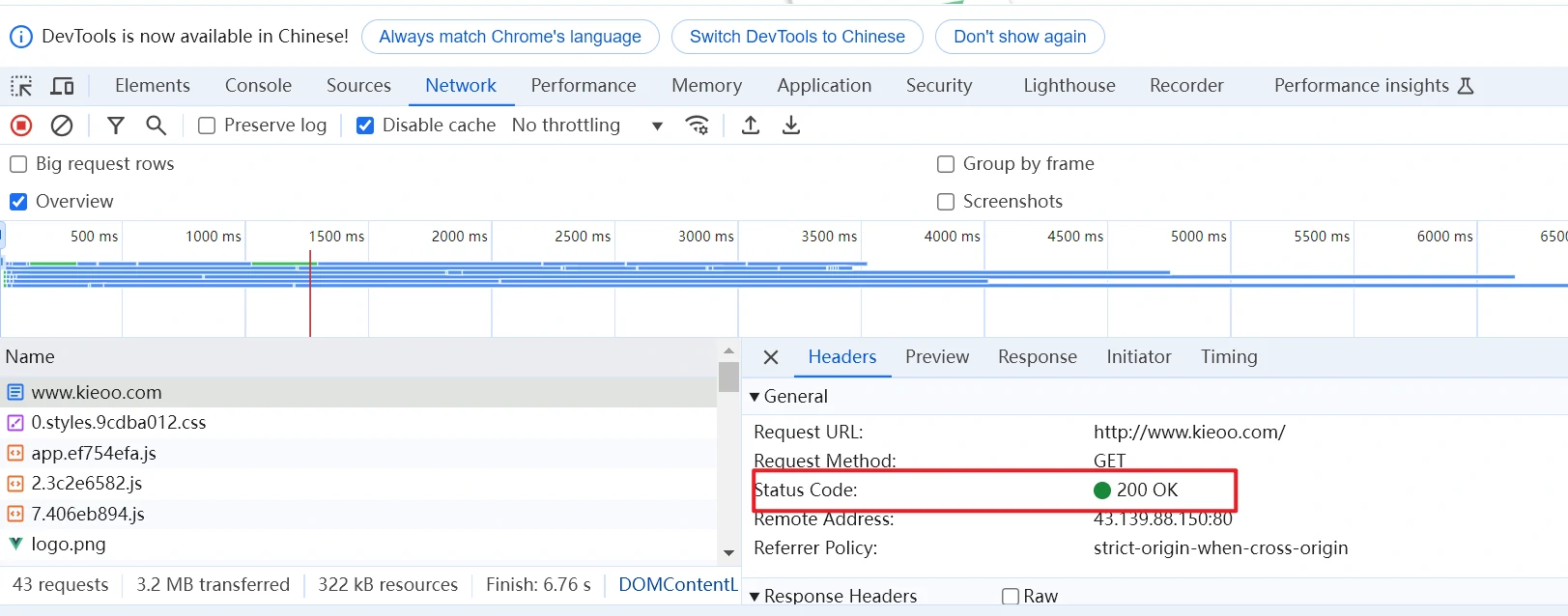
同样的,我们还可以在请求头中看到Pragma:no-cache属性以及Cache-Control:no-cache参数,同样的这里也说明了关键字正常生效。
补充说明
需要特别强调一下,如果我们需要用InetAddress类解析域名,必须是单例模式,不然会有严重的性能问题,如果每次都创建一个InetAddress实例,则每次都要进行完成的域名解析,非常耗时,对这一点需要特别注意。
# 1.5 DNS域名解析过程
DNS域名解析过程,主要有浏览器缓存,解析hosts文件,LDNS(Local DNS Server)服务器解析,Root Server根域名服务器,gTLD主域名服务器解析,Name Server服务器解析过程组成。解析过程如下图:
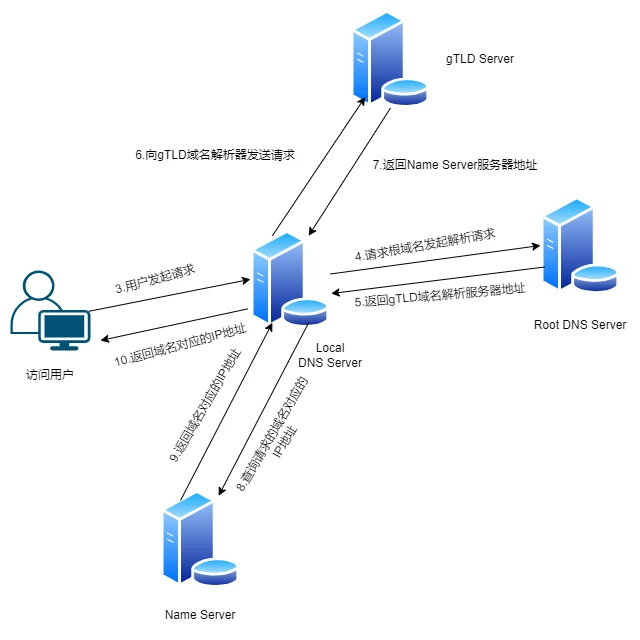
1.浏览器缓存
当一个使用域名的URL在浏览器中请求时,浏览器会首先在缓存中查找域名及IP映射关系,如能找到,即可将域名解析为IP地址,如缓存无数据,执行步骤2.解析hosts文件。2.hosts文件
在Win环境下,hosts文件的地址在C:\Windows\System32\drivers\etc\hosts,在Linux环境下,hosts文件的地址在/etc/hosts,在hosts文件中,我们可以配置域名及ip地址的映射关系(一般配置该文件仅用于测试服务在真实的域名环境的访问效果)。如hosts文件中无法解析域名,执行步骤3.LDNS解析。3.LDNS解析
在Win环境下我们可以通过ipconfig /all指令来查找本机的域名解析服务器,即LDNS的ip地址。

在Linux环境下我们可以通过cat /etc/resolv.conf指令来查找本机的域名解析服务器。

大约80%的域名解析都由LDNS服务器完成,所以LDNS主要承担了域名的解析工作。如LDNS无法命中,就直接到Root Server根域名服务器解析请求。4.根域名服务器解析
根域名服务器返回本地域名服务器一个所查询域的主域名服务器(gTLD Server)地址,gTLD是国际顶级域名服务器,如.com,.cn,.org等,全球只有13台。5.请求gTLD服务器
本地域名服务器请求gTLD服务器,gTLD服务器会查找并返回域名所对应的Name Server域名服务器的地址,这个Name Server通常是域名所在的域名服务器的地址(如我的域名的Name Server是山东烟台帝思普)。6.请求Name Server
本地域名服务器请求Name Server,获取域名解析后的ip,保存在本地域名服务器,然后返回给用户浏览器。域名解析动作完成。
补充资料:如何查询域名解析结果?
在Windows及Linux下,我们均可使用nslookup指令来查询域名的解析结果。
在Linux环境下,我们还可以使用dig www.kieoo.com +trace来跟踪域名解析的完整过程。
补充资料:如何清除当前主机下缓存的域名?
在Win环境下,可以使用ipconfig /flushdns指令来清理dns缓存。
在Linux环境下,可以使用/etc/init.d/nscd restart来清理dns缓存。
补充资料:几种域名解析方式
域名解析记录主要分为A记录,MX记录,CNAME记录,NS记录,TXT记录。
1.A记录:Address地址记录,用于指定域名对应的IP地址,如将www.kieoo.com指定为43.139.88.150。A记录可以将多个域名解析为同一个IP地址,但是不能将一个域名解析到多个IP地址。
2.MX记录,表示Mail Exchange,如果将MX记录设置为43.139.88.150,DNS会自动将邮件xxxx@kieoo.com解析到43.139.88.150上的邮件服务器。
3.CNAME,表示别名解析,即为一个域名设置别名(别名为另一个域名),这样一个域名就会被解析为另一个域名,最终会解析到A记录,即某一个域名的IP地址。
4.NS记录,将域名解析工作交给特定的服务器,而不是直接将域名解析为IP地址。
5.TXT记录,为某个主机名或域名设置说明,意义不大(也可以在其中设置电话号码用于联系)。
补充资料:短链域名解析原理
参考短url域名是怎么设计的 (opens new window),大体思路就是自己买一个比较短的域名,在域名所在的ip的服务器上部署nginx+openresty+redis,对原始地址做一个Hash运算,运算结果作为key,原始地址作为value存在redis中,当用户请求短域名/hash的url的时候,nginx解析请求,读取redis,获取原始地址,填充到响应头中,同时修改响应头的Http状态码为302(临时重定向),依赖浏览器的能力做临时重定向跳转即可。
# 1.6 CDN工作过程
CDN也就是内容分发网络(Content Delivery Network)主要用来分发css,js,图片,静态页面等数据。用户从主站服务器上请求动态内容后,再从CDN上下载静态资源,从而加速网页数据内容的下载速度。CDN的实现最关键的一步是在域名解析中配置CNAME解析操作。
用户请求某个静态资源(如css文件),这个资源的域名是www.kieoo.com,首先浏览器会向Local DNS服务器发起请求,然后会走到域名的Name Server去解析,Name Server上一般该域名都会配置NS记录,最终域名会回到注册服务器(43.139.88.150)上面的DNS解析服务去解析(如我的域名kieoo.com在烟台帝思普配置了NS记录)。这时我的域名解析服务器就会把当前域名CNAME解析到另外一个域名,而这个域名最终指向的是CDN全局中的DNS负载均衡器(GTM),GTM会负载一个最近的节点的ip地址给用户,即cdn.kieoo.com这个域名会被解析为一个对当前用户来说网络环境最好的静态资源服务器的ip地址。
# 1.7 DCDN动态加速
CND加速只针对静态资源(css,js,html)等文件进行加速,DCDN则可以对静态资源以及动态资源(如业务接口)进行加速,此外DCDN还具备算法自动寻路的功能,可以自动找到就近的节点为用户提供服务。
# 2.Java I/O的工作机制
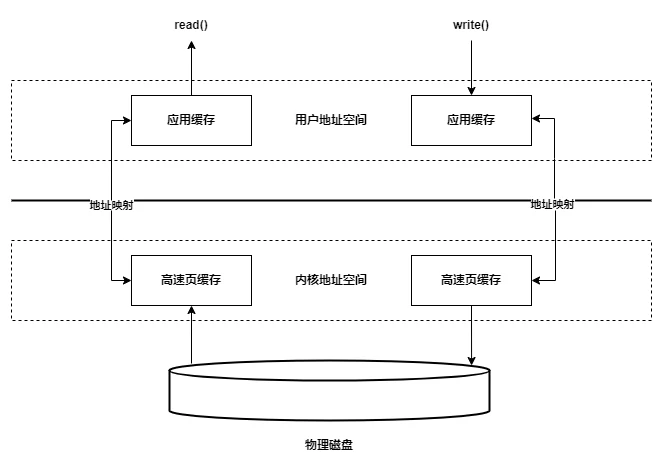
# 2.1 访问I/O(I/O读写)的三种缓存方式?
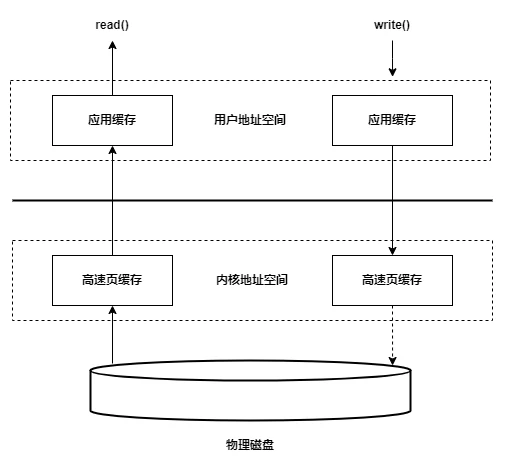
# 缓存I/O
缓存I/O又被称作标准I/O,大多数文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。
- 读操作:
当应用程序调用read()方法时,操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中。 - 写操作:
应用程序调用write()方法将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
# 直接I/O
所谓的直接I/O的方式就是应用程序直接访问磁盘数据,而不经过操作系统内核数据缓冲区,这样做的目的就是可以减少一次从内核缓冲区到用户程序缓存的数据复制。这种访问文件的方式通常是在对数据的缓存管理由应用程序实现的数据库管理系统中。如在数据库管理系统中,系统明确的知道应该缓存哪些数据,应该失效哪些数据。还可以对一些热点数据做预加载,提前将热点数据加载进内存,可以加速数据的访问效率。在这些情况下,如果由操作系统进行缓存,则很难做到,因为操作系统并不知道哪些是热点数据。哪些数据可能只会访问一次就不会再访问,操作系统只是简单的缓存最近一次从磁盘读取的数据。
Java中直接I/O对应NIO模块中的FileChannel.transferFrom(),FileChannel.transferTo()方法,在Linux中对应sendfile系统调用。
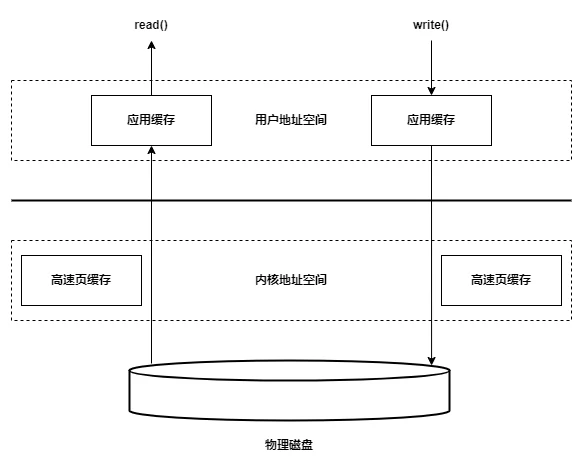
# 内存映射I/O
内存映射的方式是指操作系统将内存的一部分区域与磁盘中的文件关联起来,当要访问内存中的一段数据时,转换为访问文件的某一段数据。这种方式的目的同样是减少数据从内核空间缓存到用户空间缓存的数据复制操作,因为这两个空间的数据是共享的。
Java中内存映射I/O对应NIO模块中的FileChannel.map()方法,在Linux中对应mmap内存映射系统调用。
# 2.2 阻塞I/O及非阻塞I/O的区别?
上面讨论的是I/O读写的缓存机制,这里讨论的是在I/O暂时可不读,不可写时当前线程是否阻塞,根据这个标准,我们可以将I/O分别阻塞I/O以及非阻塞I/O。此外,这里讨论的阻塞I/O以及非阻塞I/O都是指同步I/O,异步I/O很少见,不详细展开。
# 阻塞I/O
同步访问文件的方式比较好理解,就是数据的读取read()和写入write()都是同步操作的,如果文件暂时不可读/不可写,当前线程会被阻塞,直到文件可读/可写后才会继续执行。
# 非阻塞I/O
非阻塞I/O的方式就是当访问数据的线程发出请求之后,线程会接着去处理其他事情,而不是阻塞等待,当请求的数据返回后继续处理下面的操作。这种访问文件的方式可以明显地提高应用程序的效率,但是不会改变访问文件的效率。
# 2.3 阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动的IO模型、异步IO模型
阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动的IO模型均为同步IO模型。
# 阻塞IO模型
- 在阻塞 I/O 模型中,应用程序发起一个I/O 请求后会一直阻塞等待操作完成,直到数据准备好或者超时才返回结果。
- 应用程序在等待 I/O 完成期间会处于阻塞状态,无法执行其他任务。
- 这种模型适用于简单的 I/O 操作,但会造成资源浪费和性能下降。
# 非阻塞IO模型
- 在非阻塞 I/O 模型中,应用程序发起一个I/O请求后会立即返回,无需等待操作完成。
- 应用程序需要不断轮询或者使用事件通知来检查操作是否完成。
- 这种模型通常适用于需要处理多个连接或者连接数较多的场景,但效率不高。
# IO多路复用模型
- 多路复用 I/O 模型使用操作系统提供的 select、poll 或 epoll 等多路复用机制,允许应用程序同时监视多个 I/O 事件。
- 应用程序可以将多个 I/O 请求注册到一个多路复用器上,然后通过轮询或者阻塞等待多路复用器通知事件的发生。
- 这种模型适用于需要同时处理多个连接的场景,提高了系统的并发性能。
select,poll,epoll
IO多路复用也是非阻塞IO模型,主要是select,poll,epoll模型,tomcat用的是epoll的边缘触发,nginx用的是水平触发,所以nginx比tomcat性能强非常多。
epoll边缘触发和水平触发的区别
- 两者区别
- 水平触发:"有数据就提醒",可以慢慢处理
- 边缘触发:"来新数据才提醒",必须一次性处理完
- 如何取舍
- 大多数应用:用水平触发,简单可靠
- 高性能服务器:用边缘触发 + 非阻塞 I/O,追求极致性能
这就是为什么 Nginx(追求极致性能)选择 ET,而 Redis(注重简单可靠)选择 LT 的原因。两者都在各自场景下做出了最优选择。
# 信号驱动的IO模型
- 信号驱动 I/O 模型使用信号机制来实现异步 I/O,应用程序通过向内核注册信号处理函数来处理 I/O 事件。
- 当 I/O 操作完成时,内核会发送一个信号通知应用程序,然后由应用程序在信号处理函数中处理该事件。
- 这种模型相比阻塞 I/O 和非阻塞 I/O 更为灵活,适用于需要处理多个 I/O 事件的场景。
# 异步IO模型
- 异步 I/O 模型通过操作系统提供的异步 I/O 接口来实现,应用程序发起一个 I/O 请求后会立即返回,并且在操作完成后会通过回调或事件通知的方式通知应用程序。
- 应用程序无需等待操作完成,可以继续执行其他任务,当操作完成后会触发回调函数或者发送事件通知。
- 这种模型通常适用于需要高并发、高性能的场景,如网络服务器、大规模并行计算等。
异步IO不在讨论范围
jdk7中IO的优化操作
在jdk7之前,FileInputStream,FileOutputStream,RandomAccessFile这三个类的性能都不太好,归根到底在于涉及到IO的读写的节点,sun公司的设计没有使用操作系统支持的Channel管道模型,因此,涉及到read()方法以及write()方法的IO读写时,性能较差。 在jdk7版本,sun对这几个类中的读写方法进行了Channel重写,因此,jdk7之后,这几个类的读写方法就不存在性能问题了。
参考资料
半小时搞懂 IO 模型 (opens new window)
一文彻底搞懂常见IO模型 (opens new window)
理解一下5种IO模型、阻塞IO和非阻塞IO、同步IO和异步IO (opens new window)
# 2.4 Java BIO的工作方式
# 2.4.1 什么是BIO
BIO全称是Blocking IO,翻译成中文就是阻塞IO,这里的阻塞,IO从名称上只能看出来和IO相关,但其实它描述的是以ServerSocket,Socket,InputStream,OutputStream为核心的Java网络编程模型,使用这个模型进行编程,应用会在客户端与服务端建立连接时阻塞,也会在服务端等待客户端发消息时阻塞。下面以几个简单模型来讲一下BIO的阻塞以及如何基于BIO来建立一个简单的Web Server。
# 2.4.2 version 1.0
- Server端代码
Server端在每一个会导致Server/Client阻塞的代码行下方都打印了日志,日志中带有时间戳参数,通过观察和Client之间的时间戳即可知道相关的代码执行顺序
package bio.version1;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
/**
* 这里通过一个简单的Socket 服务端来展示服务端与客户端的交互以及accept(),read(),write()方法的阻塞
* 部分参数写死,且未对相关的流做关闭处理的原因仅仅是让代码尽可能简单
*
* @author howl-xu
* @version 1.0
* @date 2023-04-24
*/
public class BIOServer1 {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket(9090);
System.out.println("服务端启动..." + System.currentTimeMillis());
Socket socket = serverSocket.accept();
System.out.println("accept方法会在客户端链接完成后执行" + System.currentTimeMillis());
InputStream inputStream = socket.getInputStream();
OutputStream outputStream = socket.getOutputStream();
byte[] clientMessage = new byte[12];
inputStream.read(clientMessage);
System.out.println("read方法会在客户端write方法之后执行" + System.currentTimeMillis());
System.out.println(new String(clientMessage));
outputStream.write("Hello Client".getBytes());
System.out.println("write方法执行后,客户端read方法才会执行" + System.currentTimeMillis());
}
}
- Client端代码
Client端在每一个会导致Server/Client阻塞的代码行下方都打印了日志,日志中带有时间戳参数,通过观察和Client之间的时间戳即可知道相关的代码执行顺序
package bio.version1;
import java.io.*;
import java.net.Socket;
/**
* 这里通过一个简单的Socket 客户端来展示服务端与客户端的交互以及accept(),read(),write()方法的阻塞
* 部分参数写死,且未对相关的流做关闭处理的原因仅仅是让代码尽可能简单
*
* @author howl-xu
* @version 1.0
* @date 2023-04-24
*/
public class BIOClient1 {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("localhost", 9090);
System.out.println("客户端启动..." + System.currentTimeMillis());
OutputStream outputStream = socket.getOutputStream();
InputStream inputStream = socket.getInputStream();
outputStream.write("Hello Server".getBytes());
System.out.println("write方法执行后,服务端read方法才会执行" + System.currentTimeMillis());
byte[] serverMessage = new byte[12];
inputStream.read(serverMessage);
System.out.println("read方法会在服务端write方法之后执行" + System.currentTimeMillis());
System.out.println(new String(serverMessage));
}
}
Server启动
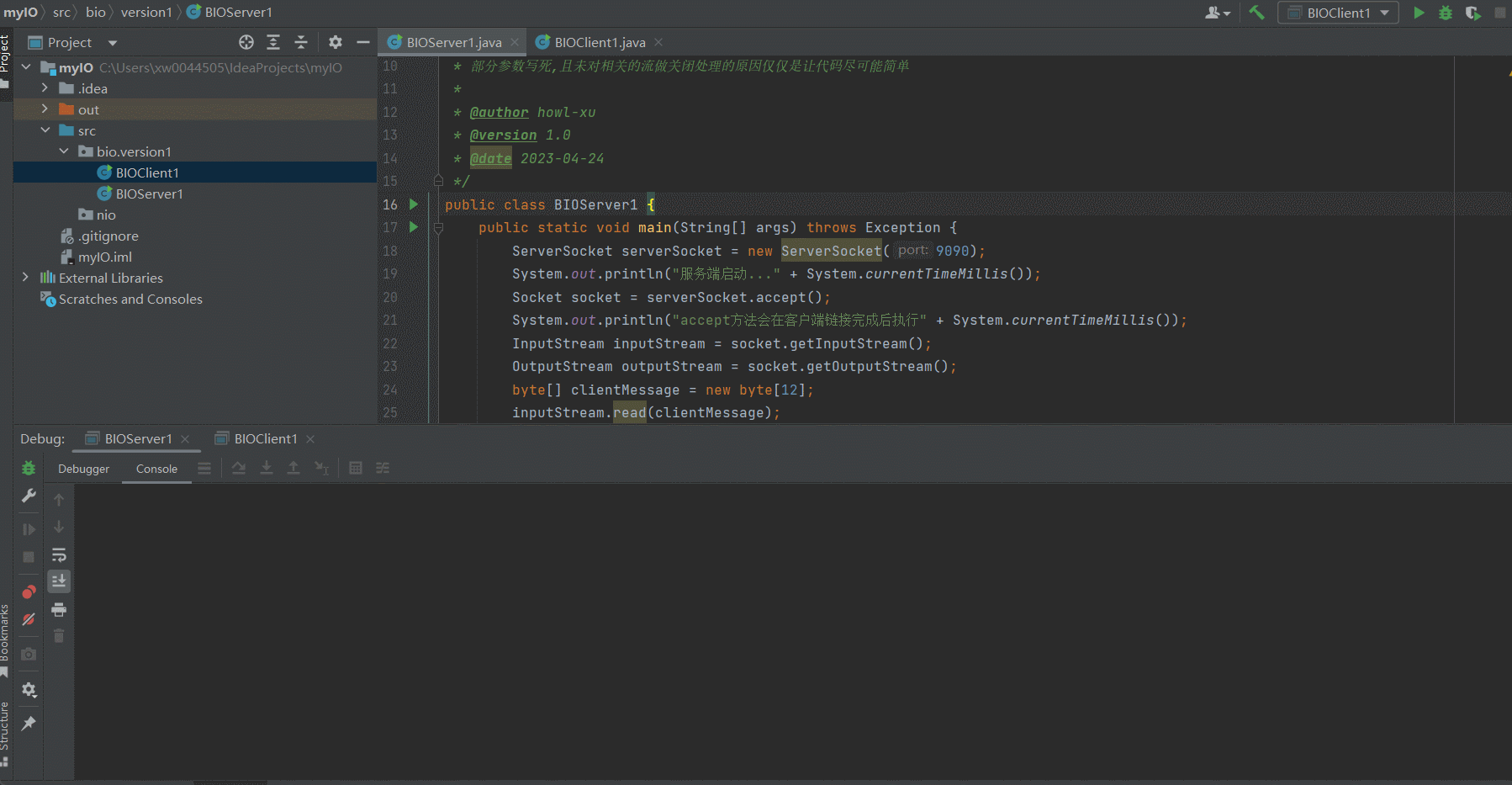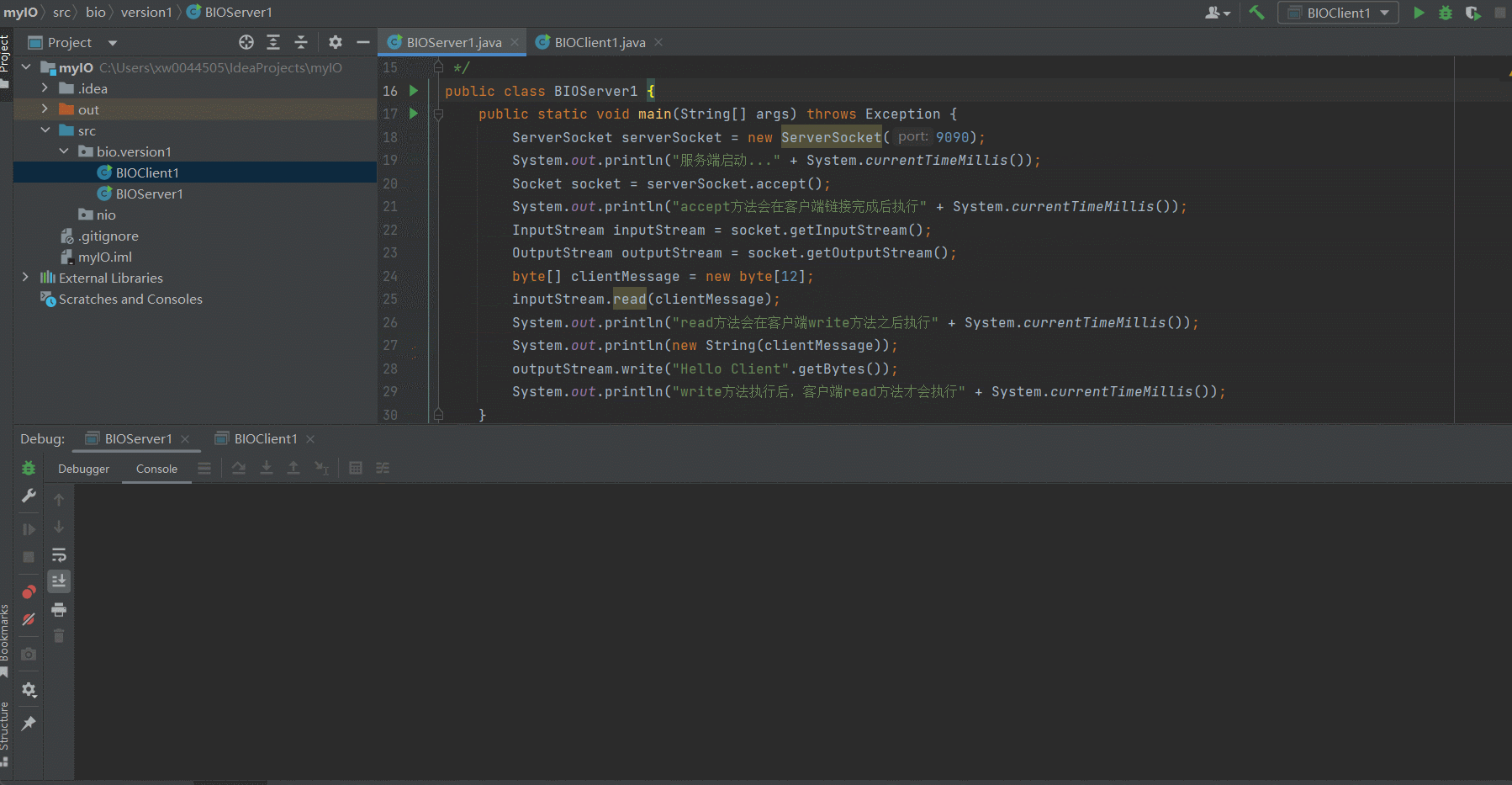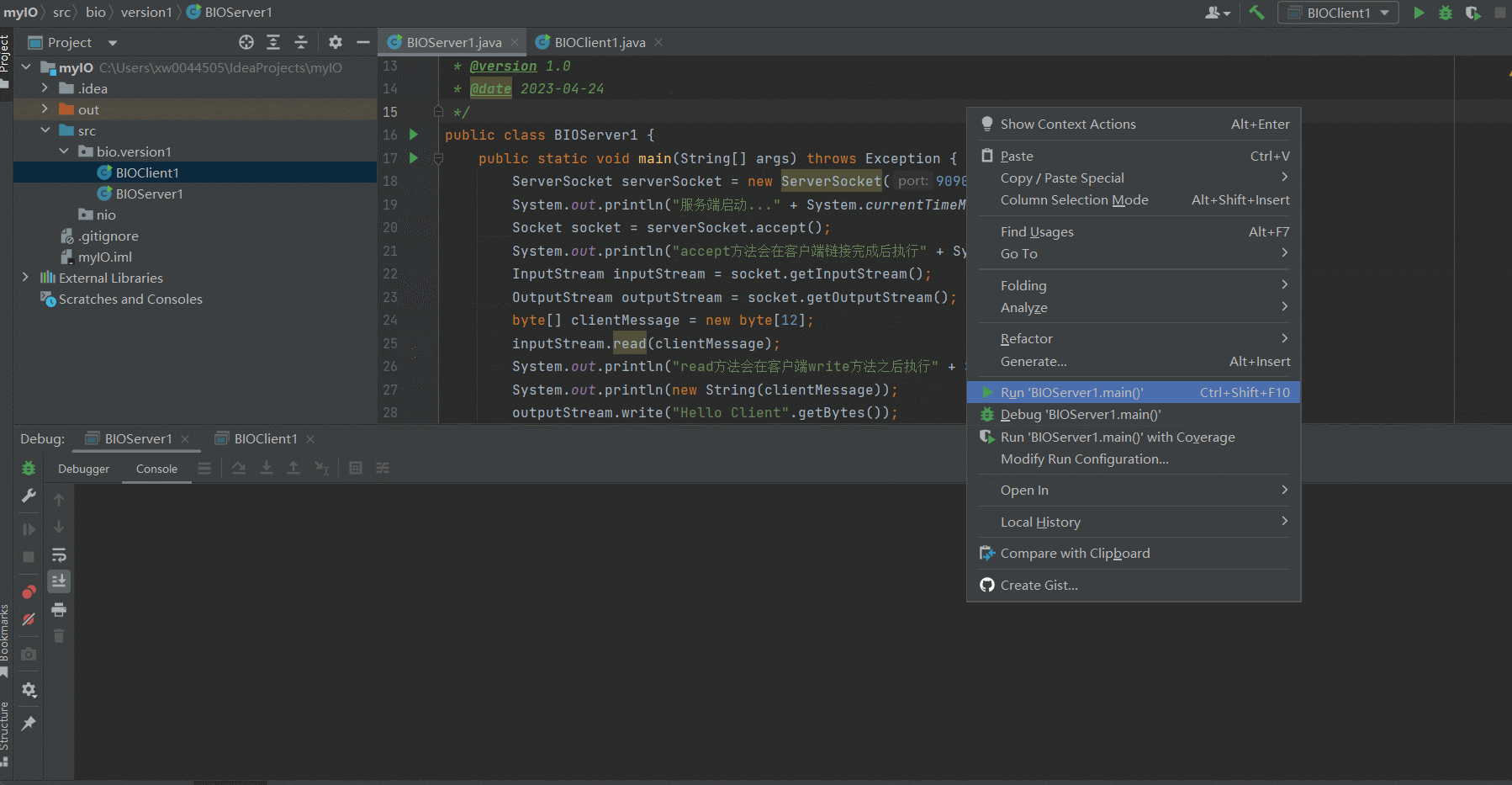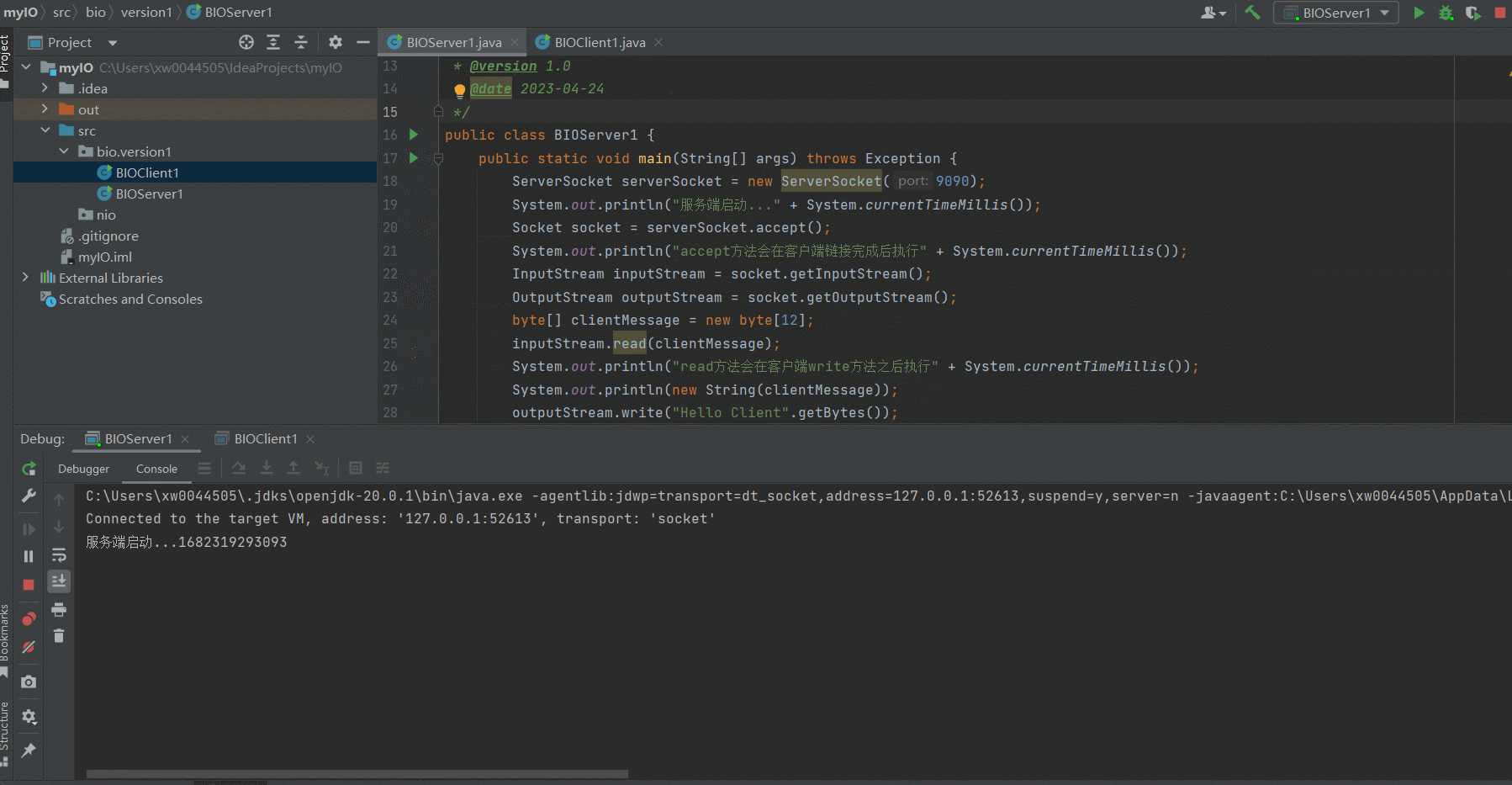
Client启动

比对结果
Connected to the target VM, address: '127.0.0.1:52613', transport: 'socket'
服务端启动...1682319293093
accept方法会在客户端链接完成后执行1682319357663
read方法会在客户端write方法之后执行1682319357672
Hello Server
write方法执行后,客户端read方法才会执行1682319357672
Disconnected from the target VM, address: '127.0.0.1:52613', transport: 'socket'
Connected to the target VM, address: '127.0.0.1:52618', transport: 'socket'
客户端启动...1682319357663
write方法执行后,服务端read方法才会执行1682319357672
read方法会在服务端write方法之后执行1682319357672
Hello Client
Disconnected from the target VM, address: '127.0.0.1:52618', transport: 'socket'
通过比对Server以及Client的日志输出可以看出
1.Server启动之后,会在accept()方法阻塞,直到Client进行链接
2.Server accept()方法执行完成后,会阻塞在 inputStream.read(clientMessage);,直到Client中 outputStream.write("Hello Server".getBytes());这一行代码执行完毕
3.同理,Client中 inputStream.read(serverMessage);这一行也会阻塞,直到Server中 outputStream.write("Hello Client".getBytes());这一行代码执行完毕
- version1.0版本存在的问题
version1.0中,无论是Server还是Client,都只执行了一次就结束了,这显然不合理,Client只执行一次还好,我们的Server可是要给很多Client提供服务的,显然不能执行一次就结束掉,因此,我们对Server进行改造~
# 2.4.3 version 2.0
在version1.0中,最大的问题是Server仅仅执行一次,为了解决这个问题,我们对Server端进行改造,Clinet则暂不修改,代码如下
- Server端代码
在Server2.0中,我们将socket链接的代码放在了while循环中,这样Server就可以一直处理和Client的链接,而不会执行一次就退出了
package bio.version2;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
/**
* 这里通过一个简单的Socket 服务端来展示服务端与客户端的交互以及accept(),read(),write()方法的阻塞
* 部分参数写死,且未对相关的流做关闭处理的原因仅仅是让代码尽可能简单
*
* @author howl-xu
* @version 1.0
* @date 2023-04-24
*/
public class BIOServer2 {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket(9090);
System.out.println("服务端启动..." + System.currentTimeMillis());
while (true) {
Socket socket = serverSocket.accept();
System.out.println("accept方法会在客户端链接完成后执行" + System.currentTimeMillis());
InputStream inputStream = socket.getInputStream();
OutputStream outputStream = socket.getOutputStream();
byte[] clientMessage = new byte[12];
inputStream.read(clientMessage);
System.out.println("read方法会在客户端write方法之后执行" + System.currentTimeMillis());
System.out.println(new String(clientMessage));
outputStream.write("Hello Client".getBytes());
System.out.println("write方法执行后,客户端read方法才会执行" + System.currentTimeMillis());
}
}
}
- Client端代码
在Client2.0中,我们不做任何修改,保持代码和Client1一致即可。
package bio.version2;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
/**
* 这里通过一个简单的Socket 客户端来展示服务端与客户端的交互以及accept(),read(),write()方法的阻塞
* 部分参数写死,且未对相关的流做关闭处理的原因仅仅是让代码尽可能简单
*
* @author howl-xu
* @version 1.0
* @date 2023-04-24
*/
public class BIOClient2 {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("localhost", 9090);
System.out.println("客户端启动..." + System.currentTimeMillis());
OutputStream outputStream = socket.getOutputStream();
InputStream inputStream = socket.getInputStream();
outputStream.write("Hello Server".getBytes());
System.out.println("write方法执行后,服务端read方法才会执行" + System.currentTimeMillis());
byte[] serverMessage = new byte[12];
inputStream.read(serverMessage);
System.out.println("read方法会在服务端write方法之后执行" + System.currentTimeMillis());
System.out.println(new String(serverMessage));
}
}
顺序执行多个Client
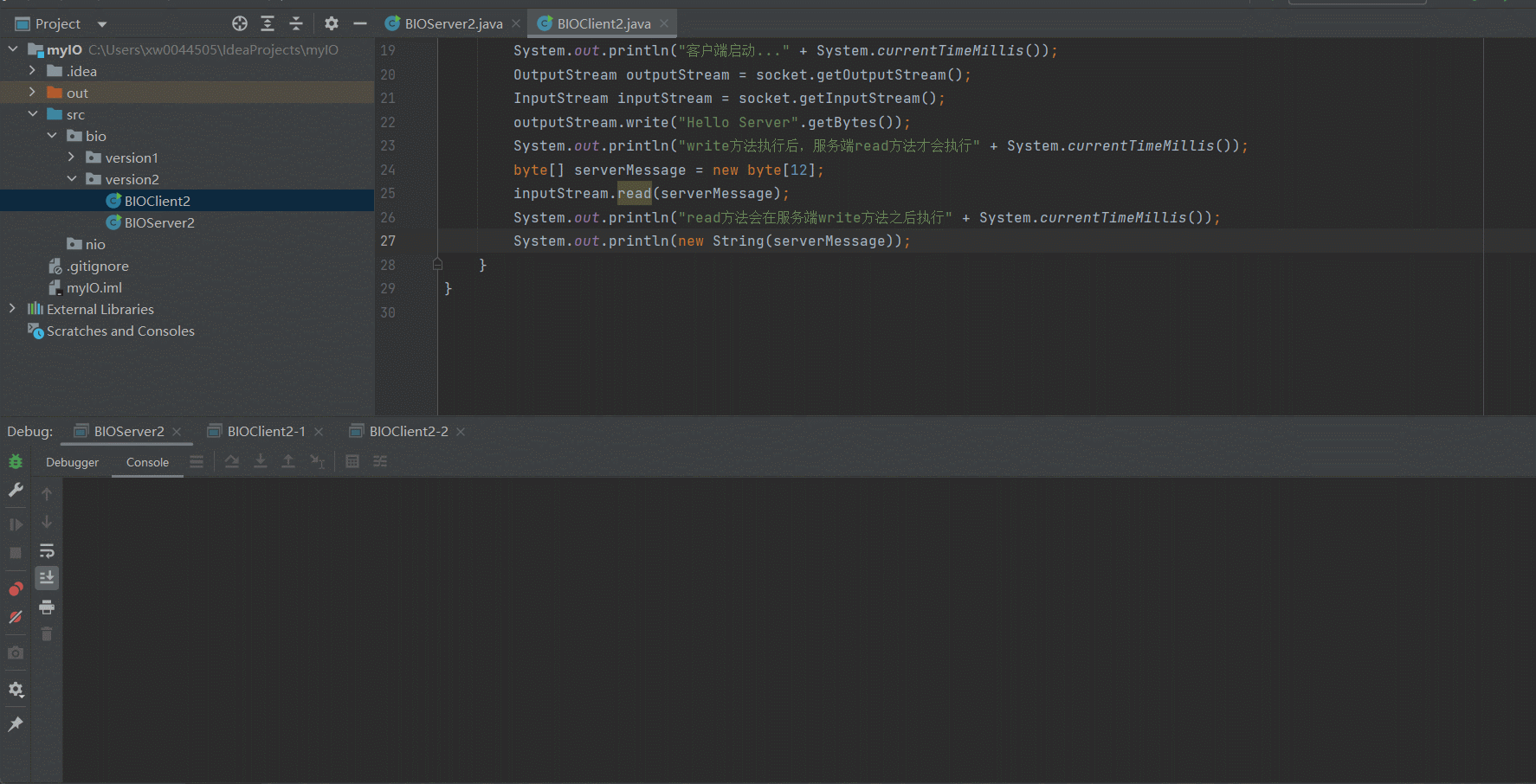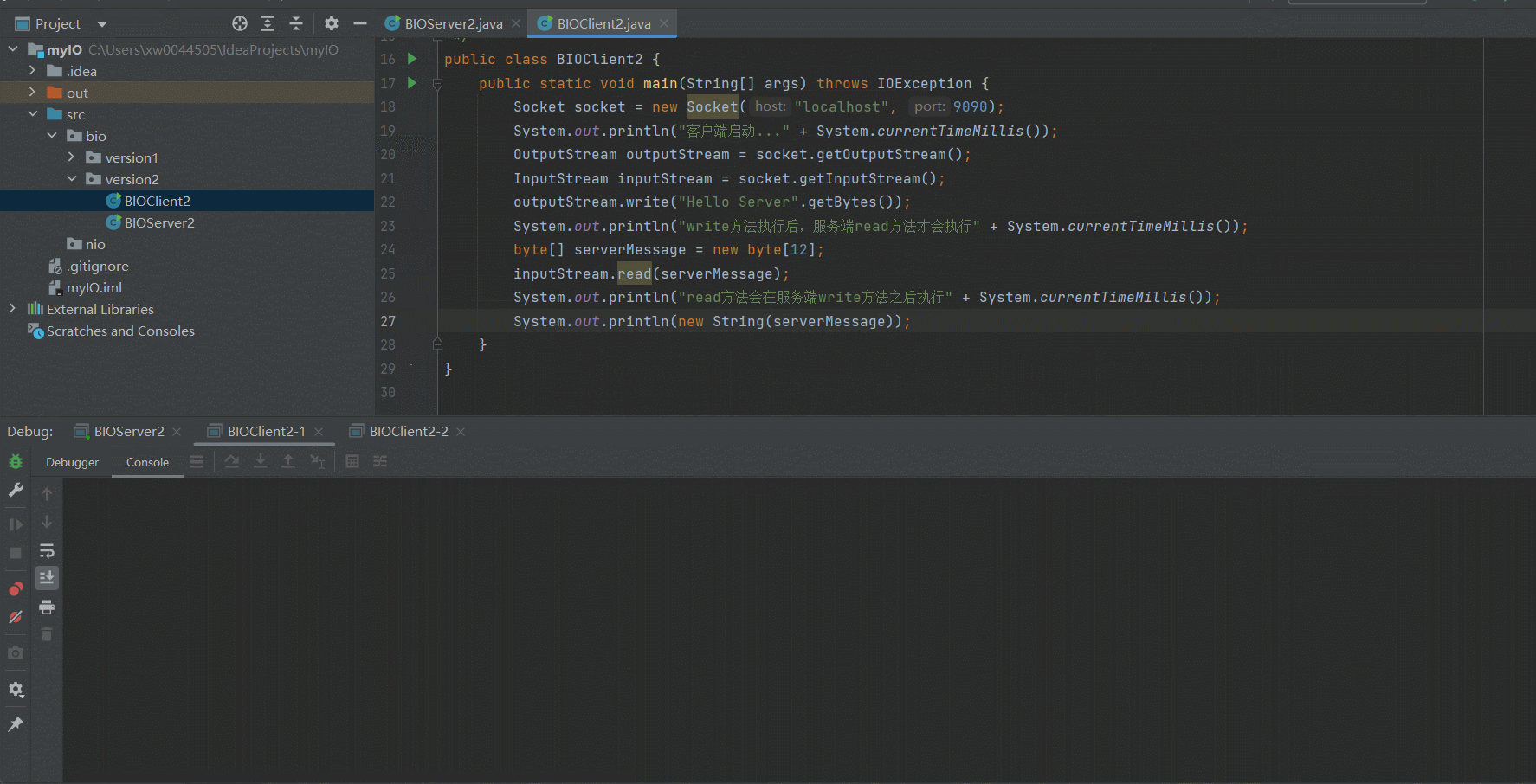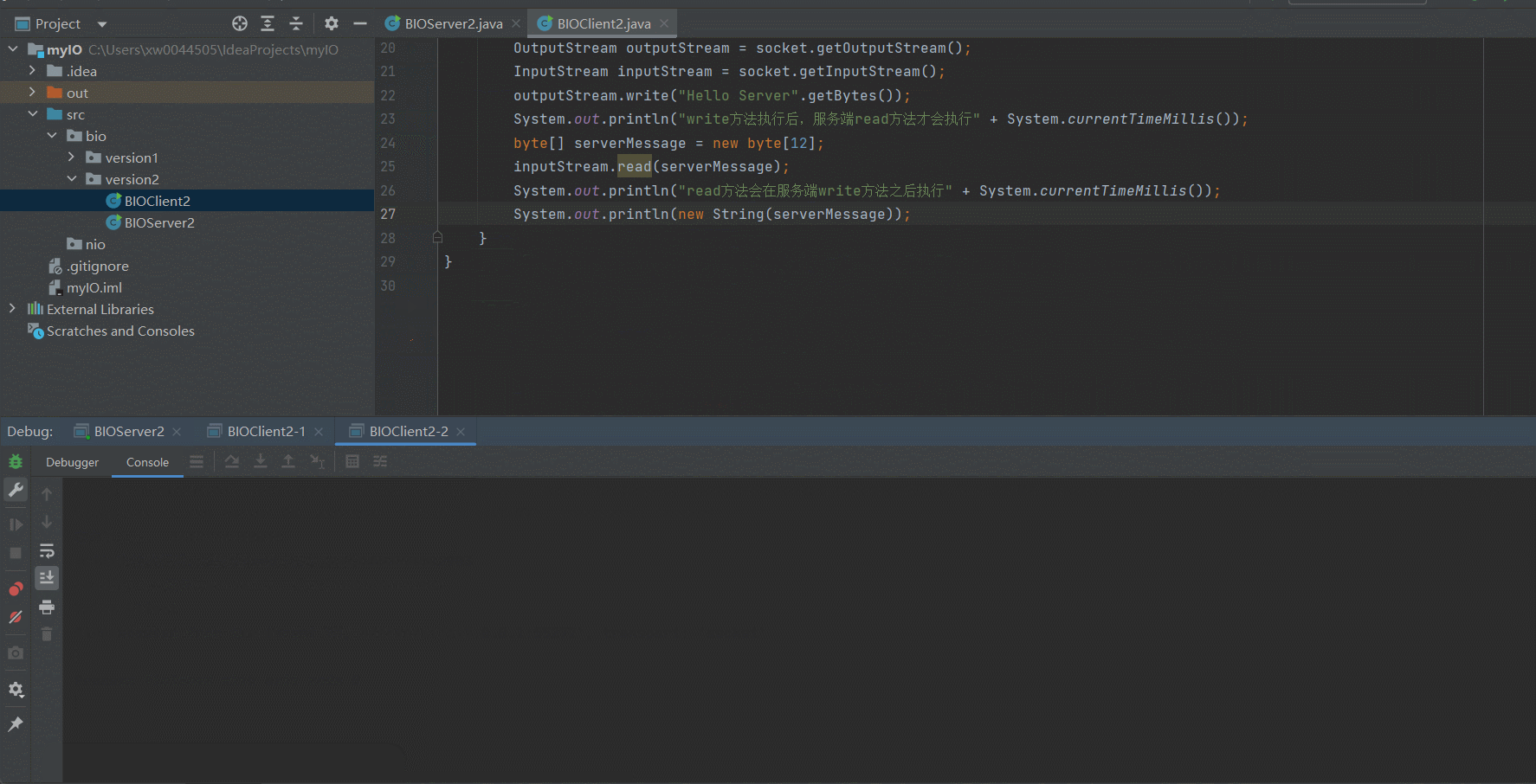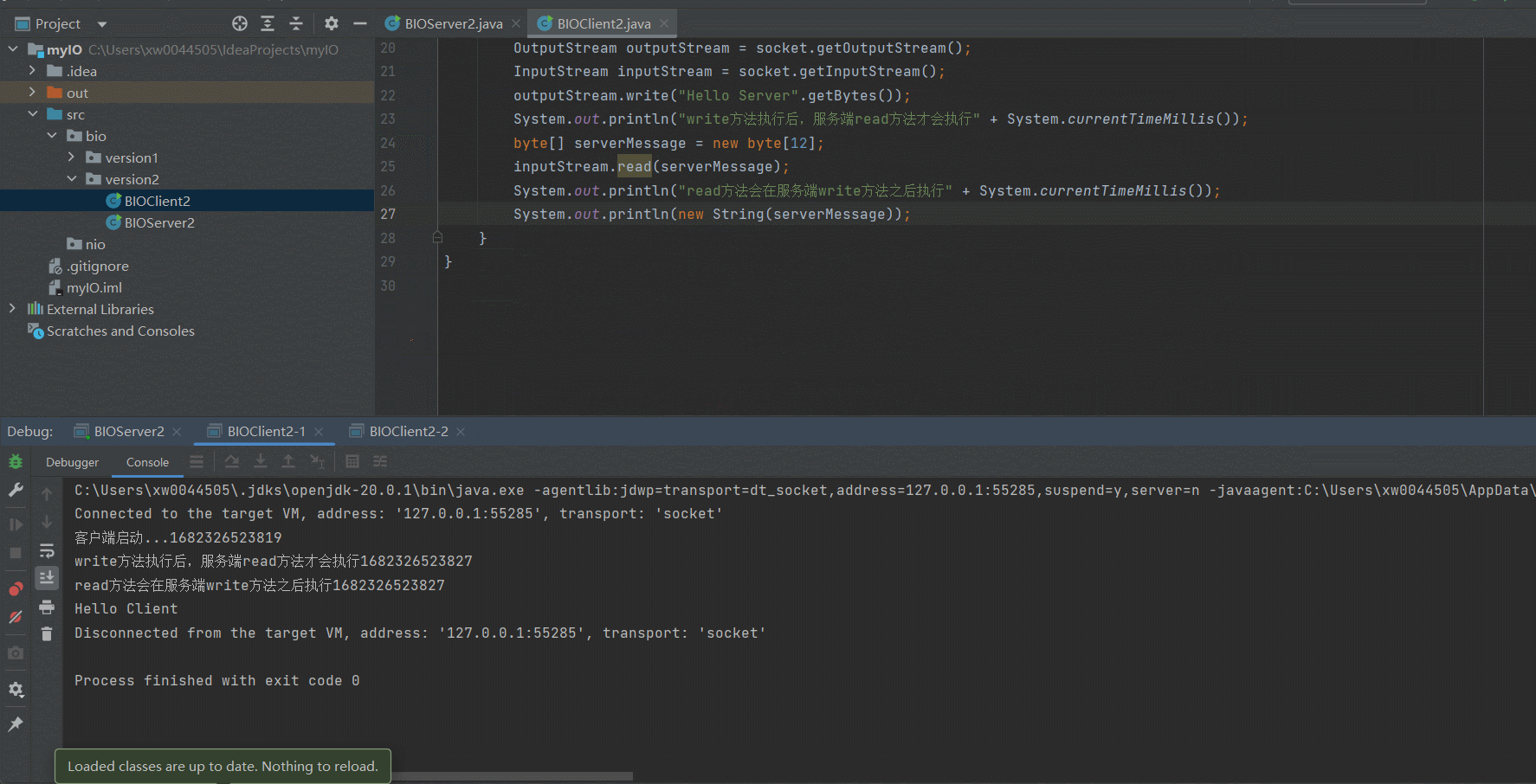
可以看到,经过改良好的服务端已经可以支持多个客户端访问了,只要我们的客户端自觉地按顺序执行就可以了。但是很显然,我们并没有办法保证所有的客户端按顺序依次访问Server。下面我们来演示一下因为某一个Client的IO阻塞导致其他客户端到服务端的链接不可用的场景~某个Client因为IO阻塞导致服务端被占用
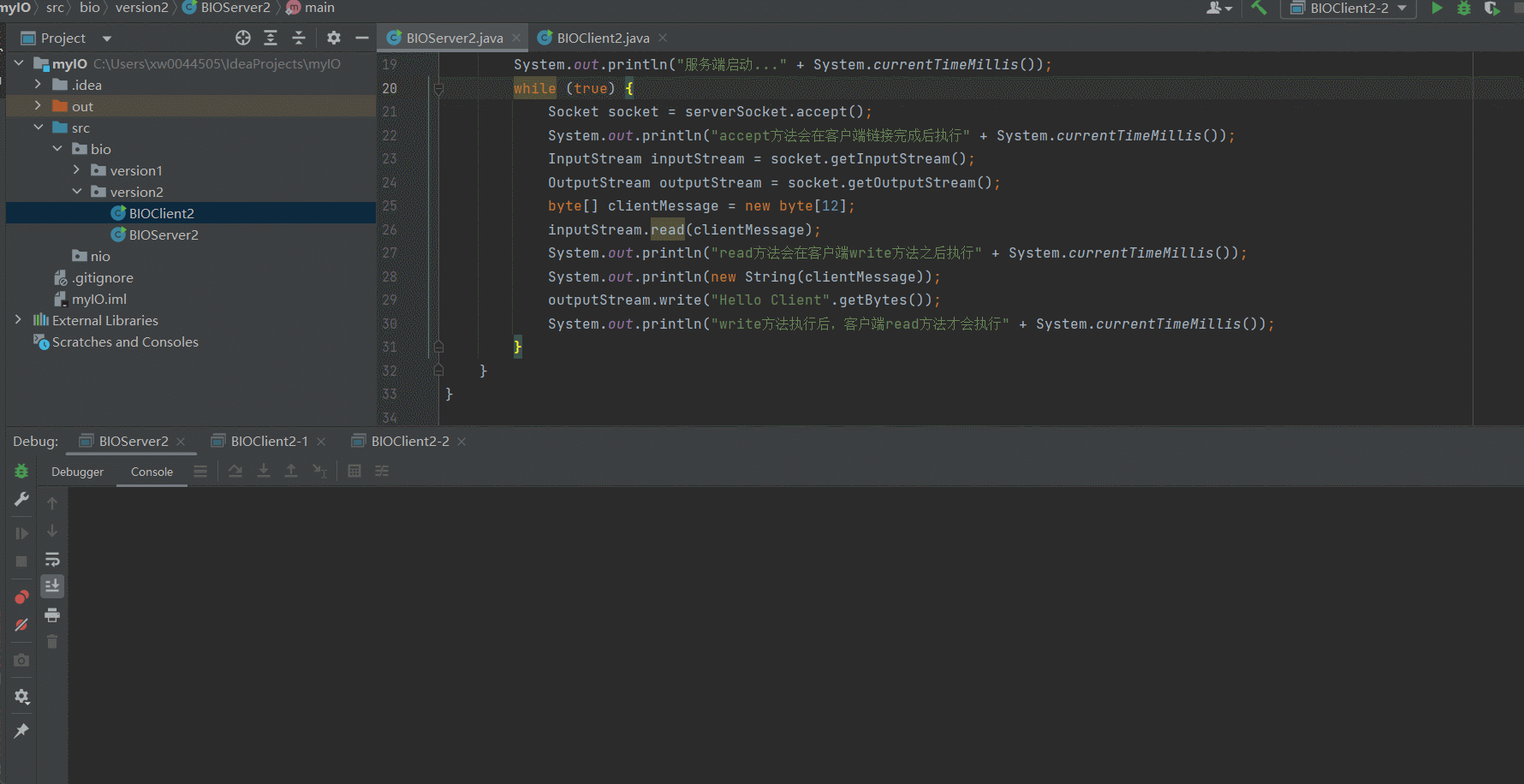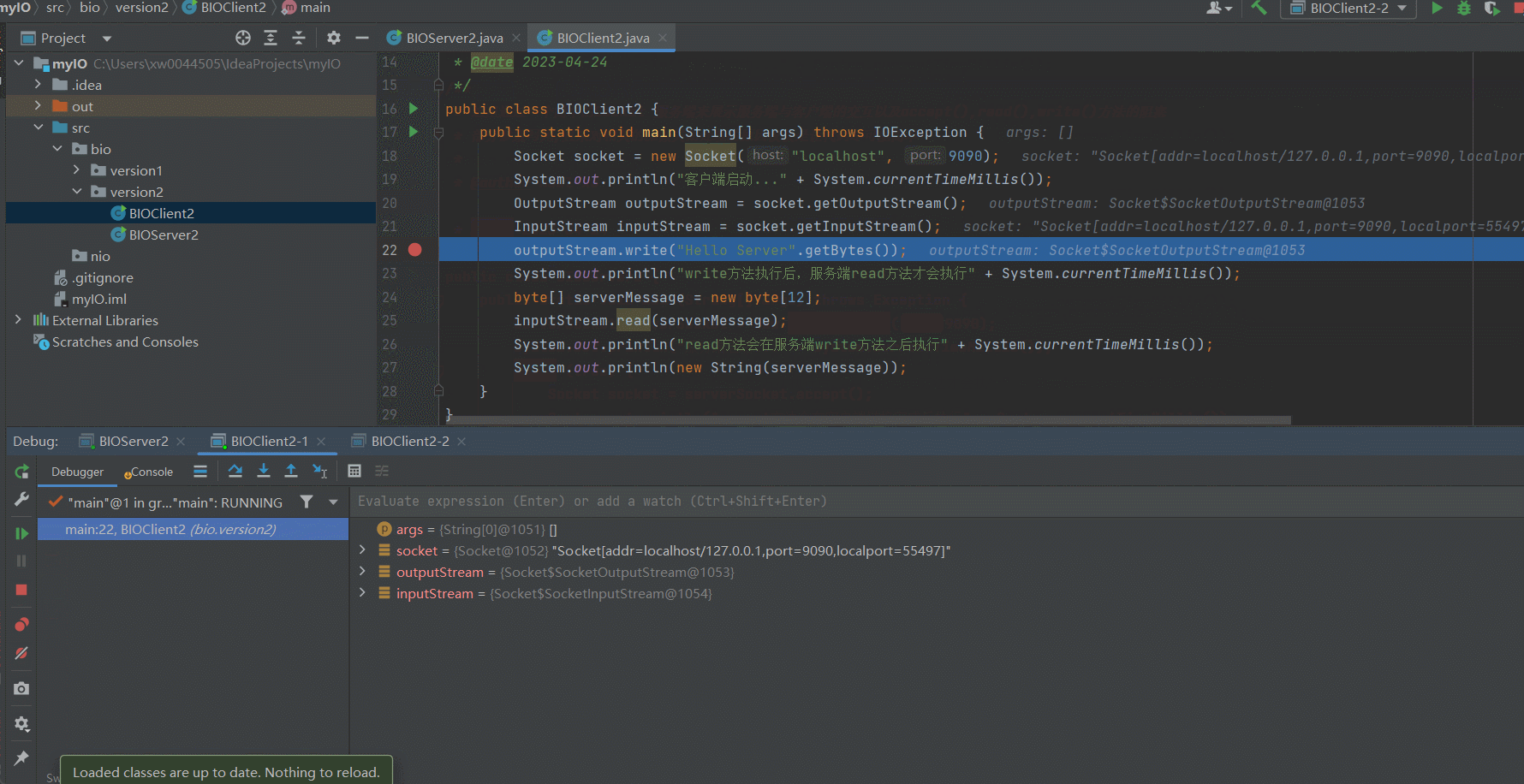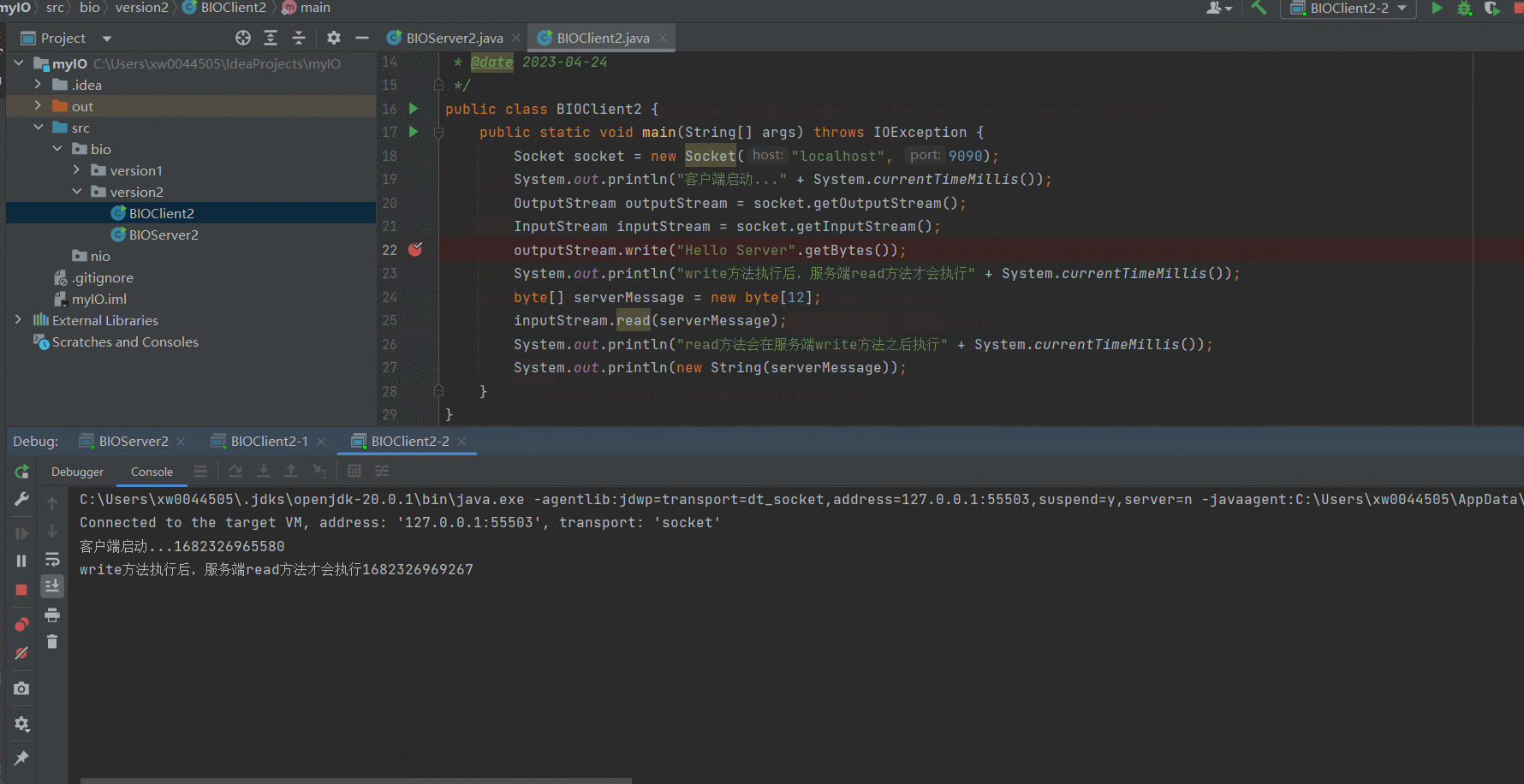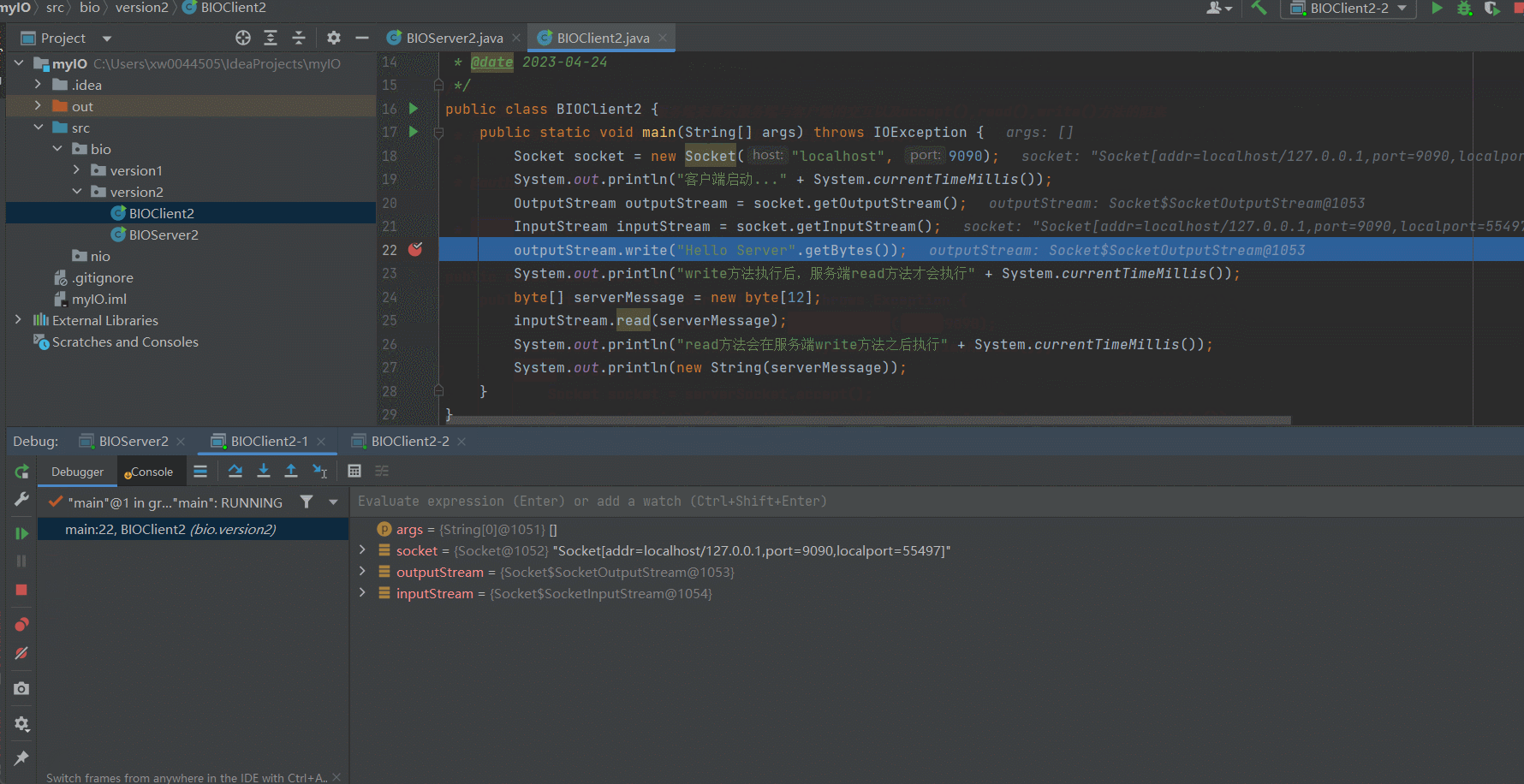
可以看到,因为我们在Client2-1的 outputStream.write("Hello Server".getBytes());打了断点,因此阻塞了Server的IO读写,因此,即使Client2-2向Server发送了response信息,依然无法获取到对应的响应信息。
很显然我们还需要接着对我们的Server进行改造,参考下面的version3.0进行改造~
# 2.4.4 version 3.0
在version3.0中,最大的问题是Server会被Client的IO流阻塞,为了解决这个问题,我们对Server端进行改造,Clinet依然不做修改,代码如下
- Server端代码
在Server3.0中,针对每一个Socket链接,我们单独起新的线程进行处理,这样一个链接的IO阻塞就不会影响其他的链接了
package bio.version3;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
/**
* 这里通过一个简单的Socket 服务端来展示服务端与客户端的交互以及accept(),read(),write()方法的阻塞
* 部分参数写死,且未对相关的流做关闭处理的原因仅仅是让代码尽可能简单
*
* @author howl-xu
* @version 1.0
* @date 2023-04-24
*/
public class BIOServer3 {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket(9090);
System.out.println("服务端启动..." + System.currentTimeMillis());
while (true) {
Socket socket = serverSocket.accept();
System.out.println("accept方法会在客户端链接完成后执行" + System.currentTimeMillis());
asyncExecute(socket);
}
}
private static void asyncExecute(Socket socket) {
new Thread(() -> {
try {
InputStream inputStream = socket.getInputStream();
OutputStream outputStream = socket.getOutputStream();
byte[] clientMessage = new byte[12];
inputStream.read(clientMessage);
System.out.println("read方法会在客户端write方法之后执行" + System.currentTimeMillis());
System.out.println(new String(clientMessage));
outputStream.write("Hello Client".getBytes());
System.out.println("write方法执行后,客户端read方法才会执行" + System.currentTimeMillis());
} catch (IOException e) {
throw new RuntimeException(e);
}
}).start();
}
}
- Client端代码
在Client3.0中,我们不做任何修改,保持代码和Client1一致即可。
package bio.version3;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
/**
* 这里通过一个简单的Socket 客户端来展示服务端与客户端的交互以及accept(),read(),write()方法的阻塞
* 部分参数写死,且未对相关的流做关闭处理的原因仅仅是让代码尽可能简单
*
* @author howl-xu
* @version 1.0
* @date 2023-04-24
*/
public class BIOClient3 {
public static void main(String[] args) throws IOException {
Socket socket = new Socket("localhost", 9090);
System.out.println("客户端启动..." + System.currentTimeMillis());
OutputStream outputStream = socket.getOutputStream();
InputStream inputStream = socket.getInputStream();
outputStream.write("Hello Server".getBytes());
System.out.println("write方法执行后,服务端read方法才会执行" + System.currentTimeMillis());
byte[] serverMessage = new byte[12];
inputStream.read(serverMessage);
System.out.println("read方法会在服务端write方法之后执行" + System.currentTimeMillis());
System.out.println(new String(serverMessage));
}
}
某个ClientIO阻塞不会导致服务不可用
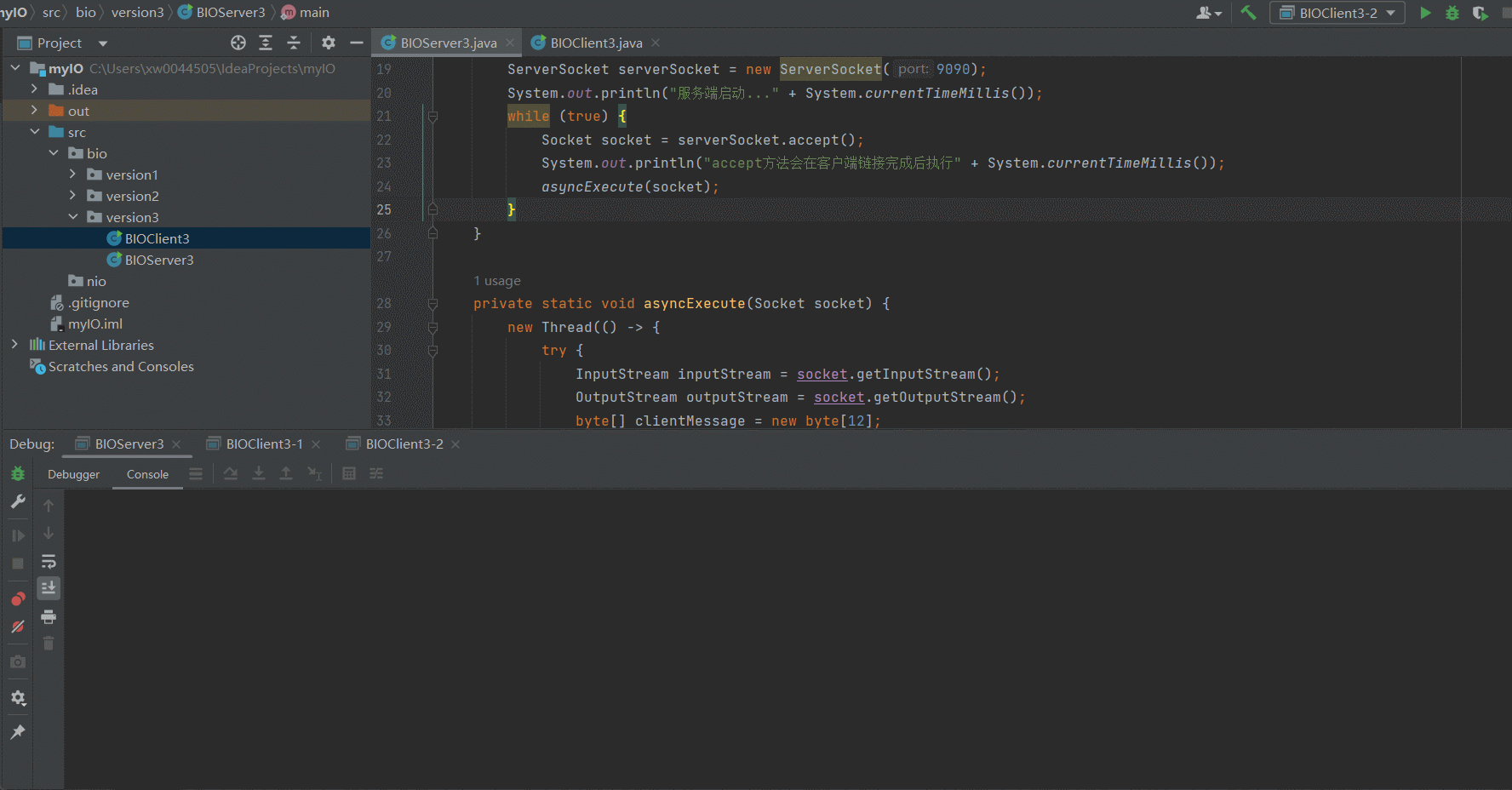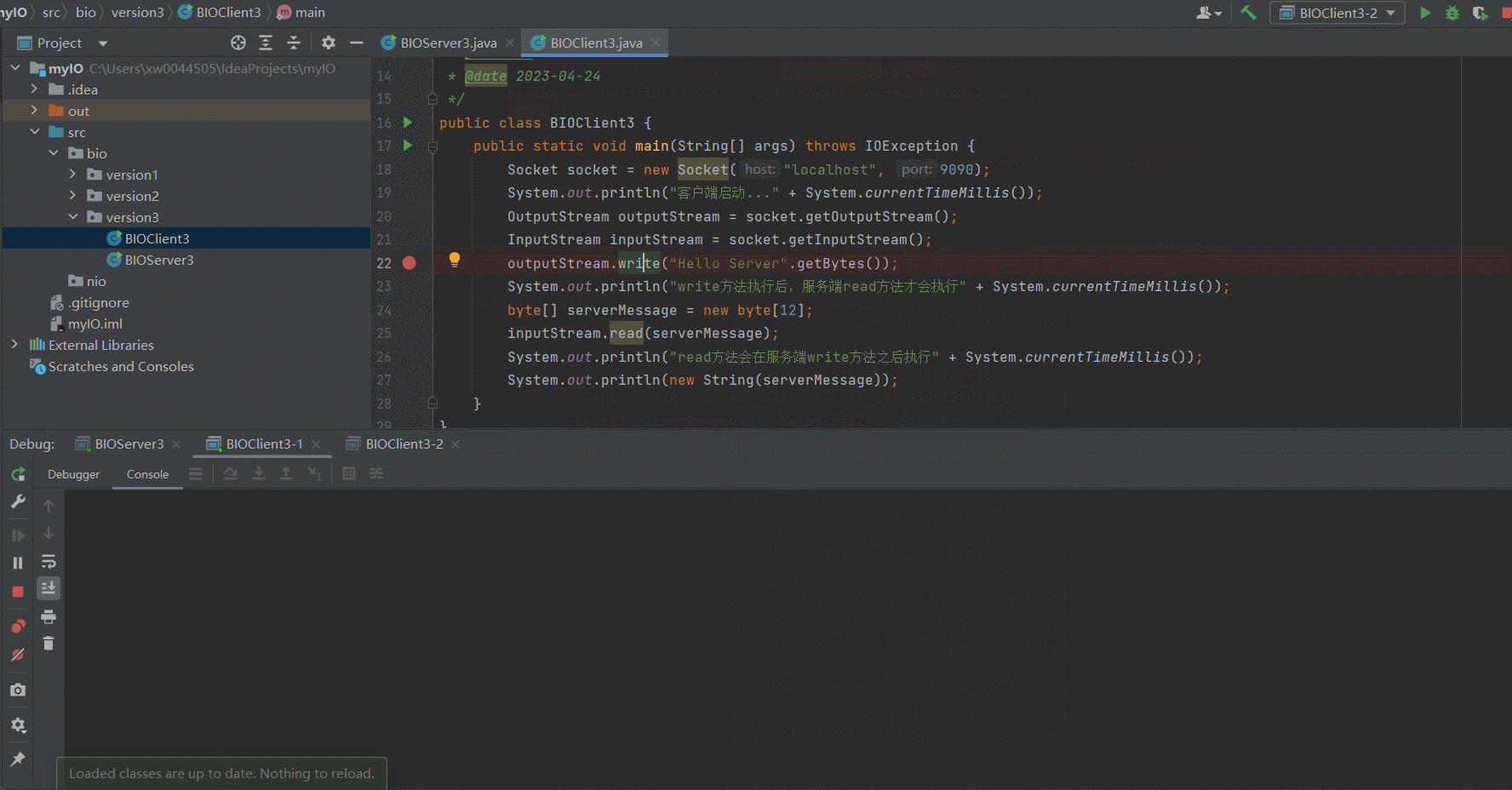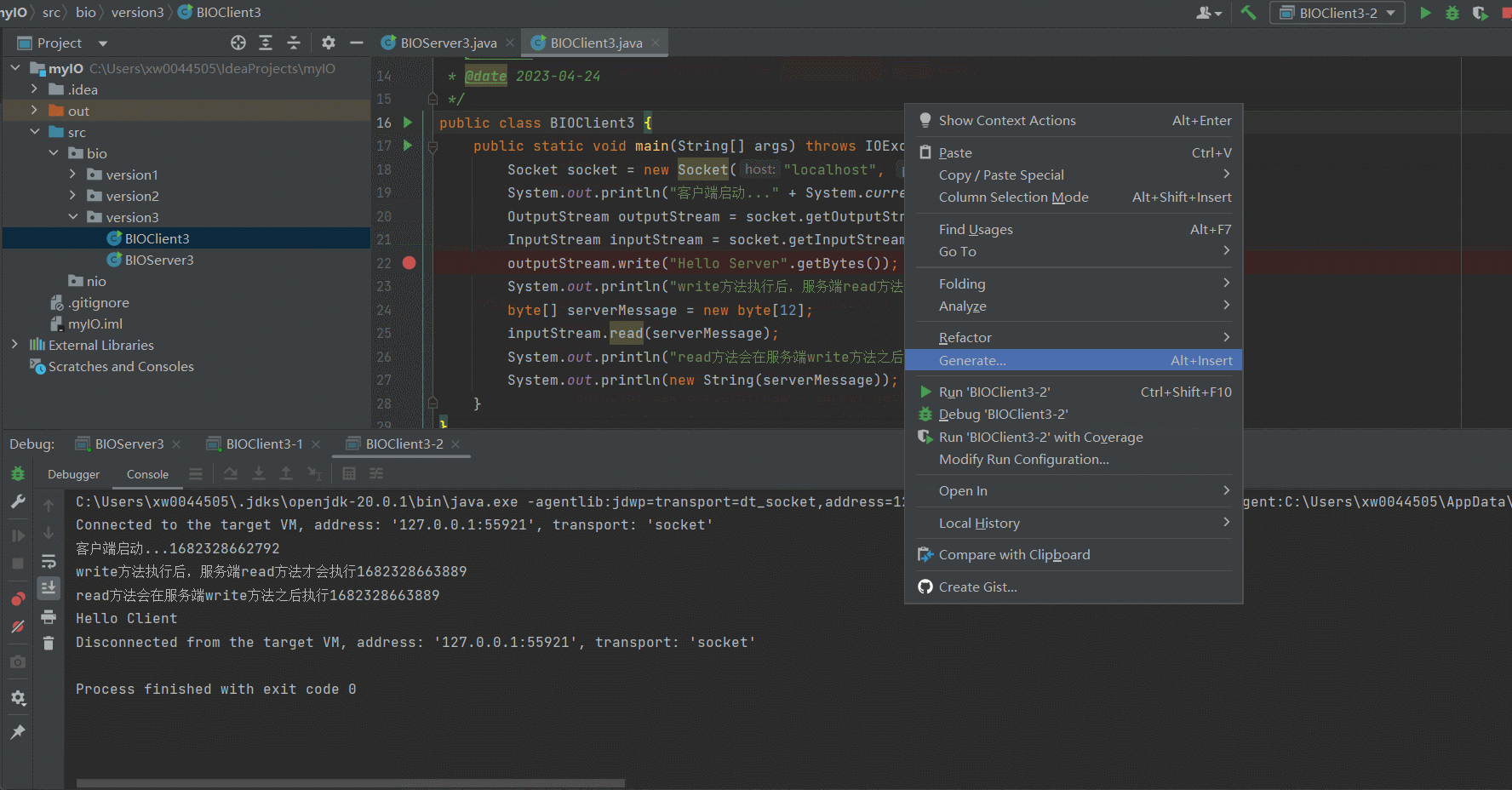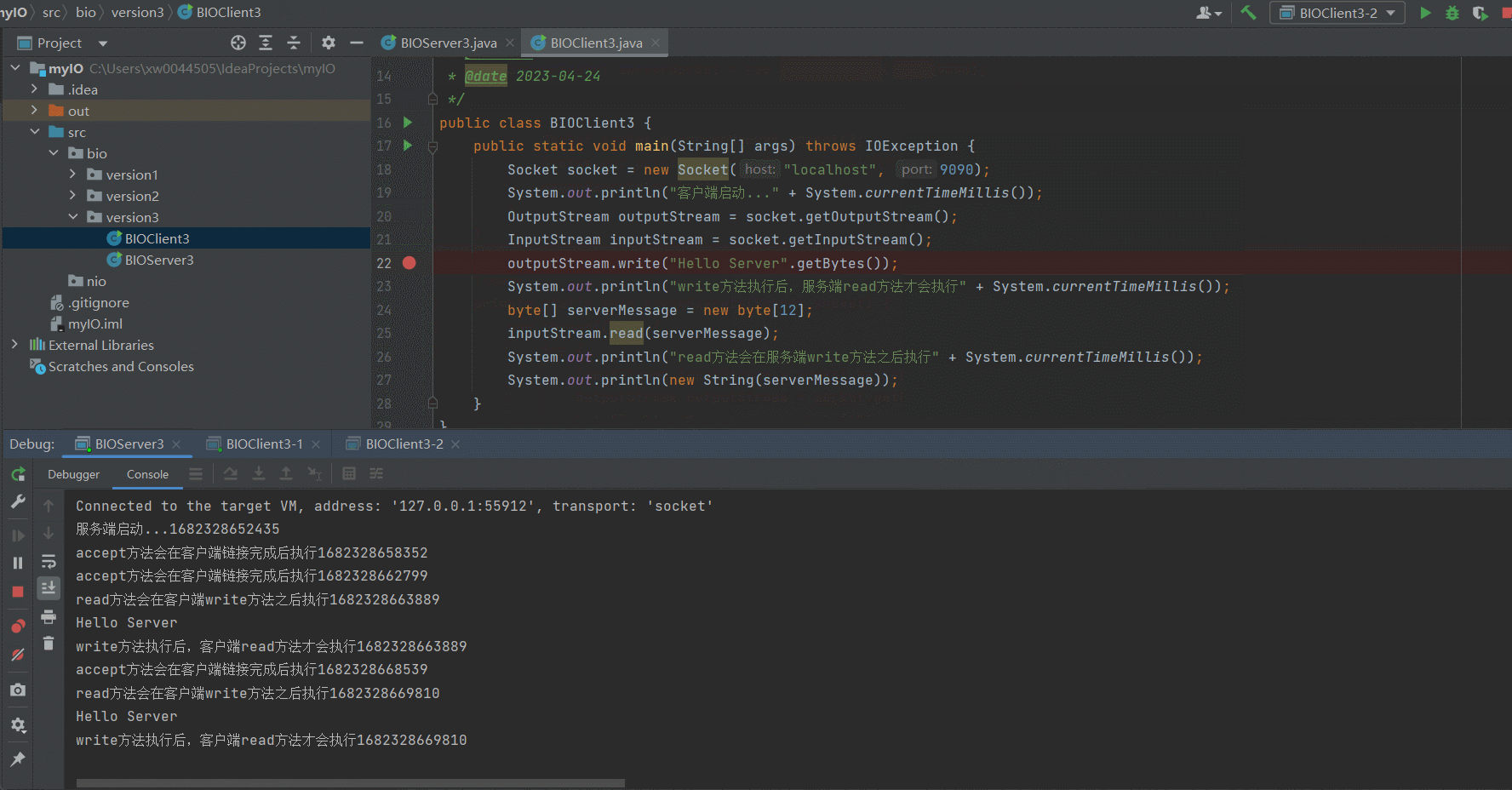
可以看到,即使我们在Client3-1的 outputStream.write("Hello Server".getBytes());打了断点,阻塞了Server中单个Socket链接的IO读写,也不会影响Client3-2向Server发送了response信息,同时获取到对应的响应信息。version3.0的问题
version3.0虽然是一个不错的解决方案,Server可以同时为多个Client提供服务了,每个Client互不影响,但是它并不是一个完美的解决方案,因为Server需要为每一个Client创建线程,服务端不停的创建线程肯定是有问题的~当然,也可以进行优化,比如使用线程池技术,当线程达到最大值时,服务不对新的链接提供服务~但是这些都是治标不治本的。归根到底,问题的症结还是出在IO的阻塞。在jdk1.5发行(2004年)之前,BIO模型虽然不是那么优秀,但是也足够在生产环境使用了。
# 2.5 Java NIO的工作方式
# 2.5.1 什么是NIO?
NIO(需要特别注意,java中的nio指的是新的io包,底层实现是基于IO多路复用的同步非阻塞模型,而不是异步非阻塞模型),关于NIO,其中的概念有点多,主要分三块,分别是buffer缓冲区,channel管道,selector选择器,这里暂时不对这三个概念详细展开(我自己理解的也不是太透彻),仅仅以一个demo展示NIO模式下的Server以及Client如何通信。
Java的NIO(new IO)技术,使用的就是IO多路复用模型(本质上也是同步IO模型)。在linux系统上,使用的是epoll系统调用。
- Server端代码
package nio;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
import java.util.Set;
/**
* @author Howl-Xu
* @version 1.0.0
* @Description: 这个网上抄来的东西还有很多问题需要改造
* @createTime 2021年05月23日 16:05:00
*/
public class NioServer1 {
public static void main(String[] args) throws Exception {
//创建ServerSocketChannel,-->> ServerSocket
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
InetSocketAddress inetSocketAddress = new InetSocketAddress(9090);
serverSocketChannel.socket().bind(inetSocketAddress);
serverSocketChannel.configureBlocking(false); //设置成非阻塞
//开启selector,并注册accept事件
Selector selector = Selector.open();
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select(2000); //监听所有通道
//遍历selectionKeys
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
if (key.isAcceptable()) { //处理连接事件
SocketChannel socketChannel = serverSocketChannel.accept();
socketChannel.configureBlocking(false); //设置为非阻塞
System.out.println("client:" + socketChannel.getLocalAddress() + " is connect");
socketChannel.register(selector, SelectionKey.OP_READ); //注册客户端读取事件到selector
} else if (key.isReadable()) { //处理读取事件,读取完客户端的信息后创建一个写事件
ByteBuffer byteBuffer = ByteBuffer.allocate(12);
SocketChannel channel = (SocketChannel) key.channel();
channel.read(byteBuffer);
System.out.println("client:" + channel.getLocalAddress() + " send " + new String(byteBuffer.array()));
channel.register(selector, SelectionKey.OP_WRITE); //注册客户端读取事件到selector
}
else if(key.isWritable()){
SocketChannel channel = (SocketChannel) key.channel();
channel.write(ByteBuffer.wrap("Hello Client".getBytes()));
// 将信息写入channel后即刻关闭链接
channel.close();
}
iterator.remove(); //事件处理完毕,要记得清除
}
}
}
}
- Client端代码
package nio;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
/**
* 这里通过一个简单的Socket 客户端来展示服务端与客户端的交互以及accept(),read(),write()方法的阻塞
* 部分参数写死,且未对相关的流做关闭处理的原因仅仅是让代码尽可能简单
*
* @author howl-xu
* @version 1.0
* @date 2023-04-24
*/
public class NioClient1 {
public static void main(String[] args) throws IOException, InterruptedException {
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("127.0.0.1", 9090));
socketChannel.configureBlocking(false);
ByteBuffer writeBuffer = ByteBuffer.wrap("Hello Server".getBytes());
socketChannel.write(writeBuffer);
//todo 这里线程休眠一段时间给服务端往channel的管道里填充内容
Thread.sleep(100);
ByteBuffer readBuffer = ByteBuffer.allocate(12);
socketChannel.read(readBuffer);
System.out.println(new String(readBuffer.array()));
socketChannel.close();
}
}
- 运行效果
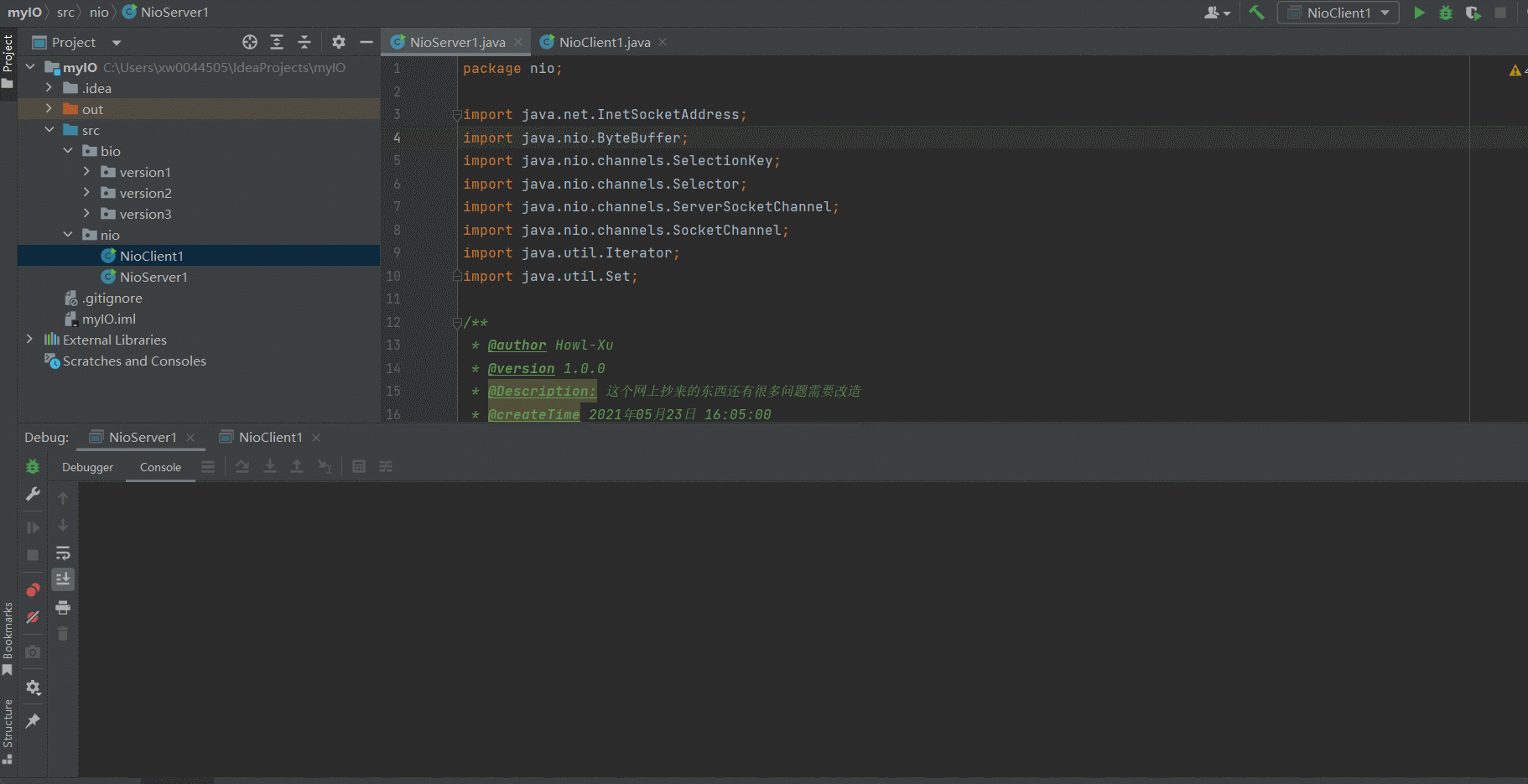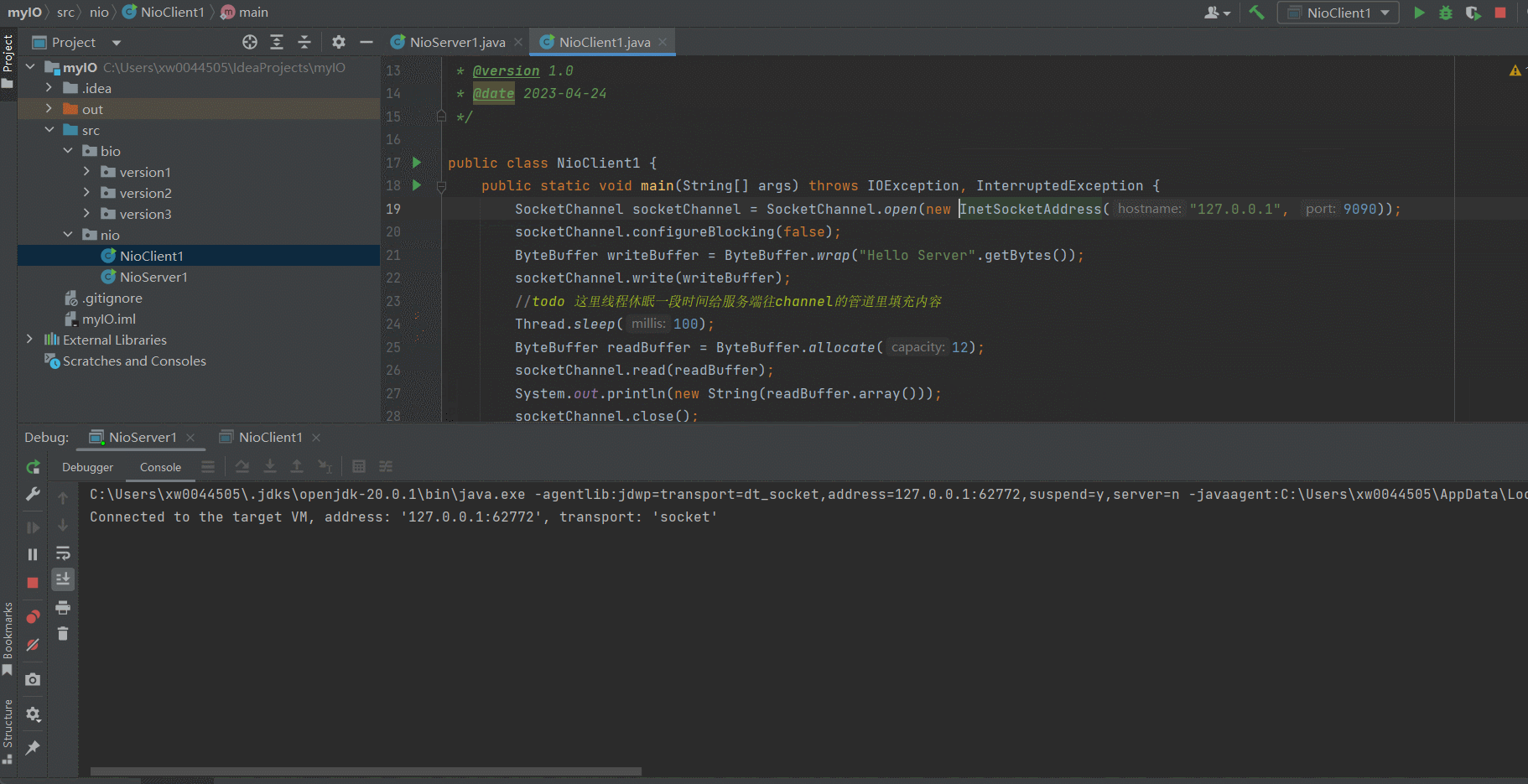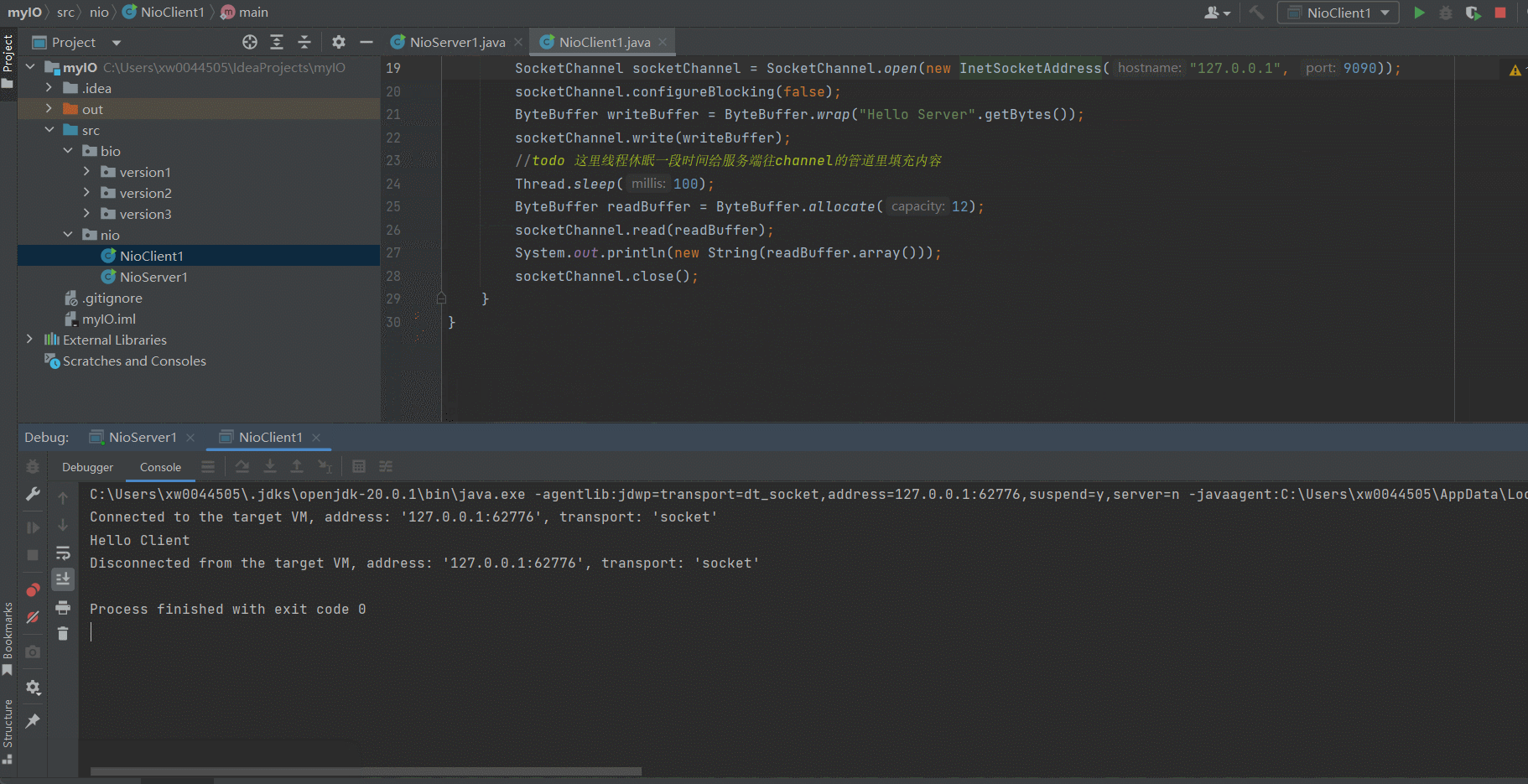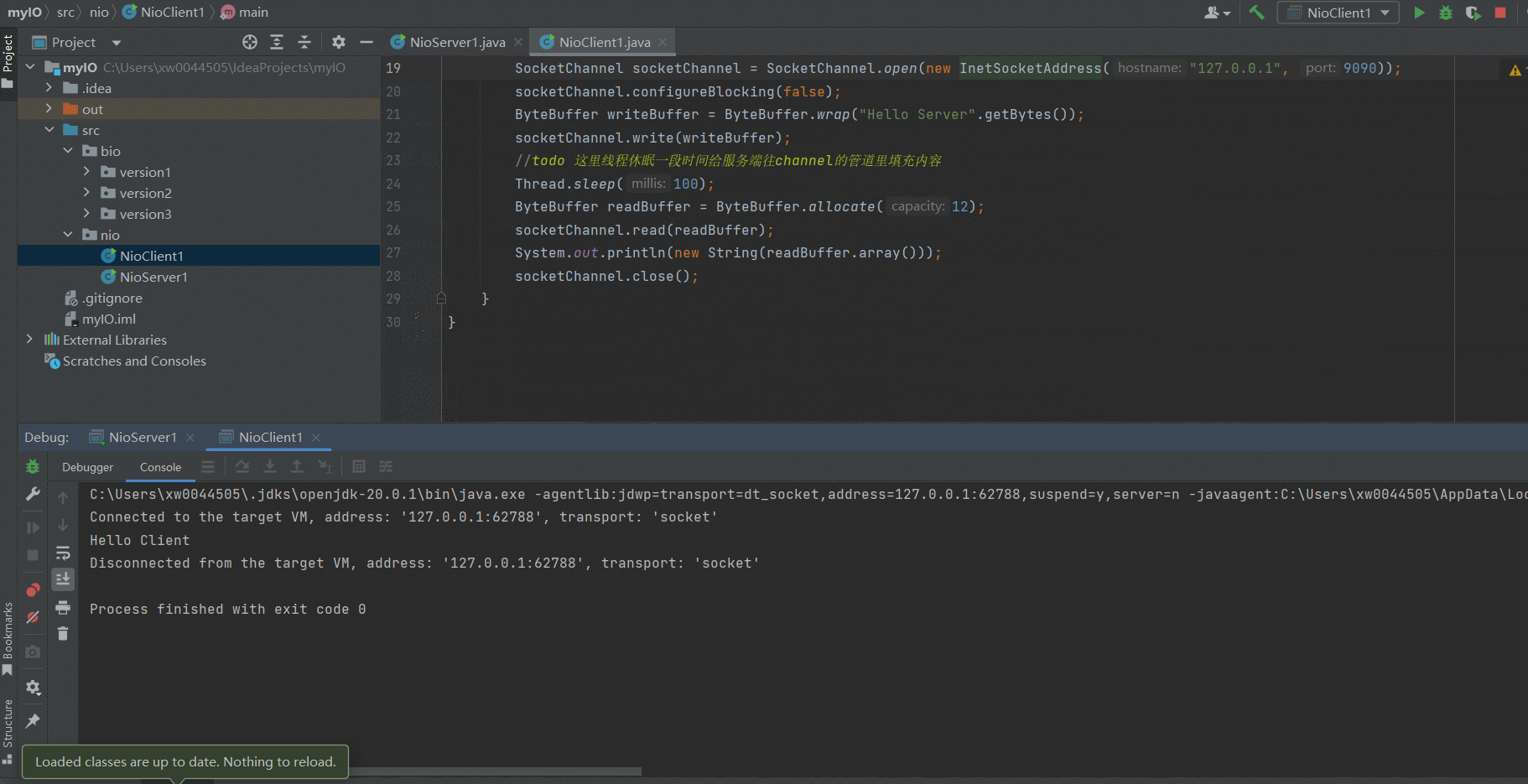
# 2.6 Java AIO的工作方式
# 2.6.1 什么是AIO?
Jav中AIO(Asynchronous I/O 异步非阻塞IO,其实这里没必要强调非阻塞,线程/进程都异步了,哪里还会出现阻塞呀)使用各种Handler去实现,简化了NIO编写Selector这部分的过程,其实相较NIO来说性能没有太多提升,这里仅附上可运行的demo用于演示,不详细讲解~
- Server端代码
package aio;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousServerSocketChannel;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.channels.CompletionHandler;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
/**
* @author Howl-Xu
* @version 1.0.0
* @Description: TODO AIO好像在UNIX还是LINUX上有BUG,性能也不见得比NIO强多少,所以不推荐使用
* TODO AIO使用各种Handler去实现,简化了NIO编写Selector这部分的过程,但是有BUG
* TODO 而且从理论上分析,NIO和BIO的性能不会有什么差异
* TODO 反正没有任何主流的框架用AIO模型做WEB Server
* TODO AIO相对NIO代码更简单,但是没实际的性能提升,而且有BUG,不需要详细掌握
* @createTime 2021年05月23日 17:41:00
*/
public class AIOEchoServer {
public final static int PORT = 9090;
public final static String IP = "127.0.0.1";
private AsynchronousServerSocketChannel server = null;
public AIOEchoServer(){
try {
//同样是利用工厂方法产生一个通道,异步通道 AsynchronousServerSocketChannel
server = AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(IP,PORT));
} catch (IOException e) {
e.printStackTrace();
}
}
//使用这个通道(server)来进行客户端的接收和处理
public void start(){
System.out.println("Server listen on "+PORT);
//注册事件和事件完成后的处理器,这个CompletionHandler就是事件完成后的处理器
server.accept(null,new CompletionHandler<AsynchronousSocketChannel,Object>(){
final ByteBuffer buffer = ByteBuffer.allocate(1024);
@Override
public void completed(AsynchronousSocketChannel result,Object attachment) {
System.out.println(Thread.currentThread().getName());
Future<Integer> writeResult = null;
try{
buffer.clear();
result.read(buffer).get(100,TimeUnit.SECONDS);
System.out.println("In server: "+ new String(buffer.array()));
//将数据写回客户端
buffer.flip();
writeResult = result.write(buffer);
}catch(InterruptedException | ExecutionException | TimeoutException e){
e.printStackTrace();
}finally{
server.accept(null,this);
try {
writeResult.get();
result.close();
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
@Override
public void failed(Throwable exc, Object attachment) {
System.out.println("failed:"+exc);
}
});
}
public static void main(String[] args) {
new AIOEchoServer().start();
while(true){
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
- Client端代码
package aio;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.AsynchronousSocketChannel;
import java.nio.channels.CompletionHandler;
/**
* @author Howl-Xu
* @version 1.0.0
* @Description: 请描述一下这个类文件吧
* @createTime 2021年05月23日 17:42:00
*/
public class AIOClient {
public static void main(String[] args) throws IOException {
final AsynchronousSocketChannel client = AsynchronousSocketChannel.open();
InetSocketAddress serverAddress = new InetSocketAddress("127.0.0.1",9090);
CompletionHandler<Void, ? super Object> handler = new CompletionHandler<Void,Object>(){
@Override
public void completed(Void result, Object attachment) {
client.write(ByteBuffer.wrap("Hello".getBytes()),null,
new CompletionHandler<Integer,Object>(){
@Override
public void completed(Integer result,
Object attachment) {
final ByteBuffer buffer = ByteBuffer.allocate(1024);
client.read(buffer,buffer,new CompletionHandler<Integer,ByteBuffer>(){
@Override
public void completed(Integer result,
ByteBuffer attachment) {
buffer.flip();
System.out.println(new String(buffer.array()));
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void failed(Throwable exc,
ByteBuffer attachment) {
}
});
}
@Override
public void failed(Throwable exc, Object attachment) {
}
});
}
@Override
public void failed(Throwable exc, Object attachment) {
}
};
client.connect(serverAddress, null, handler);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- 运行效果
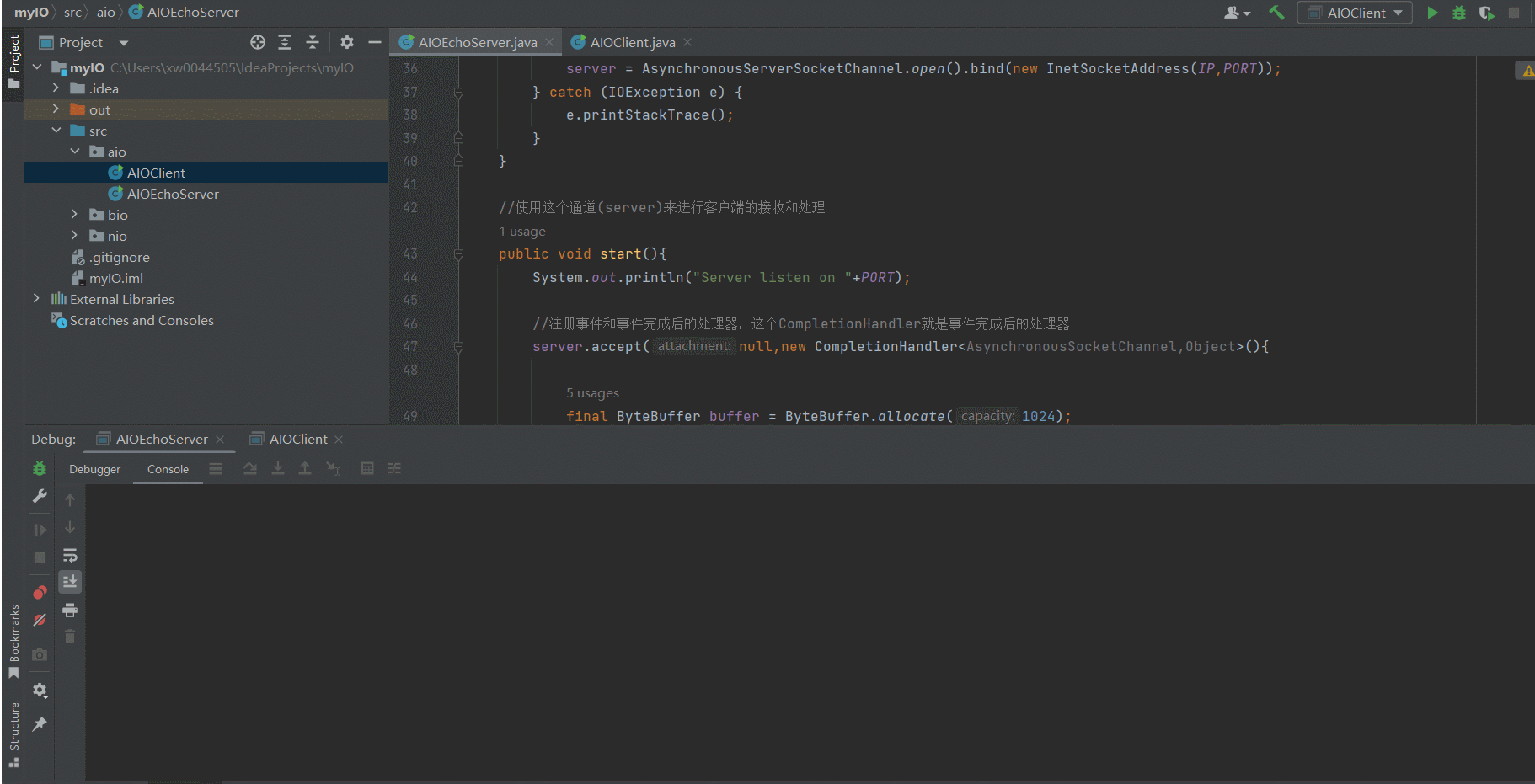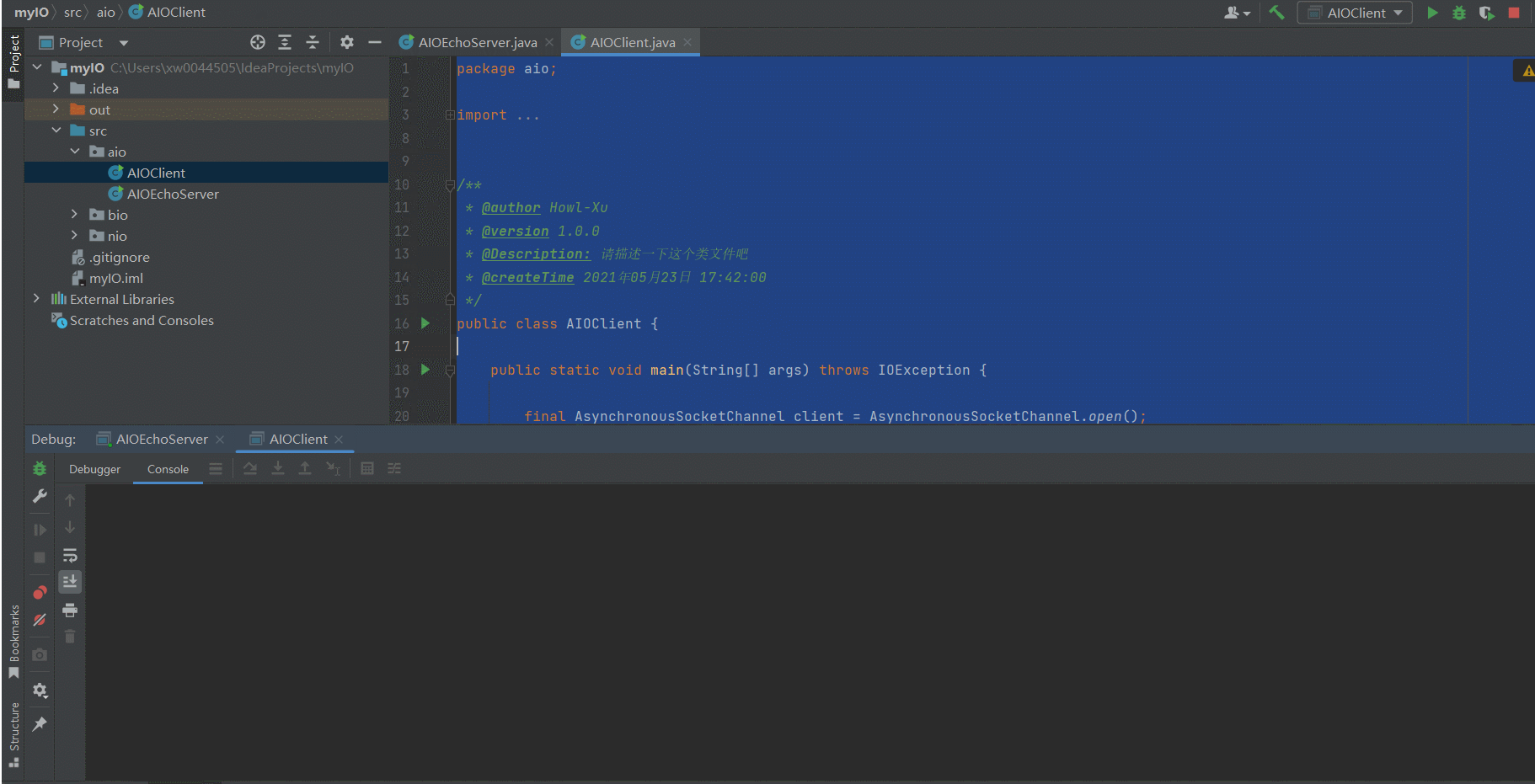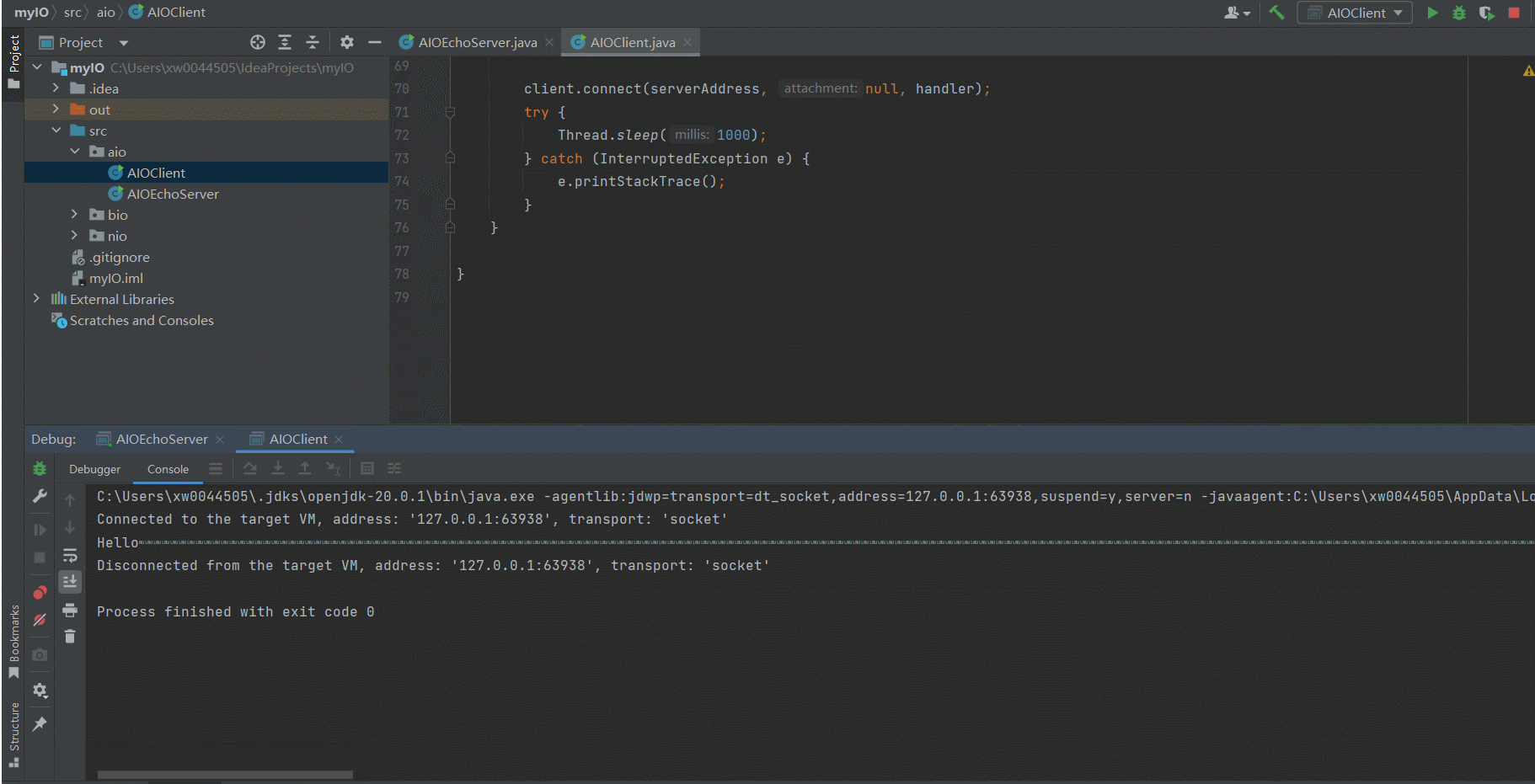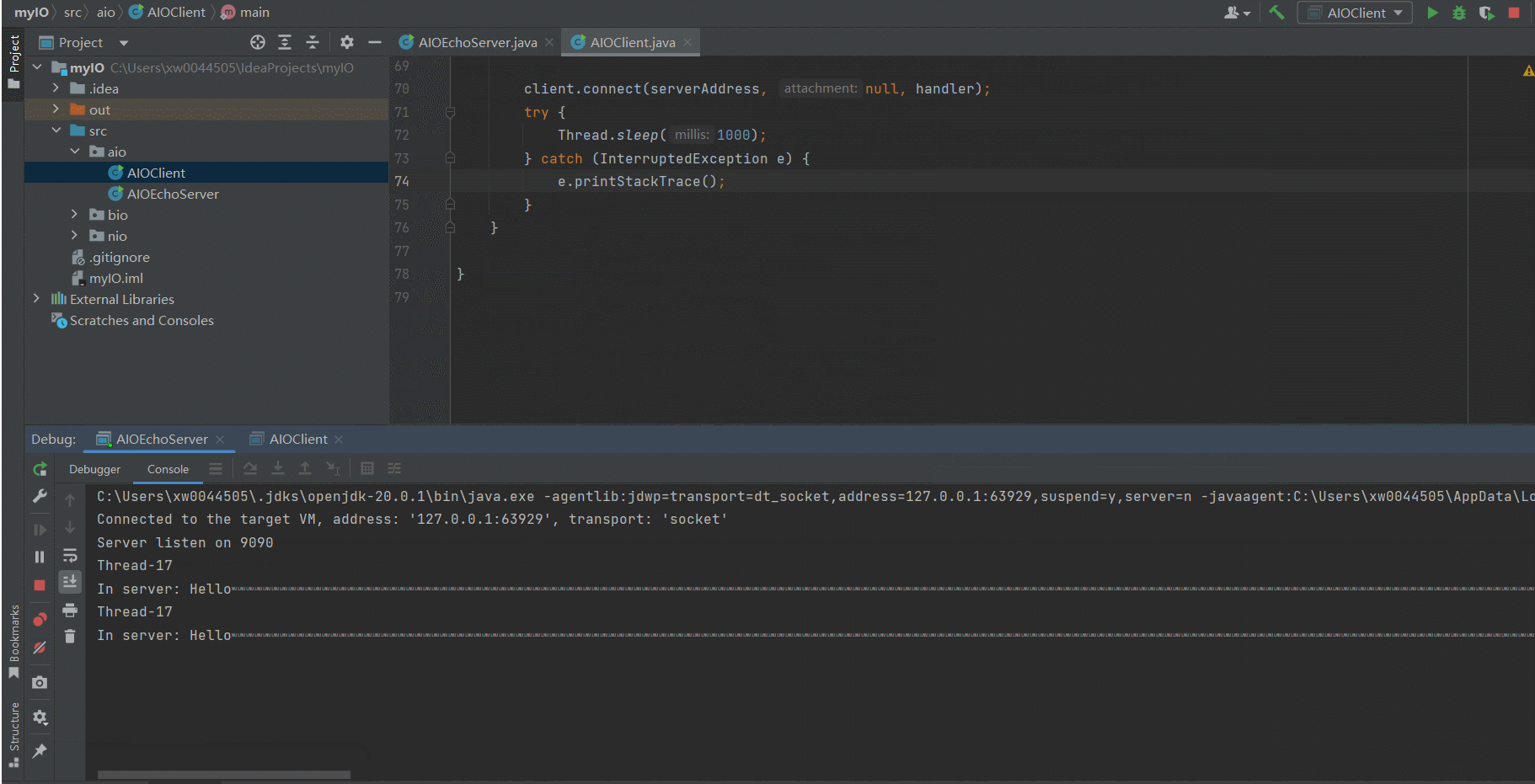
SOCKERT及端口号占用问题
BIO,NIO,AIO服务端以及客户端的区别?
客户端(浏览器)与服务端(Server)都可以使用BIO,NIO,AIO进行交互,也就是说,即使服务端是BIO,客户端依然可以是AIO。按现在的情况,浏览器大概是使用NIO Client,服务端使用NIO Server。像nginx,直接使用epoll模型,性能更快且线程数更多(支持更高的并发)。
BIO与Socket通信
当使用BIO进行Socket通信的时候,对每一个Socket链接,服务端与客户端都会同时创建一个文件以及启动一个线程,数据传输的过程就对应文件的读写过程。当文件可读/可写的时候,操作系统会发出文件读写信号,当线程执行文件read(),write()方法的时候没有收到读写信号,当前线程就会阻塞。说白了BIO的出现很早,类比到我们开发代码就是代码能完成基本的业务逻辑。这个阶段,文件IO读写阻塞线程也不会成为什么“瓶颈”。
IO多路复用与NIO与Socket通信
随着访问量增加,IO阻塞线程成为了瓶颈,这时,操作系统也提供了新的优化方案,也就是IO多路复用(select,poll,epoll),在文件不可读写的时候,当前线程并不会阻塞,操作系统提供了底层支持后,Java1.4也提供了新的IO代码,也就是NIO,对应Selector,Channel,Buffer等几个关键类。至此,Java Web服务器(如Tomcat)的底层Socket就被优化成了NIO方案,服务器的性能也有所提高。
BIO,NIO服务端与客户端
基于BIO,NIO我们可以同时实现服务端以及客户端,服务端与客户端通信是基于Socket,而不是基于IO读写,因此,即使我们的服务端是基于BIO实现,客户端(如浏览器)是基于NIO实现的,他们依然可以正常通信。
# 3.Java Web中的中文编码问题
第3节所有内容均来自《深入分析Java Web技术内幕》一书。
# 3.1 几种常见的编码格式
# ASCII码
ASCII码占用1个byte,总共有128个字符,用1个字节的低7位表示,0~31是用来控制字符如换行、回车、删除等,32到126是打印字符,可以通过键盘输入并且能够显示出来。
# ISO-8859-1
ASCII的128字符显然是不够用的,于是ISO组织在ASCII的基础上又定制了新标准来扩展ASCII,这个新标准就是ISO-8859-1,ISO-8859-1同样占用1个byte,它可以表示256个字符。
# GB2312
GB2312的全称是《信息技术中文编码字符集》,它是双字节编码,总的编码范围是A1~F7,其中A1~A9是符号区,总共包含682个符号,B0~F7是汉字区,包含6763个汉字。
# GBK
GBK全称是《汉字内码扩展规范》,它的出现是为了扩展GB2312,并加了更多的汉字。它能表示21003个汉字,它的编码和GB2312是兼容的,也就是用GB2312编码的汉字可以用GBK来解码,并且不会出现乱码。
# UTF-16
说到UTF必须提到Unicode,ISO试图创建一个全新的超语言字典,世界上所有的语言都可以通过这个字典来互相翻译。UTF-16具体定义了Unicode字符在计算机中的存取方法。UTF-16用两个字节来表示Unicode的转化格式,它采用超长的表示方法,即不论什么字符都用两个字节来表示。
两个字节是16个bit,所以叫UTF-16。UTF-16表示字符非常方便,每两个字节表示一个字符,这就大大简化了字符串操作,这也是Java以UTF-16作为内存的字符存储格式的一个很重要的原因。
# UTF-8
UTF-16采用统一两个字节来表示一个字符,虽然在表示上非常简单,方便,但是也有其缺点,有很大一部分字符用一个字节就可以表示的现在要用两个字节表示,存储空间放大了一倍,在现在的网络带宽还非常有限的情况下,这样会增大网络传输的流量,而且也没有必要。而UTF-8采用了一种变长技术,每个编码区域有不同的编码长度。不同类型的字符由1~6个字节组成。
UTF-8有如下的编码规则:
如果是1个字节,最高位(第8位)为0,则表示这是一个ASCII字符,可见ASCII编码已经是UTF-8了。
如果是1个字节,以11开头,则连续的1的个数暗示这个字符的字节数,例如110xxxxx代表它是双字节UTF-8字符的首字节。
如果是1个字节,以10开始,表示它不是首字节,则需要向前查找才能得到当前字符的首字节。
# 3.2 HTTP请求中哪些地方涉及编解码
在一个HTTP请求中,请求URL,请求Header,POST表单参数,后端服务数据库中数据,文件等都涉及编码及解码操作。
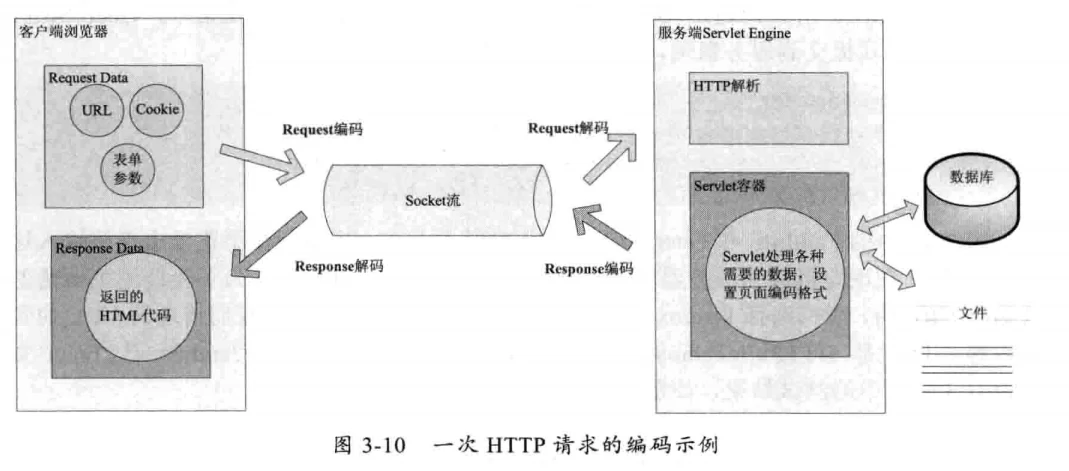
# URL的编解码
用户提交一个URL,这个URL中可能包含中文,因此需要编码。以下是一个URL的构造:
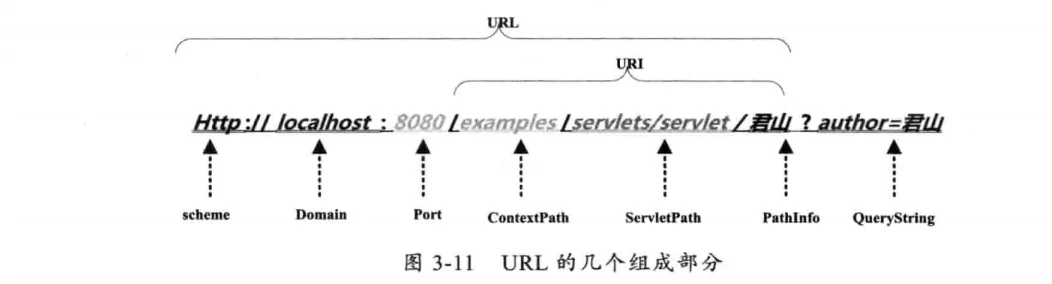
浏览器(客户端)对URL中PathInfo使用UTF-8格式编码,对QueryString用GBK进行编码,浏览器编码URL是将非ASCII字符按照某种编码格式编码成16进制数字后再将每个16进制表示的字节前加上“%”。
服务端(如tomcat)会对PathInfo编码结果进行解码,Tomcat会读取
服务端(如tomcat)会对QueryString编码结果进行解码,解码字符集默认使用ISO-8859-1,如果修改了
# HTTP Header的编解码
Header的编解码只能使用ISO-8859-1,且不支持其他编码格式,所以如果你设置的Header中有非ASCII字符,解码中肯定会出现乱码。
我们在添加Header时也是一样,不要在Header中传递非ASCII字符,如果一定要传递,可以先将这些字符用URLEncoder编码,再添加到Header中,这样在从浏览器到服务端的传递就不会丢失信息了,我们要访问这些项时再按照相应的字符集解码即可。
# POST请求Body部分的编解码
POST表单中的内容是通过HTTP的BODY传递到服务端的,当我们在页面上点击提交按钮时浏览器首先根据ContentType的Charset编码格式对在表单中填入的参数进行编码,然后提交到服务端,服务端同样使用ContentType中的字符集进行解码。
# HTTP ResponseBody的编解码
当用户请求的资源已经成功获取后,这些内容将通过Response返回给客户端浏览器。这个过程要先经过编码,再到浏览器中解码,编解码字符集可以通过response.setCharacterEncoding来设置,它将覆盖request.getCharacterEncoding的值,并且通过Header的Content-Type来返回客户端。浏览器接收到返回的Socket流时将通过Content-Type的charset来解码。如果返回的HTTP Header中Content-Type没有设置charset,那么浏览器将根据HTML的<meta HTTP-equiv="Content-Type" content="text/html;charset=GBK"/>标签中的charset来解码。如果也没有定义,那么浏览器将使用默认的编码来解码。
# 3.3 JS文件中的编解码
# 外部引入的js文件
我们使用<script src="statics/js/script.js" charset="GBK"/>引入外部js文件的时候需要指定编码格式,如不指定,浏览器会默认使用引入这个js的当前页面的默认字符集解析js文件,如格式不一致,就会出现乱码问题。
# JS的URL编码
通过JS发起异步请求时调用的URL的默认编码也受浏览器影响,针对这种情况,提前使用如下encodeURI(),decodeURI()两个方法对URL进行编解码即可。
- encodeURI() 将这个URL中的特殊字符进行编码,可以使用decodeURI()函数进行解码。
# Java与JS的编解码问题
在前端用encodeURI()编码的URL可以在后端用Java中的URLDecode类解码,同理在后端用URLEncode()编码的URL也可以通过js中的decodeURI()解码。
# 3.4 其他编解码场景
除了URL和参数编码问题,在服务端还有很多地方可能涉及编码,如可能需要读取XML,JSP,从数据库读取数据等。
XML文件可以通过设置头来指定编码格式:
<?xml version="1.0" encoding="UTF-8"?>
# 3.5 常见编解码问题分析
# 中文变成了看不懂的字符
字符串在解码时所使用的字符集与编码时使用的字符集不一致会导致汉字变成看不懂的乱码,而且一个汉字字符会变成两个乱码字符。

# 一个汉字变成一个问号
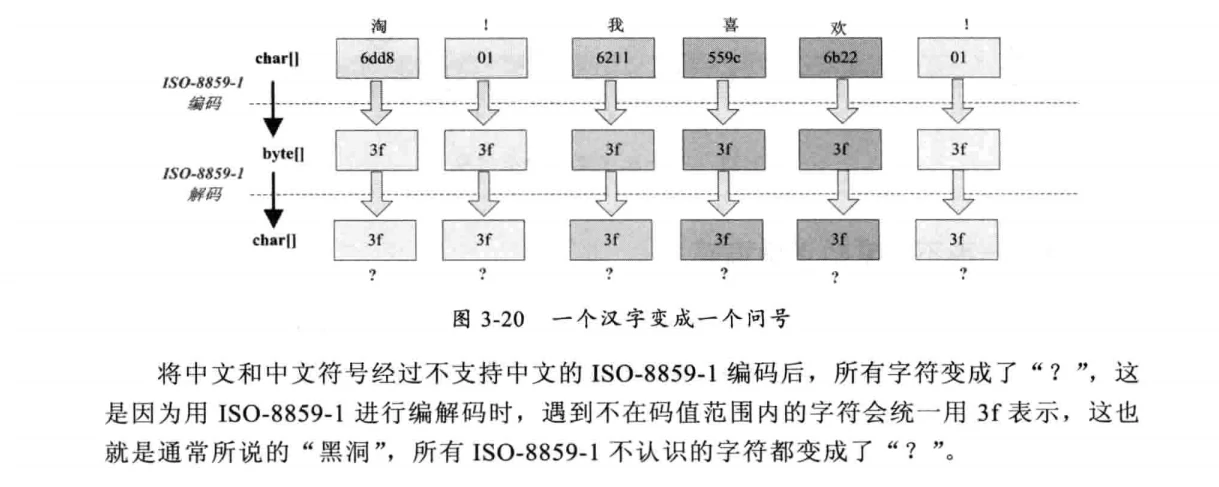
# 一个汉字变成两个问号
这种情况比较复杂,中文经过了多次编码和解码,其中任何一次编码/解码异常就会出现中文变成?的情况,这时就需要仔细查看中间的编解码环节,找到出现编码错误的地方。

# 一种不正常的正确编码
有一种情况,我们在request.getParameter获取参数时,如果直接使用request.getParameter(name)会出现中文乱码;如果使用String(getParameter(name).getBytes("ISO-8859-1"),"GBK");则可以正常获取中文。这种情况如下图所示:
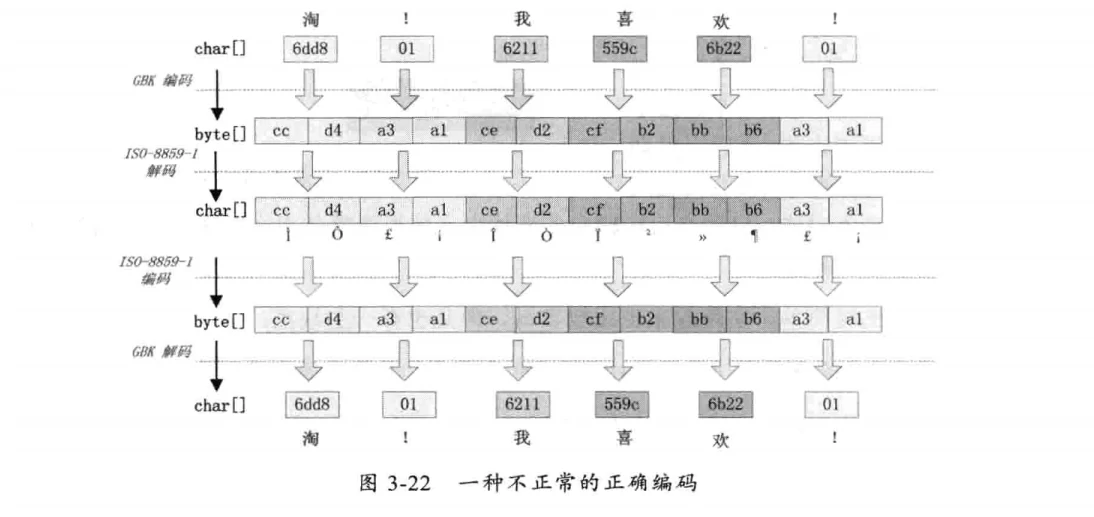
这种情况是这样产生的,ISO-8859-1字符集的编码范围是0000~00FF,正好和一个字节的编码范围对应。这种特性保证了使用ISO-8859-1进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误的“拆分”成两个欧洲字符,但由于输出时也使用了ISO-8859-1,结果被“拆分”的中文字符的两半又被合并到了一起,刚好组成了一个正确的汉字。虽然最终能获取到正确的汉字。但一定不要写这种代码,通过这种方式增加了一次额外的编码与解码。正确的方式应该是在Tomcat的配置文件中将useBodyEncodingForURI设置为“true”,这样tomcat就不会使用默认的ISO-8859-1解析了。
# 4.Javac编译原理
Javac的编译流程主要有词法分析,语法分析,语义分析,字节码生成这4个核心组成部分。本节内容基于来自《深入分析Java Web技术内幕》一书。
# 4.1 词法分析
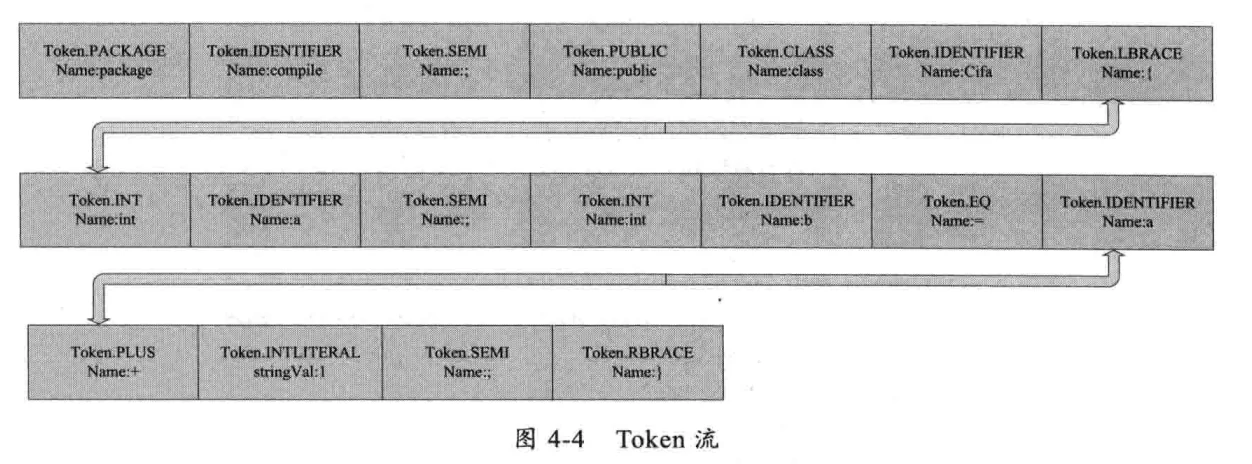
词法分析器逐个字符读取.java文件,将.java文件转换成Token(标记)流,Token流用于在语法分析过程中生成语法树。如下代码:
package compile;
public class Cifa {
int a;
int c = a + 1;
}
这个java文件的解析Token流如下图所示:
# 4.2 语法分析
根据Token集合生成抽象语法树,语法树是一种用来表示程序代码语法结构的表现形式,语法树的每一个节点都代表着程序代码中的一个语法结构,例如包、类型、修饰符。语法分析主要有com.sun.tools.javac.parser.Parser类来实现。
package jvm;
/**
* @author sh
*/
public class ClassTest {
public int add(int a, int b) {
return a + b;
}
}
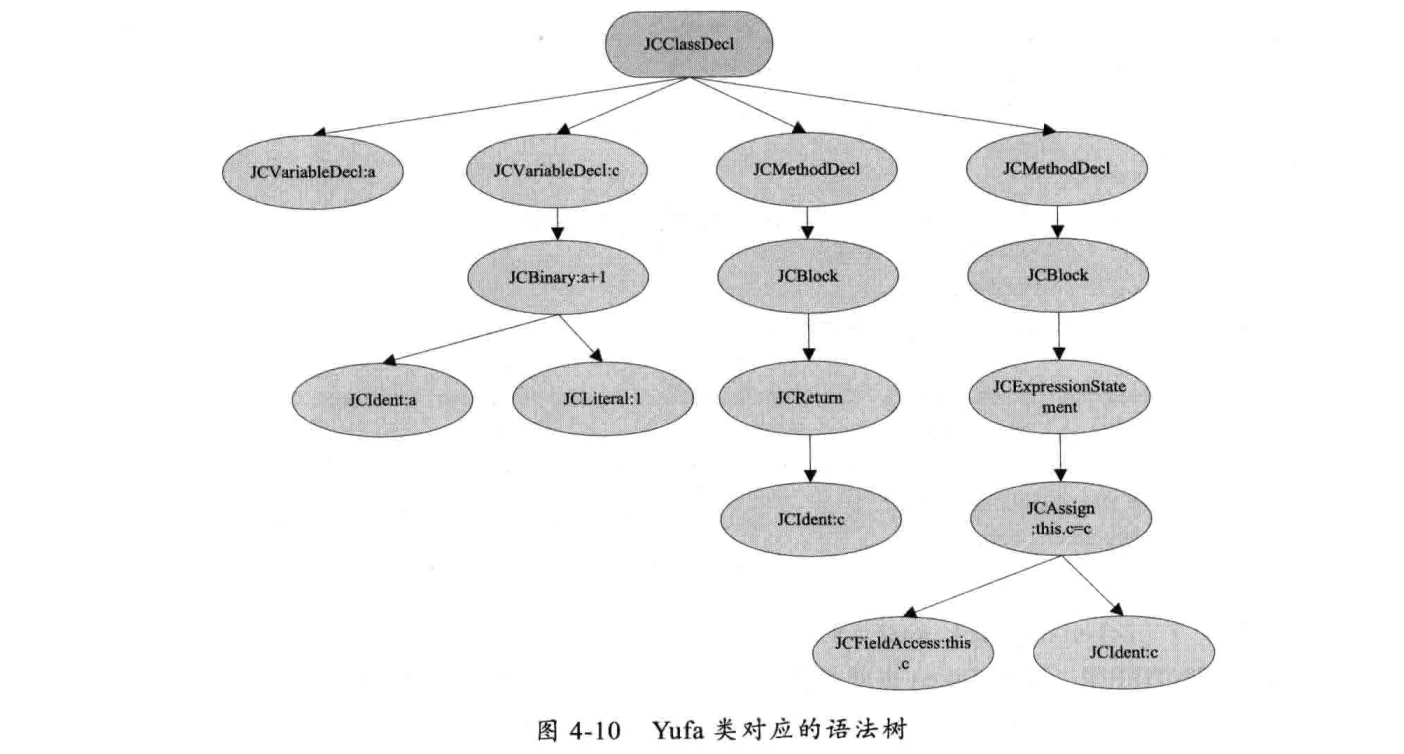
上述这段代码生成的抽象语法树如下(IDEA JDT AstView插件可以查看抽象语法树):

public class Yufa {
int a;
private int c = a + 1;
public int getC(){
return c;
}
public int setC(int c){
this.c = c;
}
}
上述这段代码生成的抽象语法树如下:
# 4.3 语义分析
语法分析器将Token流解析成更加结构化的,可操作的一颗语法树,但是这颗语法树太枯燥了,离我们的目标Java字节码的产生还有很大的距离。我们必须要在这颗语法树的基础上再做一些处理,如给类添加默认的构造函数,检查变量在使用前是否已经初始化,将一些常量进行合并处理,检查操作变量类型是否匹配,检查所有的操作语句是否可达,检查checked exception异常是否已捕获/抛出,解除语法糖,等等。这些操作完成之后,经过处理的语法树就可以用来生成字节码了。
# 4.4 字节码生成
经过语义分析器完成后的语法树已经非常完善了,接下来Javac会调用com.sun.tools.javac.jvm.Gen类遍历语法树,生成最终的Java字节码。
生成Java字节码需要如下两个步骤:
1.将Java方法中的代码块转化成符合JVM语法的命令形式,JVM的操作都是基于栈的,所有的操作都必须经过出栈和入栈来完成。
2.按照JVM文件的组织格式将字节码输出到以.class为扩展名的文件中。
如何防止按钮重复提交?
防重复提交需要前后端一起做,前端做了就可以很好的减轻后端的压力(如果前端能成功防重,进入后端的请求就会减少)。后端做了就可以防止有些懂技术的人绕过前端进行攻击。
前端
前端可以通过禁用按钮,定时任务等方式防止重复提交。后端
后端可以在Filter或AOP进入方法前做拦截,判断是否重复提交,如重复提交,拦截即可。判断重复提交的依据可以请求报文中的关键信息做key(如用整个请求报文的md5值做Key),当前时间戳(服务器接收到报文的时间)做value,如key不存在,说明是首次提交。如key存在,判断value(也可利用redis定时失效机制),这里不用判断value,只要key存在即说明是重复提交。
多终端Session统一
多终端Session统一有两个内容,一个是多端共享Session,另一个是多终端登录。
多端共享Session
多端共享Session指的是Web端及移动端的Session,Cookie结构完全一致。通过分布式Session(如Redis)方案来实现多端共享Session。多终端登录
多终端登录,如在手机App上登录后,只需要扫码即可登录Web端,多终端登录依赖多端共享Session的实现。
# 6.Spring
# 6.1 Spring解决了我们开发中碰到的什么问题?
Spring解决了我们在开发中碰到的一个最核心的问题,即对象之间解耦合问题。Spring通过统一管理(IoC容器)的方式配合配置文件来帮助我们管理对象之间的依赖问题,即依赖注入。
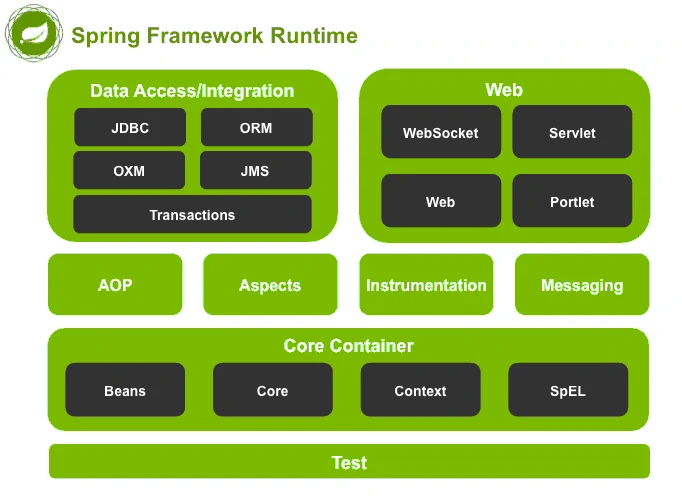
# 6.2 Spring框架结构图
# 6.3 Spring中有哪些核心组件?
Spring的核心组件都在Core Container中,他们分别是Beans,Core,Context。
# Core
装了 Spring 框架的底层部分,包括资源访问、类型转换及一些常用工具类。初学者完全可以把Core模块理解成utils工具类包。
# Beans
提供了框架的基础部分,包括控制反转和依赖注入。
# Context
建立在 Core 和 Beans 模块的基础之上,集成 Beans 模块功能并添加资源绑定、数据验证、国际化、Java EE 支持、容器生命周期、事件传播等。ApplicationContext 接口是上下文模块的焦点。它实际上是给Spring提供一个运行时的环境,用以保存各个对象的状态。
# 6.4 Bean组件
Bean组件在Spring的org.springframework.beans包下。在这个包的所有类主要做了三件事:Bean定义,Bean解析,Bean创建。对Spring的使用者来说唯一需要关心的是Bean的创建,其他两个由Spring在内部帮你完成,对你来说是透明的。
# Bean定义
Bean定义主要由BeanDefinition描述,一个BeanDefintion对象完整的描述了你在Bean的配置文件中<bean></bean>节点中所有的信息,包括各种子节点。
# Bean的解析
Bean的解析过程非常复杂,功能被分的很细,因为这里需要被扩展的地方很多,必须保证有足够的灵活性,以应对可能的变化。xml形式的bean配置的Bean的解析主要由XmlBeanDefinitionReader类来实现。它将xml的bean标签映射为BeanDefintion类的实例对象。
# Bean创建
Bean的创建是典型的工厂模式,它的顶级接口是BeanFactory,BeanFactory有3个子类,子类也同样是接口,分别是ListableBeanFactory(表示这些Bean是可列表的),HierarchicalBeanFactory(表示Bean是有继承关系的,也就是说每个Bean都有可能有父Bean)和AutowireCapableBeanFactory(定义Bean的自动装配规则)。这4个接口共同定义了Bean的集合,Bean之间的关系和Bean的行为。
# 6.5 Context组件
ApplicationContext接口是Context的顶级父类,它继承了BeanFactory接口,这也说明Spring容器中运行的主体是Bean。另外ApplicationContext继承了ResourceLoader(资源加载器)接口。使得ApplicationContext可以访问到任何的外部资源(如xml,.java文件,url网络资源等)。
总体来说,ApplicationContext主要完成以下几件事情:
- 标识一个应用环境
- 利用BeanFactory创建bean对象
- 保存对象关系表
- 能捕获各种事件
ApplicationContext的子类主要包含两个方面:
1.ConfigurableApplicationContext表示该Context是可配置的,也就是在构建Context过程中,用户可以动态添加或修改已有的配置信息,它下面有多个子类,其中最经常使用的是可更新的Context,即AbstractRefreshableApplicationContext类。
2.WebApplicationContext:顾名思义就是为Web准备的Context,它可以直接访问ServletContext,在通常情况下,这个接口使用的很少。
# 6.6 Core组件
Core组件作为Spring的核心组件,其中包含了很多的关键类,一个重要的组成部分就是定义了资源的访问方式。这种把所有资源都抽象成一个接口的方式很值得在以后的设计中拿来学习。
Resource接口封装了各种可能的资源类型,它继承了InputStreamSource接口,这样所有的资源都通过InputStream类来获取。对于资源的加载来说使用ResourceLoader接口来进行加载,只需要实现这个接口即可加载所有的资源,它的默认实现类是DefaultResourceLoader。
# 6.7 有哪些方式可以实现AOP
1.很蠢但没人这么干的方式:如果我通过遍历项目里的.java文件,在特定类的特定方法前后加上一两行代码,这是不是也可以称为AOP(横向增强)呢。
2.在源码编译为字节码的过程中增强:我们熟悉的lombok插件就是在Java源码编译过程中暴露出去的钩子函数中做了增强,为我们增加了源码后再让Java去编译来实现的增强。
3.字节码增强:在源码变成后的.class文件中写入我们的代码的字节码,cglib就是这样做AOP的。
4.动态代理:Spring主要的AOP实现方式就是动态代理。
# Spring如何实现AOP
Spring中有两种方式实现AOP,分别是CGLIB以及动态代理,动态代理需要类可继承,如类不可继承,会使用CGLIB字节码增强来实现AOP。
# 7.SpringMVC
SpringMVC工作原理 (opens new window)
spring-mvc原理分析 (opens new window)
# 8.Mybatis
# 8.1 Mybatis是什么?它主要做什么事情?
Mybatis是一个O/R Mappring(对象关系映射)框架,它主要做如下工作:
1.根据JDBC规范建立与数据库的链接,对事务操作进行封装。
2.将SQL语句封装成Statement对象。
3.将Java对象映射为SQL语句的请求参数,执行SQL语句。
4.将SQL语句的返回结果映射为Java对象。
# 8.2 Mybatis的工作原理以及核心流程详解
MyBatis的工作原理如下图所示:
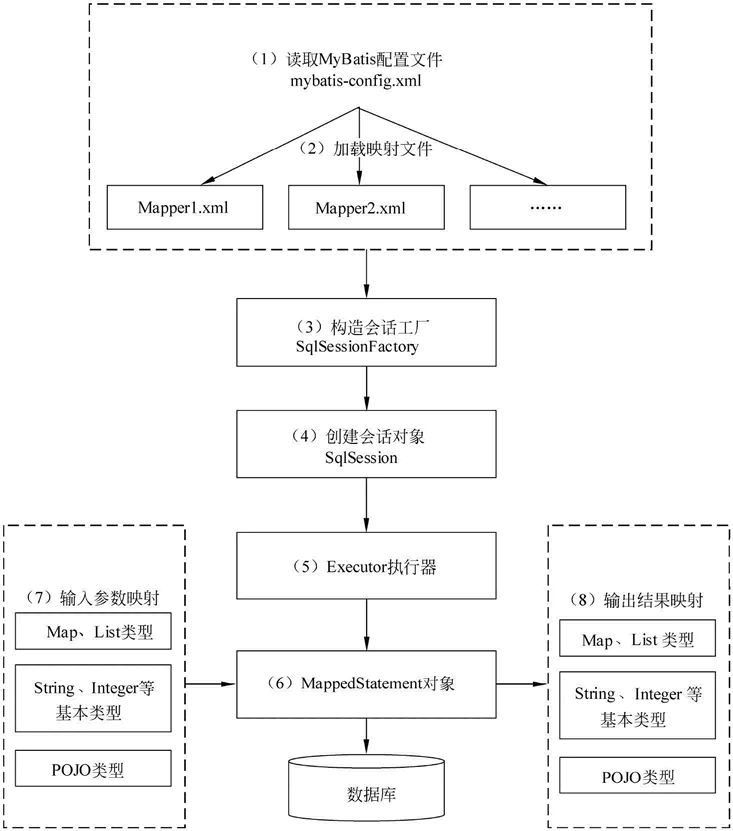
上面中流程就是MyBatis内部核心流程,每一步流程的详细说明如下文所述:
1.读取MyBatis的配置文件。mybatis-config.xml为MyBatis的全局配置文件,用于配置数据库连接信息。
2.加载映射文件。映射文件即SQL映射文件,该文件中配置了操作数据库的SQL语句,需要在MyBatis配置文件mybatis-config.xml中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
3.构造会话工厂。通过MyBatis的环境配置信息构建会话工厂SqlSessionFactory。
4.创建会话对象。由会话工厂创建SqlSession对象,该对象中包含了执行SQL语句的所有方法。
5.Executor执行器。MyBatis底层定义了一个Executor接口来操作数据库,它将根据SqlSession传递的参数动态地生成需要执行的SQL语句,同时负责查询缓存的维护。
6.MappedStatement对象。在Executor接口的执行方法中有一个MappedStatement类型的参数,该参数是对映射信息的封装,用于存储要映射的SQL语句的id、参数等信息。
7.输入参数映射。输入参数类型可以是Map、List等集合类型,也可以是基本数据类型和POJO类型。输入参数映射过程类似于JDBC对preparedStatement对象设置参数的过程。
8.输出结果映射。输出结果类型可以是Map、List等集合类型,也可以是基本数据类型和POJO类型。输出结果映射过程类似于JDBC对结果集的解析过程。
# 8.3 SpringBoot整合MyBatis及Druid数据库连接池
SpringBoot整合MyBatis及Druid的思路其实分为两步,第一步是将Druid作为dataSource数据源添加到SpringBoot中,这一步没有太多值得赘述的点,第二步则是将SpringBoot和Mybatis的整合,只是在整合过程中将MyBatis的sqlSessionFactory作为bean对象添加到Spring容器的过程中顺手将Druid作为dataSource添加到sqlSessionFactory的构造器。
SpringBoot整合MyBatis核心代码
/**
*
* MyBatis在创建sqlSessionFactory的时候需要提供数据源,druid数据库连接池就是一个实现了DatsSource接口的数据源,因此将druid注入设置进来即可。
*/
@Configuration
public class MyBatisConfig {
@Bean
public SqlSessionFactory sqlSessionFactory(DataSource dataSource) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource);
// 设置mapper文件位置
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
sqlSessionFactoryBean.setMapperLocations(resolver.getResources("classpath:/mapper/*.xml"));
return sqlSessionFactoryBean.getObject();
}
@Bean
public DataSourceTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
}