# 微服务面试总结
# 高并发
# 什么是高并发?
这里以淘宝的公开数据来说明什么是高并发。根据公开数据显示,2019年双11期间,淘宝的峰值并发达到了25.4万次/秒,在整个双11期间共处理了2135亿次请求。这表明淘宝系统可以同时承载数百万甚至上千万级别的用户访问。
这里的数据是国内最top的顶级电商平台,考虑到其他系统完全达不到这个体量,我们有理由相信,2.5万次/秒的并发就可以理解为高并发了。
# 高并发靠的是什么?
Web服务器与数据库分离,引入本地缓存和分布式缓存,引入反向代理实现负载均衡,数据库读写分离,LVS/F5硬件负载,高并发靠这些能实现吗?能,但治标不治本。即使这些你全部都做的很完美,依然不能实现taobao级别的高并发,在我看来taobao之所以能支持亿级请求,25.4万次/秒的并发,问题的关键还在于DNS解析的负载均衡以及以F5为代表的硬件负载均衡器的使用。
参考淘宝亿级高并发分布式架构演进之路 (opens new window)
# 一般应用如何实现高并发架构?
个人感觉现在大部分应用不可能达到taobao的体量,充其量是在单体应用过渡到多个单体应用负载均衡的阶段,即一个单体应用不满足业务场景,多个单体应用就可以满足业务场景的情况,这个阶段的架构,我们只需要引入nginx做负载均衡就可以解决问题。

# 同样是web服务器,为什么一个nginx可以负载多个tomcat?
根据上面的架构图,我们就可以看出来,一台nginx下面部署了多台tomcat,为什么呢,毕竟本质上tomcat和nginx都是web服务器嘛,按理说tomcat的瓶颈也会是nginx的瓶颈。这里简单解释下,nginx底层基于io多路复用的epoll模型,且使用的是边缘触发的方式实现。而tomcat所依赖的java虽然底层使用的也是epoll模型,但是使用的方式是水平触发。 所以理论上来说nginx的最大并发数就是会比tomcat要高,这也是一台nginx可以负载多台tomcat的根本原因(可以理解成nginx把操作系统的性能发挥到极限了,毕竟本质上web的并发还是靠操作系统来确定上限的)。
# 单机环境nginx以及tomcat的并发上限是多少?
理论上单机nginx可以支持的并发上限是50000,而linux环境下tomcat的并发上限是1000。可以看到这两个web服务器的数据差异还是很大的。也就是说理论上支撑taobao这种顶级电商平台的并发业务,只需要能负载到5个机房的CDN负载均衡加5台Nginx就可以实现了。nginx最大并发,理论值 (opens new window)
# 分布式事务-seata
通过seata at模式实现分布式事务。
# TC事务协调者
tc事务协调者对应一个web服务,这里我们使用的tc是seata-server-1.4.2,找到项目的bin目录,双击执行seata-server.bat脚本即可完成tc的启动。
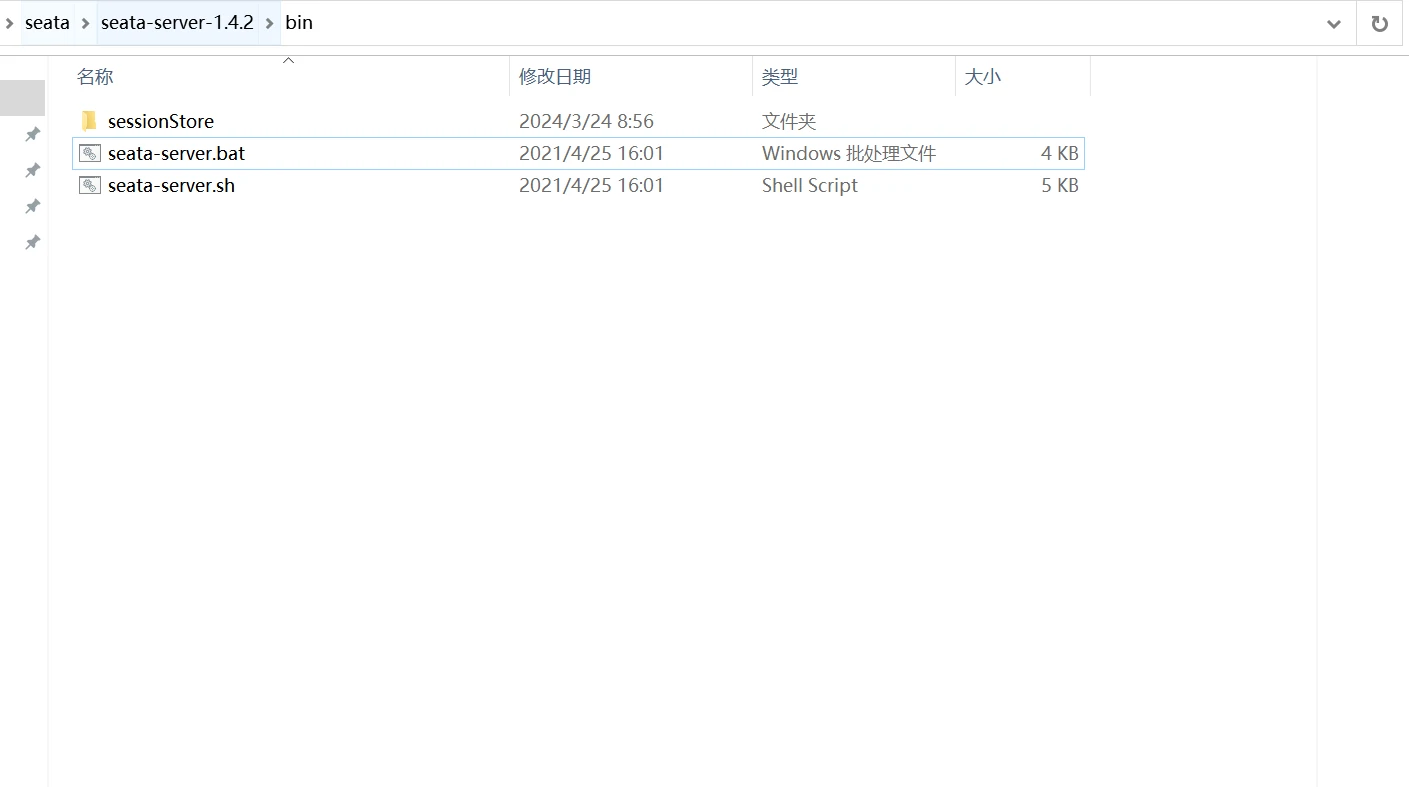
可以看到服务使用8091端口启动。
# 建库建表
在需要做分布式事务的数据库中进行相关建表语句,每个库都需要创建undo_log表。
相关建库建表语句
CREATE DATABASE `seata`;
CREATE TABLE `account_tbl`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`money` int(11) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `stock_tbl`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `commodity_code` (`commodity_code`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `order_tbl`
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(255) DEFAULT NULL,
`commodity_code` varchar(255) DEFAULT NULL,
`count` int(11) DEFAULT '0',
`money` int(11) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE IF NOT EXISTS `undo_log`
(
`branch_id` BIGINT NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(128) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME(6) NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME(6) NOT NULL COMMENT 'modify datetime',
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT ='AT transaction mode undo table';
# 为undo_log表增加索引
ALTER TABLE `undo_log` ADD INDEX `ix_log_created` (`log_created`);
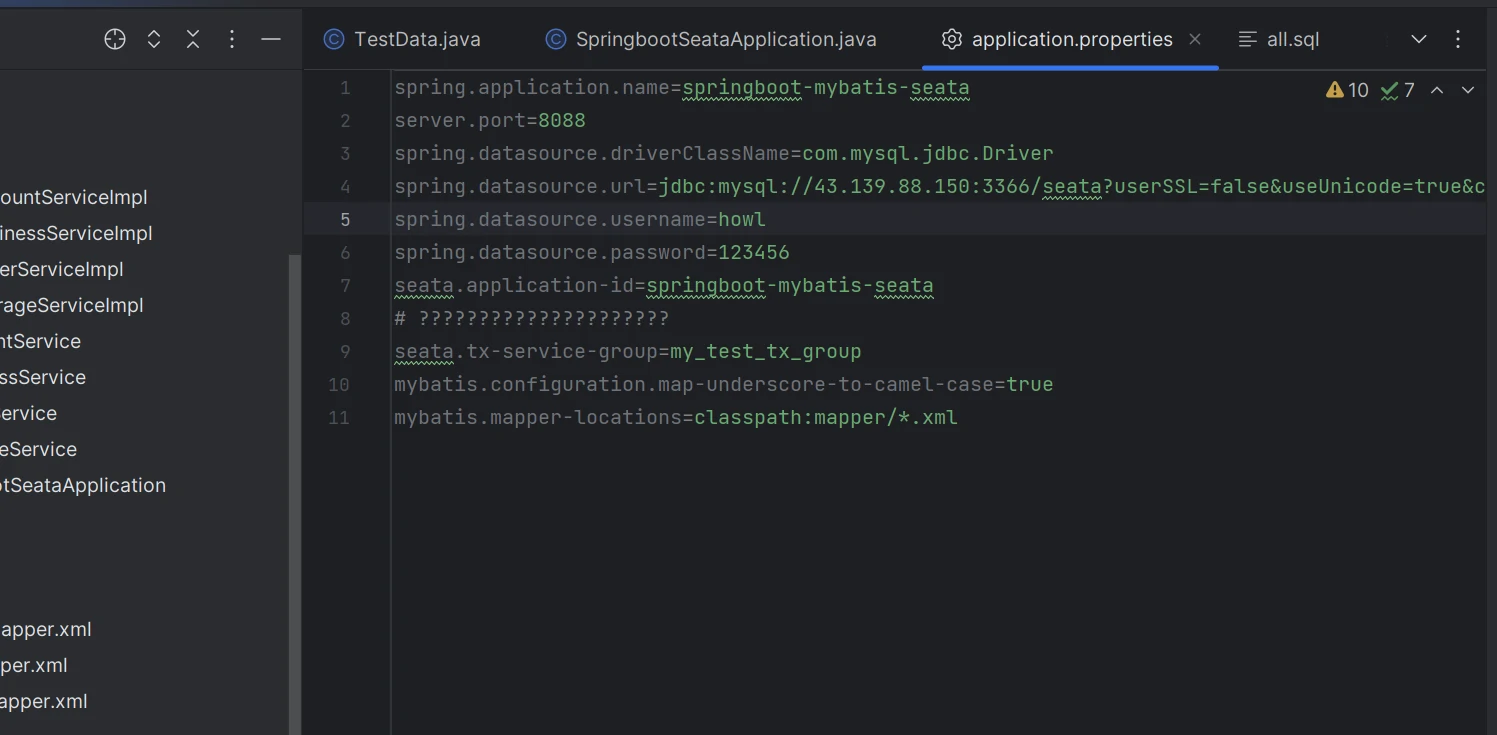
# 修改datasource配置文件
将项目的application.properties配置文件中的datasource修改为我们实际运行的数据库。
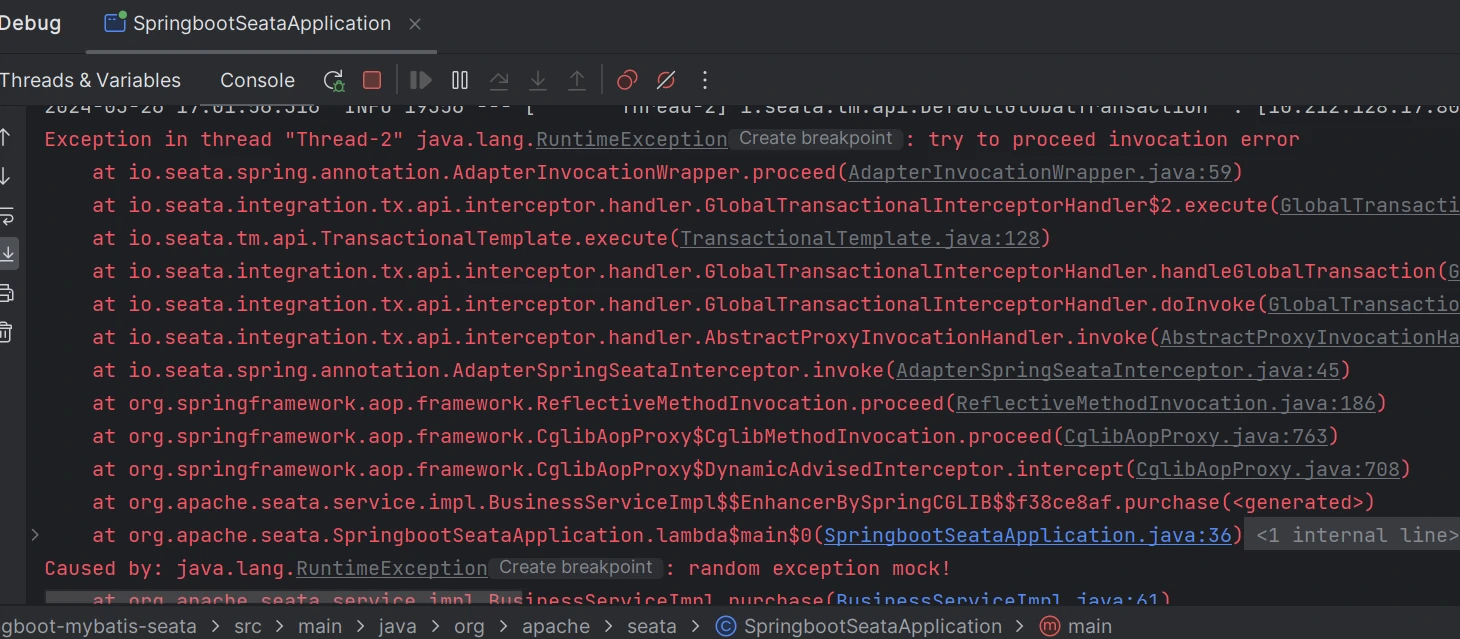
# 验证分布式事务
运行项目验证分布式事务,如相关服务执行无异常,代码正常提交,如任意服务异常,事务回滚。
# 事务提交
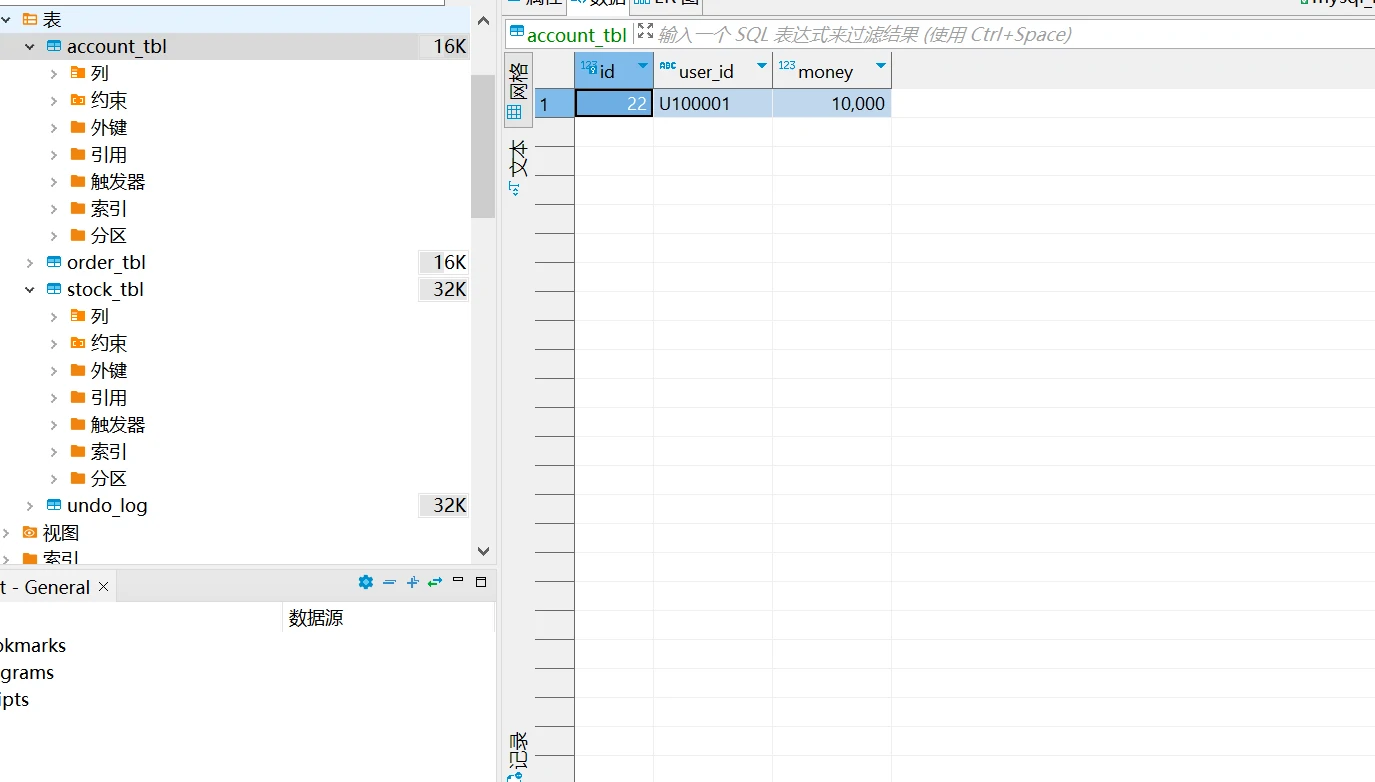
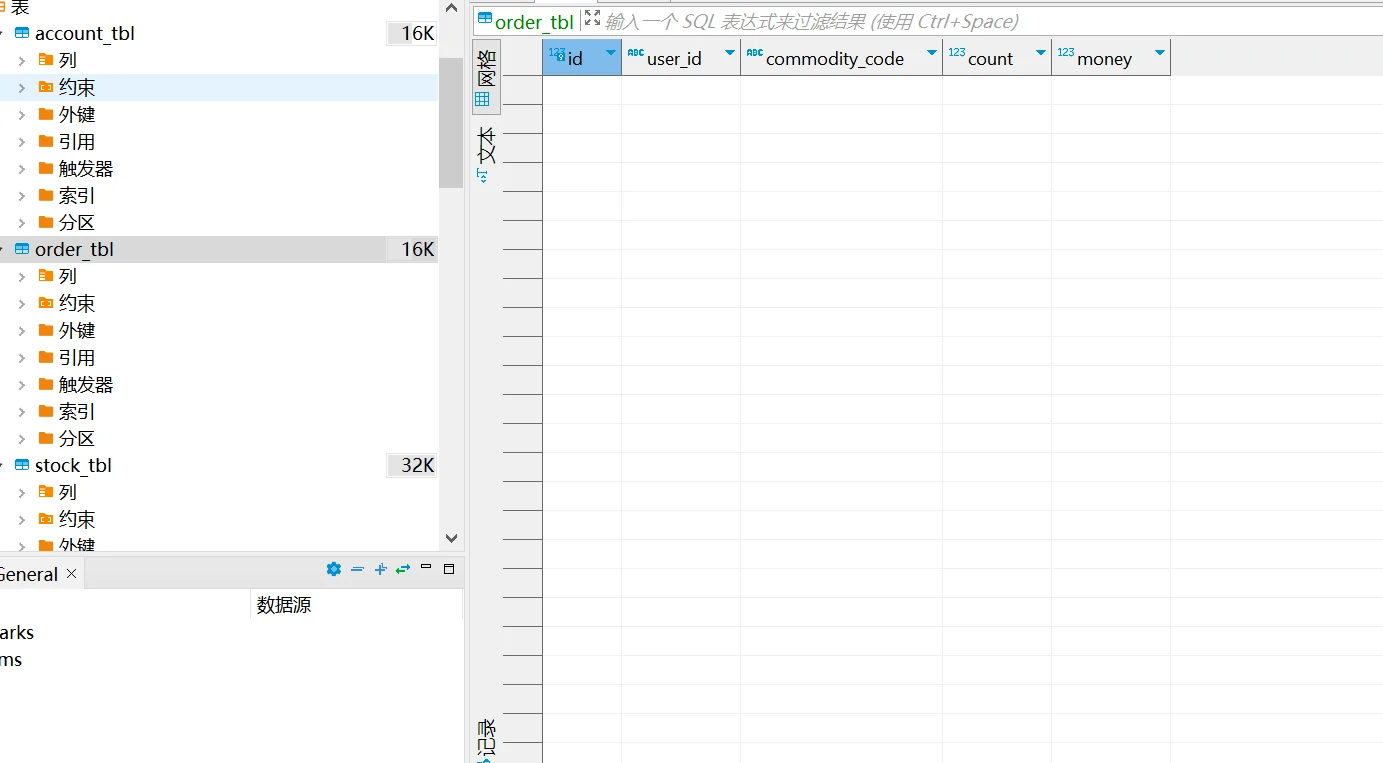
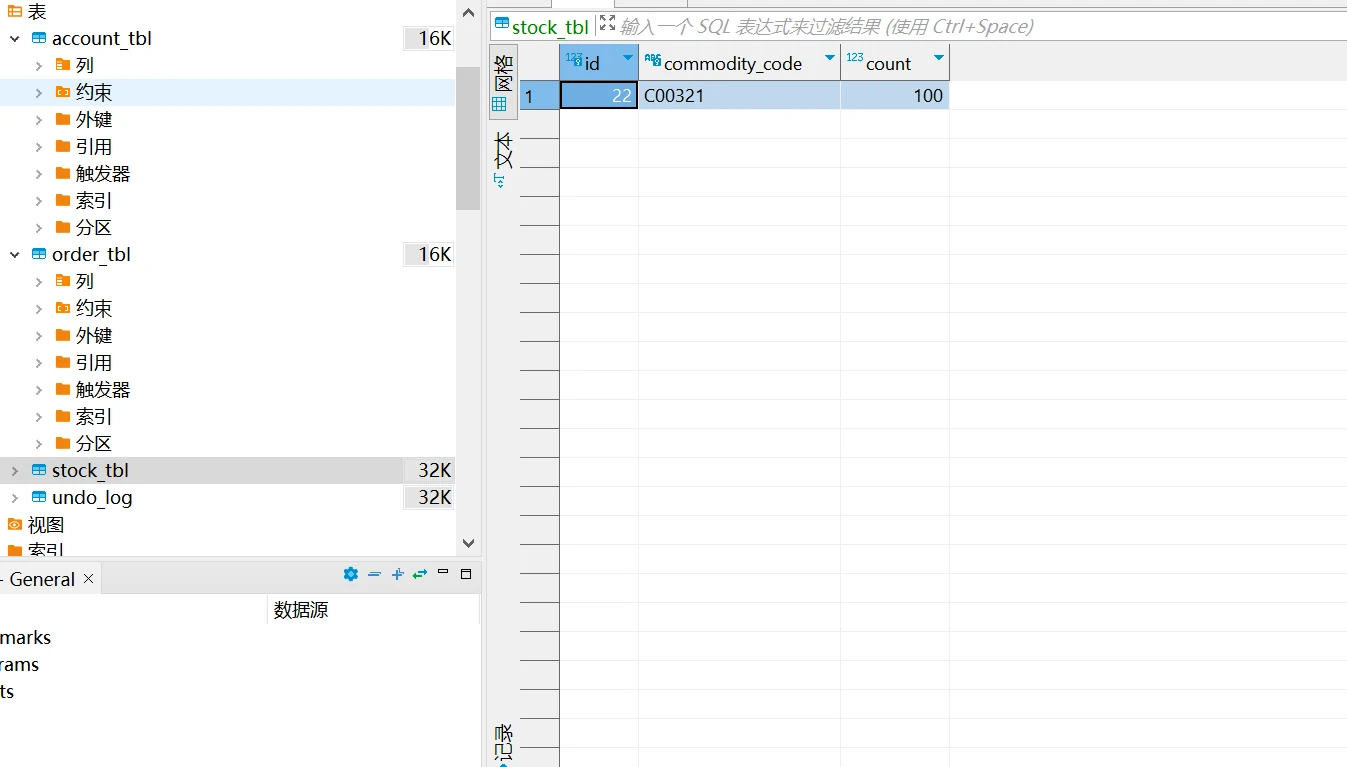
事务提交成功,订单服务,账户服务,库存服务对应的库表数据同步提交。
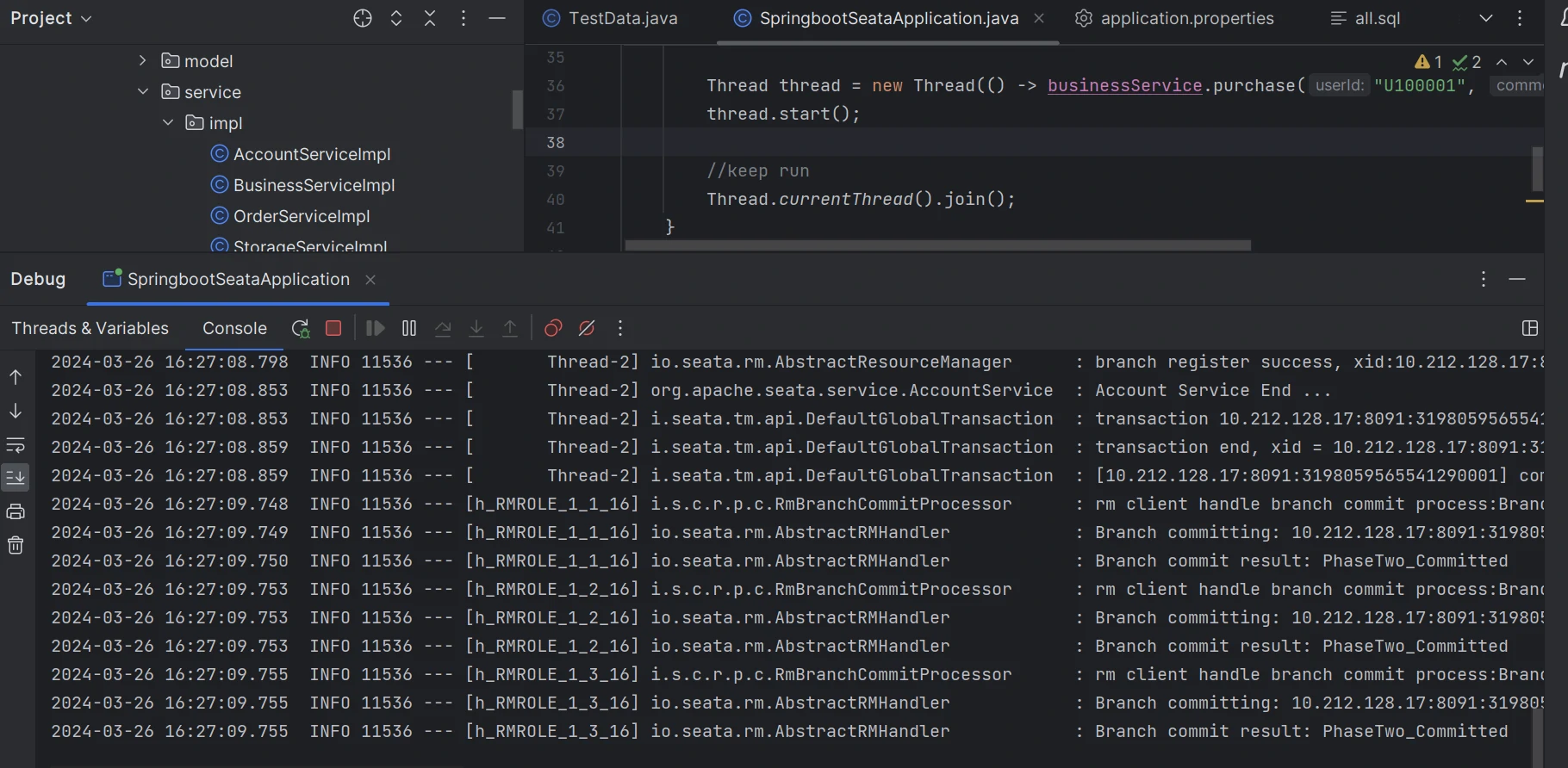
账户表金额减少(由10000减少为400)。
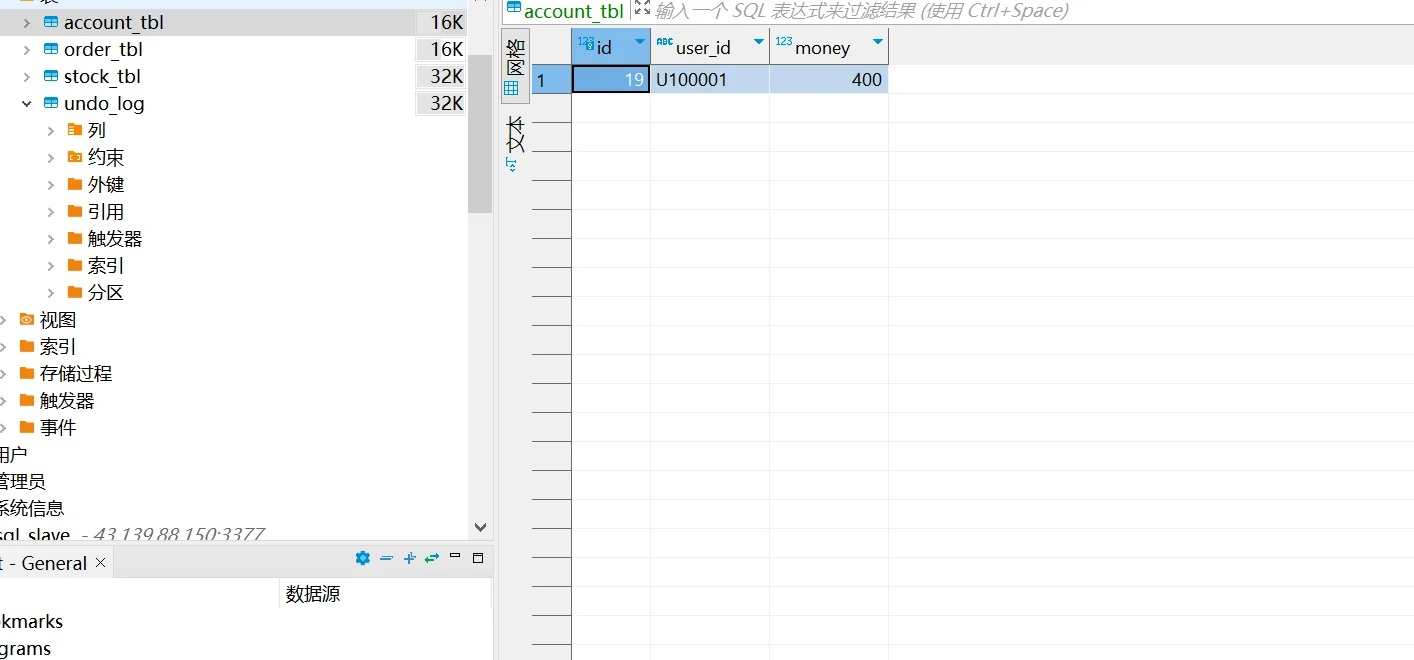
库存表库存减少(由100减少为98)。
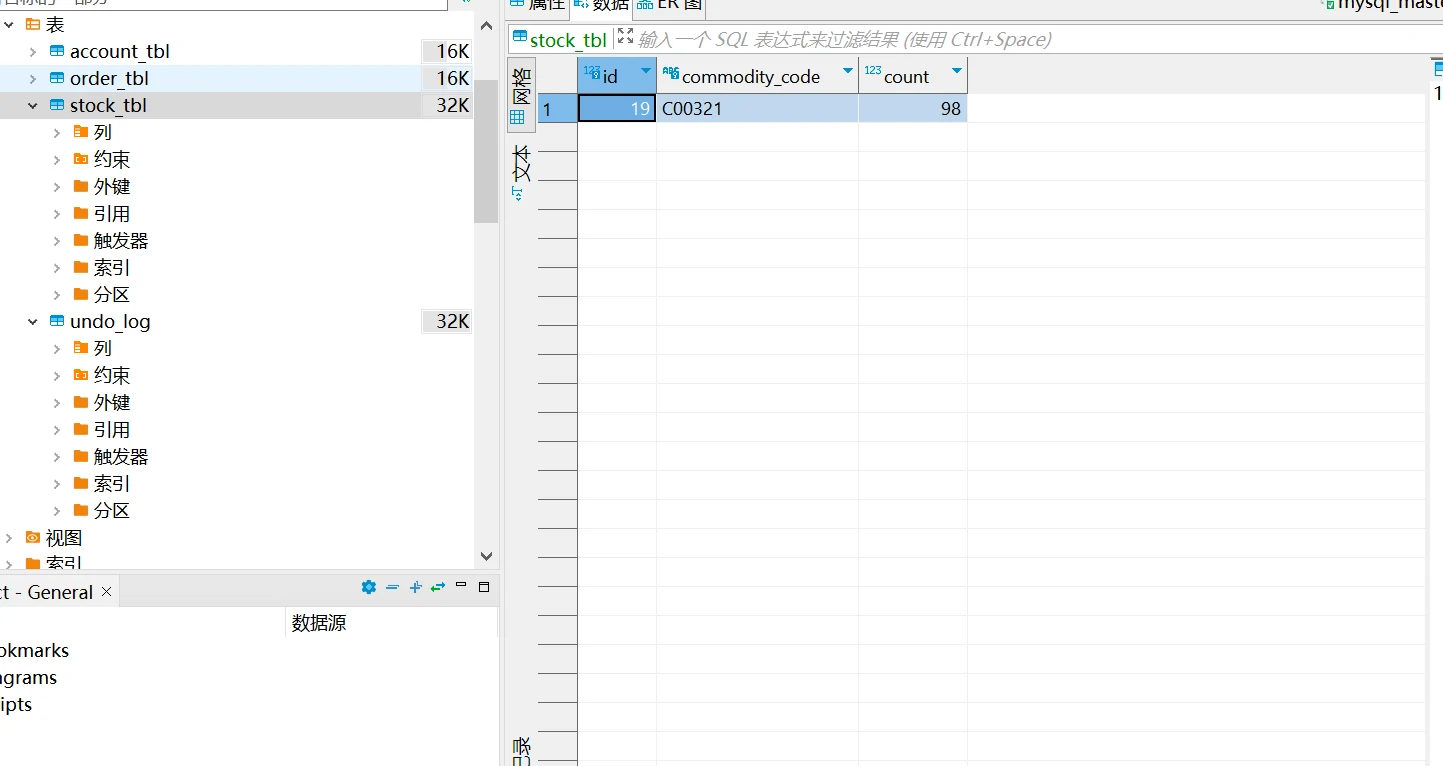
订单表生成对应订单。
# 事务回滚
事务提交失败,订单服务,账户服务,库存服务对应的库表数据回滚。
# 完整项目地址
seata分布式事务demo (opens new window)
# 水平分库分表
要想实现数据库的水平分库,水平分表,读写分离功能,需要同时改造MySQL数据库以及Java项目,MySQL数据库需要实现主从复制(基于docker搭建mysql主从集群),读写分离(对mysql主从集群做读写分离)功能。而Java项目也需要改造,对于读写分离,需要代码层面判断是读操作还是写操作,对于不同的操作,使用不同的数据库。而对于水平分库分表,则需要人为判断数据需要在哪个库哪个表读写。
# ShardingJDBC介绍
ShardingJDBC是由当当网开源的一个轻量级的数据库分库分表,读写分离框架。利用该框架,我们可以很轻松的实现分布式系统的水平分库,水平分表,读写分离功能。
# SpringBoot+ShardingJDBC实现水平分库分表,读写分离
# 前期准备
我们以一个主从同步,读写分离架构的Mysql服务集群来演示ShardingJDBC的水平分库,水平分表,读写分离功能,因此需要预先搭建一个MySQL一主一从的服务集群,参见基于docker搭建mysql主从集群,对mysql主从集群做读写分离。
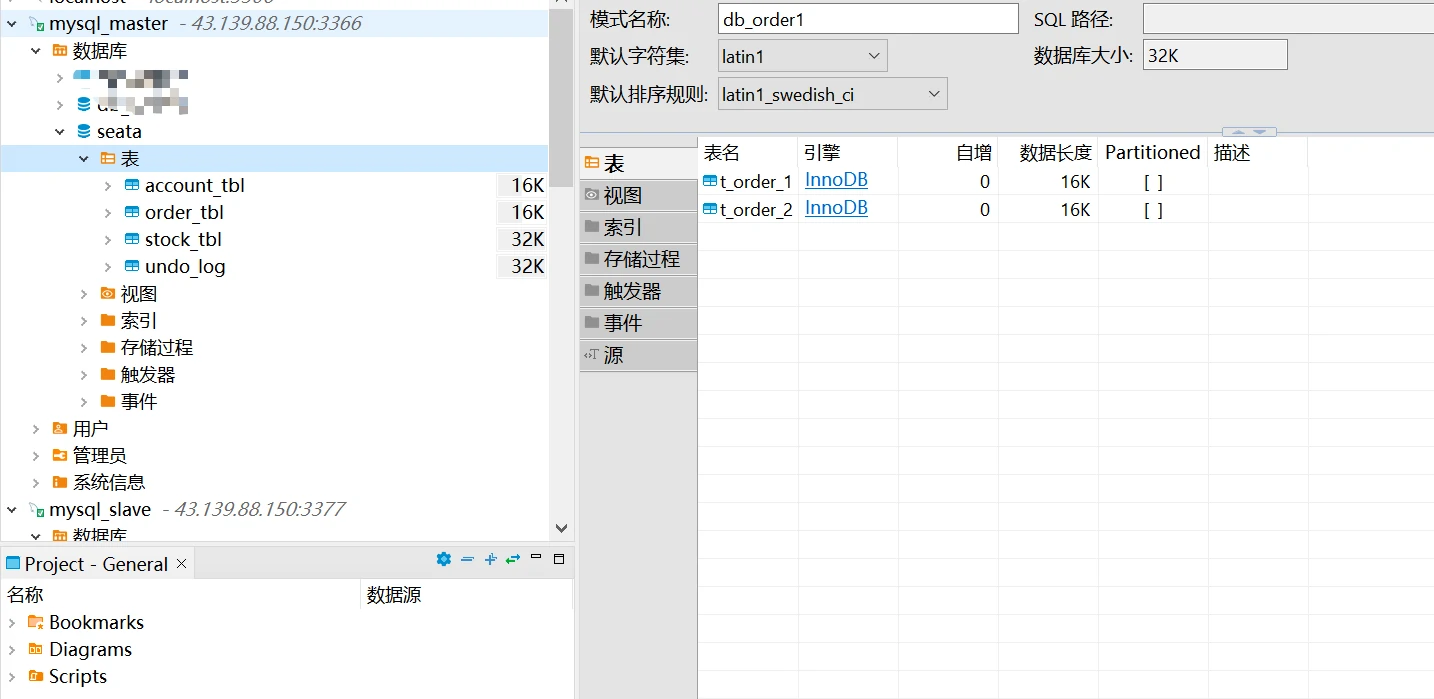
# 建库建表
在Mysql主节点上创建水平分库db_order1以及db_order2,在db_oder1以及db_order2中分别创建t_order_1以及t_order2。可以在从节点看到相同的库表同步到了从节点。

相关建库建表语句
CREATE DATABASE `db_order1`;
CREATE DATABASE `db_order2`;
-- db_order1.t_order_1 definition
CREATE TABLE `t_order_1` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10,2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
-- db_order1.t_order_2 definition
CREATE TABLE `t_order_2` (
`order_id` bigint(20) NOT NULL COMMENT '订单id',
`price` decimal(10,2) NOT NULL COMMENT '订单价格',
`user_id` bigint(20) NOT NULL COMMENT '下单用户id',
`status` varchar(50) NOT NULL COMMENT '订单状态',
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC;
# Java服务创建
需要创建springboot项目,引入shardingjdbc相关依赖,同时提供分库分表配置,在业务代码里实现分库分表操作(项目运行在jdk8+mysql5.7环境)。
# 依赖pom文件
在pom依赖文件里,我们需要引入springboot,mybatis,druid,mysql-connector,lombok依赖。
完整pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.3.RELEASE</version>
</parent>
<groupId>com.howl</groupId>
<artifactId>sharding-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>sharding-jdbc</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.0.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.26</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.16</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.10</version>
</dependency>
</dependencies>
<repositories>
<repository>
<id>Central Repository</id>
<url>https://repo1.maven.org/maven2/</url>
</repository>
</repositories>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
# 配置文件修改
在配置文件里,我们需要配置shardingsphere数据源,读写分离策略,水平分库策略,水平分表策略,分布式主键生成策略。
application.yml
server:
port: 8082
spring:
application:
name: sharding-jdbc-simple-demo
main:
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: m1,m2,s1,s2
m1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://43.139.88.150:3366/db_order1?useUnicode=true&useSSL=false
username: howl
password: 123456
m2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://43.139.88.150:3366/db_order2?useUnicode=true&useSSL=false
username: howl
password: 123456
s1:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://43.139.88.150:3377/db_order1?useUnicode=true&useSSL=false
username: howl
password: 123456
s2:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://43.139.88.150:3377/db_order2?useUnicode=true&useSSL=false
username: howl
password: 123456
sharding:
master-slave-rules:
ds1:
master-data-source-name: m1
slave-data-source-names: s1
ds2:
master-data-source-name: m2
slave-data-source-names: s2
tables:
t_order:
actualDataNodes: ds$->{1..2}.t_order_$->{1..2}
databaseStrategy:
inline:
shardingColumn: user_id
algorithm‐expression: m$->{user_id % 2 + 1}
tableStrategy:
inline:
shardingColumn: order_id
algorithmExpression: t_order_$->{order_id % 2 + 1}
keyGenerator:
type: SNOWFLAKE
column: order_id
props:
sql:
show: true
mybatis:
configuration:
map-underscore-to-camel-case: true
logging:
level:
root: info
org.springframework.web: info
com.itheima.dbsharding: debug
druid.sql: debug
# 项目代码编写-Application入口
在应用入口,我们只需要使用@SpringBootApplication注解标记入口类即可。
应用入口
package com.dyh.shardingJdbc;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author howl-xu
* @version 1.0
* Create by 2024/3/22
*/
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
# 项目代码编写-Controller层代码编写
因为是demo项目,我们直接跳过service层,直接在controller层访问Mapper层。
controller层代码
package com.dyh.shardingJdbc.controller;
import com.dyh.shardingJdbc.entity.Order;
import com.dyh.shardingJdbc.entity.dto.InsertOrderDto;
import com.dyh.shardingJdbc.mapper.OrderMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.List;
import java.util.Map;
/**
* @author howl-xu
* @version 1.0
* Create by 2024/3/22
*/
@Slf4j
@RestController
@RequestMapping("/v1/sharding/")
public class OrderController {
@Resource
private OrderMapper orderMapper;
@PostMapping("/insert")
public void insertOrder(@RequestBody InsertOrderDto dto) {
orderMapper.insertOrder(dto.getPrice(),dto.getUserId(),dto.getStatus());
}
@PostMapping("/select")
public List<Order> selectOrder() {
List<Order> list = orderMapper.selectOrderbyIds();
return list;
}
}
# 项目代码编写-mapper及entity
mapper及entity的代码可以参考详情。
mapper及entity
package com.dyh.shardingJdbc.mapper;
import com.dyh.shardingJdbc.entity.Order;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Component;
import java.math.BigDecimal;
import java.util.List;
import java.util.Map;
/**
* 订单Mapper接口
*
* @author howl-xu
* @since 2024/3/22
**/
@Mapper
@Component
public interface OrderMapper {
/**
* 新增订单
*
* @param price 订单价格
* @param userId 用户id
* @param status 订单状态
* @return
*/
@Insert("insert into t_order(price,user_id,status) value(#{price},#{userId},#{status})")
int insertOrder(@Param("price") Double price, @Param("userId") Long userId,
@Param("status") String status);
/**
* 根据id列表查询多个订单
*
* @return
*/
@Select("select * from t_order")
List<Order> selectOrderbyIds();
}
package com.dyh.shardingJdbc.entity;
import java.math.BigDecimal;
import java.io.Serializable;
import lombok.Data;
import lombok.EqualsAndHashCode;
/**
* <p>
*
* </p>
*
* @author howl-xu
* @since 2024-03-22
*/
@Data
@EqualsAndHashCode(callSuper = false)
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
private Long orderId;
/**
* 订单价格
*/
private BigDecimal price;
/**
* 下单用户id
*/
private Long userId;
/**
* 订单状态
*/
private String status;
}
# 验证水平分库分表
测试demo的水平分库策略是根据用户的id做分库,如用户id为偶数,则分配到db_order1库中,如用户id为奇数,则分配到db_order2中。
测试demo的水平分表策略是根据order_id进行分表,订单id使用雪花算法生成,如订单id是偶数,则分配到t_order_1表,如是奇数,则分配到t_order_2表中。
我们使用一个用户id为偶数的用户做订单创建操作,如下:

查找数据库,这次雪花算法生成的id是一个奇数,数据写入到了db_order_1库的t_order_2表中。

# 验证读写分离
对创建的订单信息进行查询,如下:
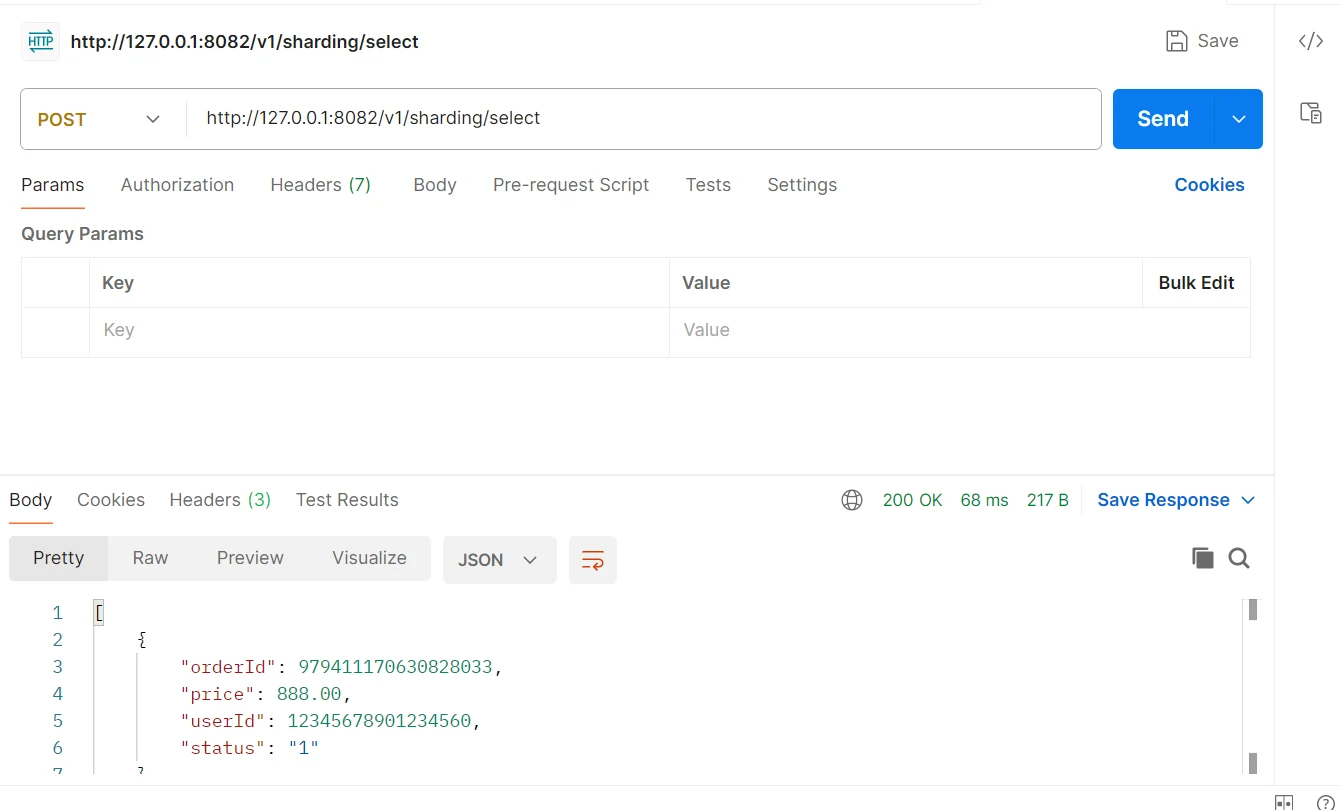
可以在项目的日志中看到,此时查询操作查询了s1,s2两个数据库的t_order_1以及t_order_2表。
# 完整项目地址
水平分库分表读写分离项目demo (opens new window)
# 缓存穿透,缓存击穿,缓存雪崩分别指什么?
# 缓存穿透
就像水分子能穿透滤纸一样,根本原因在于水分子的直径比滤纸的孔洞要小,因此水分子就能穿透滤纸。对应到缓存也一样,如果请求一个缓存中不存在的数据,自然就会查询数据库了,如果数据库中也不存在,自然也不会缓存数据。如果短时间找到大量数据库不存在的数据请求业务系统,业务系统的性能就会直线下降,这个问题我们将其描述为“缓存穿透”。针对缓存穿透,我们可以使用前置布隆过滤器,只要布隆过滤器识别不存在的数据,那么缓存和持久化库中均不包含。当然布隆过滤器识别到存在的数据,在持久层也不一定存在。
# 缓存穿透是一种攻击行为
缓存穿透本质上是一种黑客攻击行为,如果系统中还未使用布隆过滤器来应对缓存穿透的攻击行为,我们可以使用临时方案紧急处理,如IP黑名单机制、缓存空对象机制临时应对这种攻击行为,在后续版本中使用布隆过滤器作为最终解决方案处理该问题。
# 缓存击穿
缓存击穿指的是一个热点缓存自然失效后,大量的并发请求同时请求数据库,数据库针对每个请求都执行查库,写缓存,返回数据的代码逻辑。需要明确的是,缓存击穿并不是攻击行为,而是自然的业务行为,一个热点数据自然是因为请求的多才做缓存,也因为请求的多,所以缓存失效才会有大量请求并发访问。
# 缓存击穿的处理方案?
针对缓存击穿,我们可以使用如下两种解决方案:
- 设置缓存永不过期
热点缓存不存在过期时间,如果热点缓存的数据有变更,需要在代码层面处理缓存和数据库数据一致性问题。 - 允许缓存正常失效,但是在缓存失效查询数据库表之前使用分布式锁方案
当第一个请求发现缓存失效时,它并不立即去查数据库,而是先尝试获取一个分布式锁(比如用Redis的 SETNX 命令)。获取到锁的请求才有资格去查询数据库并回填缓存。在此期间,其他请求要么等待,要么直接返回默认值/旧数据。
# 缓存雪崩
缓存雪崩指的是缓存不可用,一般出现这种情况要么是Redis宕机,要么是大量缓存数据同时过期(这个可以给不同缓存设置不同过期时间来规避),针对每一个缓存,我们可以使用缓存击穿的思路对缓存业务做分布式锁。针对Redis宕机这种情况,我们可以通过集群保证Redis不宕机,也可以对业务做限流熔断来避免业务崩溃。
# 缓存雪崩如何处理?
简单思路就是把缓存雪崩拆解为缓存击穿,也就是错开缓存的过期时间,避免大量缓存同时失效,针对每一个缓存,使用分布式锁方案处理缓存击穿行为。
# 布隆过滤器相关
# 由缓存穿透讲起
布隆过滤器的主要使用场景是缓存穿透,而缓存穿透则是一种网络安全层面的攻击行为,它指的是攻击者对特定业务接口的调用,根据请求参数无法在缓存中找到数据,且无法在数据库中找到数据。如果攻击者使用大量的“肉鸡”大批量的请求业务系统,业务系统的数据库很容易因为这种攻击行为导致瘫痪。因此我们使用布隆过滤器这个快速失败方案来应对攻击。
# 为什么黑客不攻击没缓存的接口呢?
一个系统,不可能所有接口都加缓存,我如果是黑客,直接请求没有缓存的接口,不是更容易击穿数据库吗?攻击有缓存的接口,别人接口还加了布隆过滤器,这不是没任何意义吗?答案是黑客能获取到的接口是少数,且这些占少数的接口是核心接口。以外卖系统为例,大部分人都是普通用户,撑死了是店家。普通用户能获取到的接口无非是登录,退出登录,分页查看店家列表,分页查看某店家的餐品,下单,支付等接口。黑客最容易获取到的显然是这些业务高频接口,因此这些接口必须要加缓存,加缓存的同时也必须要加布隆过滤器。
# 布隆过滤器怎么加
- 业务代码层面,只要往需要缓存的数据库中写入了一条数据,就必须同步往布隆过滤器中添加数据。
- 针对系统迁移或者是代码bug导致布隆过滤器数据未写入的情况,通过补偿脚本全量刷数等方案向布隆过滤器中写入数据(个人觉得同步补偿定时任务机制遍历数据库和布隆过滤器做匹配,如果数据库有数据,布隆过滤器没返回就添加到布隆过滤器中)。
# 如何使用布隆过滤器
在接口查询时,首先请求布隆过滤器确认数据是否在数据库中存在,如存在,查询缓存,如果缓存存在,直接返回,如果缓存不存在,使用缓存击穿的解决方案(分布式锁)查询数据库并写入缓存。
# 是否可以不使用布隆过滤器?
如果系统不是核心系统,且接口不是核心接口,不建议使用布隆过滤器,使用布隆过滤器最大的成本在于增量/全量维护布隆过滤器,需要确保布隆过滤器和数据库的数据的一致性。一般的外围系统接口在查询时发现缓存没数据就去查库,查库查到了返回数据写入缓存并返回(缓存时间按业务规则设置),查库没查到,在缓存中存储key-value(空值)并设置过期时间(相对业务规则的缓存时间要短一个数量级,如业务数据缓存60分钟,这个缓存的缓存时间是10分钟)就已经非常可以了。
布隆过滤器的使用流程
- 使用Redis的RedisBloom作为布隆过滤器的分布式存储。
- 定期清理布隆过滤器并重建。
- 在持久层(Mysql)新增数据的时候同步将key写入布隆过滤器中。
- 在查询时首先使用布隆过滤器判断Mysql中是否包含key。
- 如果在redis里存的缓存是user:uuid,那么往布隆过滤器里添加数据的时候也是添加的user:uuid,同样的查询布隆过滤器时也是使用user:uuid查询判断数据是否在数据库存在。
# 什么是雪花算法
世界上没有两片完全相同的雪花,这主要是由于雪花形成过程中的复杂性和多样性所导致的。雪花算法用雪花来命名也是一样,这个算法的核心功能是解决应用系统在分布式场景下希望可以获取全局(全球)唯一id的诉求,如水平分库的情况下,针对不同水平库下相同表的主键的id唯一的诉求。
# 如何确保唯一性
和我们在java中通过域名唯一性来解决项目打包的包名唯一性的实现思路一致,在雪花算法实现上,我们同样可以利用机器的MAC地址(机器id),每一台主机在出场时都由硬件厂商确保机器id(机器指纹),我们如果在生成雪花算法中复用这个逻辑,就能确保生成的id的某一部分唯一。
然而实际我的理解是错的,机器id和雪花算法没什么关联性。
# 雪花算法的构成
# 固定位的0
雪花算法的第一位是由固定位置的0(整数的标志位),来组成,在Java中代表正数。
# 41位的时间戳
41位的时间戳(当前毫秒)
# 10位的工作节点ID
由具体的公司的业务系统自己划分,一般前5位代表数据中心,从0到32,如我的项目香港可以用0,澳门用1,新加坡用2,后面5位表示机器id,同样的0代表第一台机器,1代表第二台机器。这部分ID必须由人工或外部系统(如配置中心、ZooKeeper)分配和管理,确保全局无冲突。
# 12位的序列号
具体负责生成雪花算法的主机生成的序列,每秒可以生成4096个,对应12位的0到4095。